RAG技术全景解析:从基础范式到下一代认知增强系统
一、RAG的核心价值:解决LLM三大硬伤
传统大模型存在三个无法根治的问题,而RAG(检索增强生成)是当前最成熟的解决方案:
1. 知识截止:模型训练完成后,无法获取后续新增信息
2. 幻觉问题:会自信地编造不存在的事实
3. 私域盲区:无法直接访问企业内网、私有数据库等内部信息
RAG的核心逻辑是: 外部知识库 → 实时检索 → 增强Prompt → 精准回答 ,把外部真实数据实时注入模型,让回答“有据可依”。
二、RAG基础架构:核心三角
基础RAG的工作流程由三部分组成:
- 用户查询(Query):用户的问题或指令
- 检索器(Retriever):从向量知识库中,召回与问题最相关的文档片段
- 生成器(LLM):把检索到的文档片段和用户问题一起作为Prompt,生成精准回答
三、RAG技术演进:四大主干分支
RAG的发展可以分为四个阶段,技术复杂度和效果同步提升:
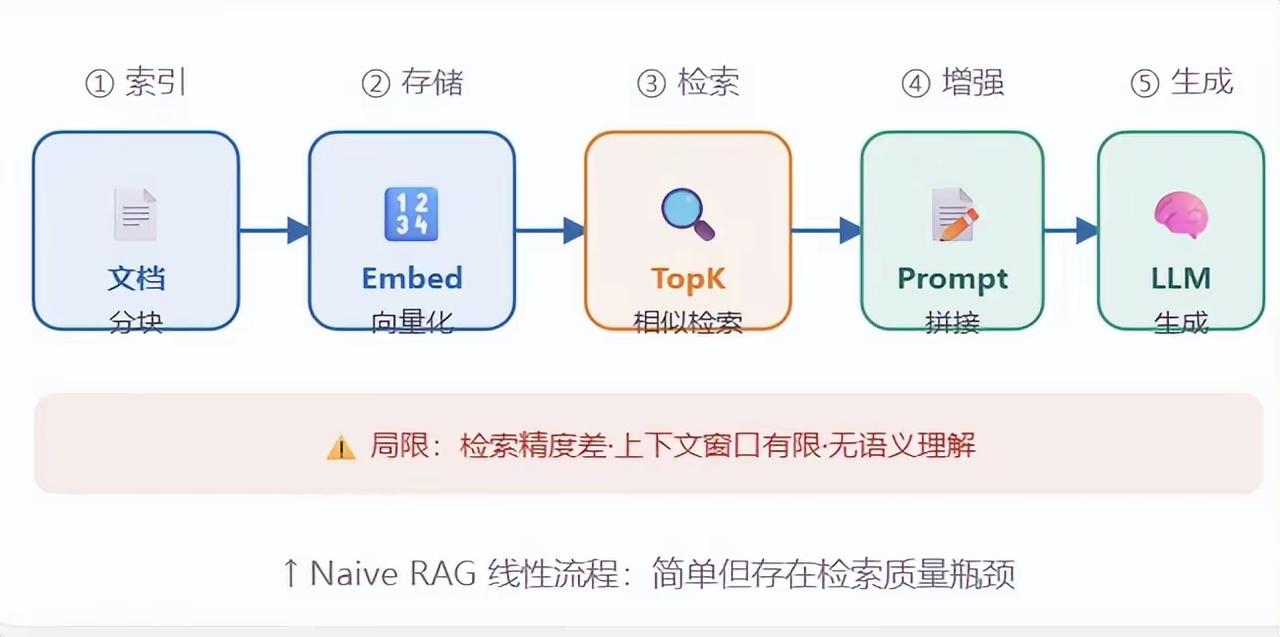
1. Naive RAG(基础版)
- 流程:文档分块 → 向量化存储 → 向量检索 → Prompt拼接 → LLM生成
- 局限:检索精度差、上下文窗口有限、无语义理解,只能处理简单问答场景
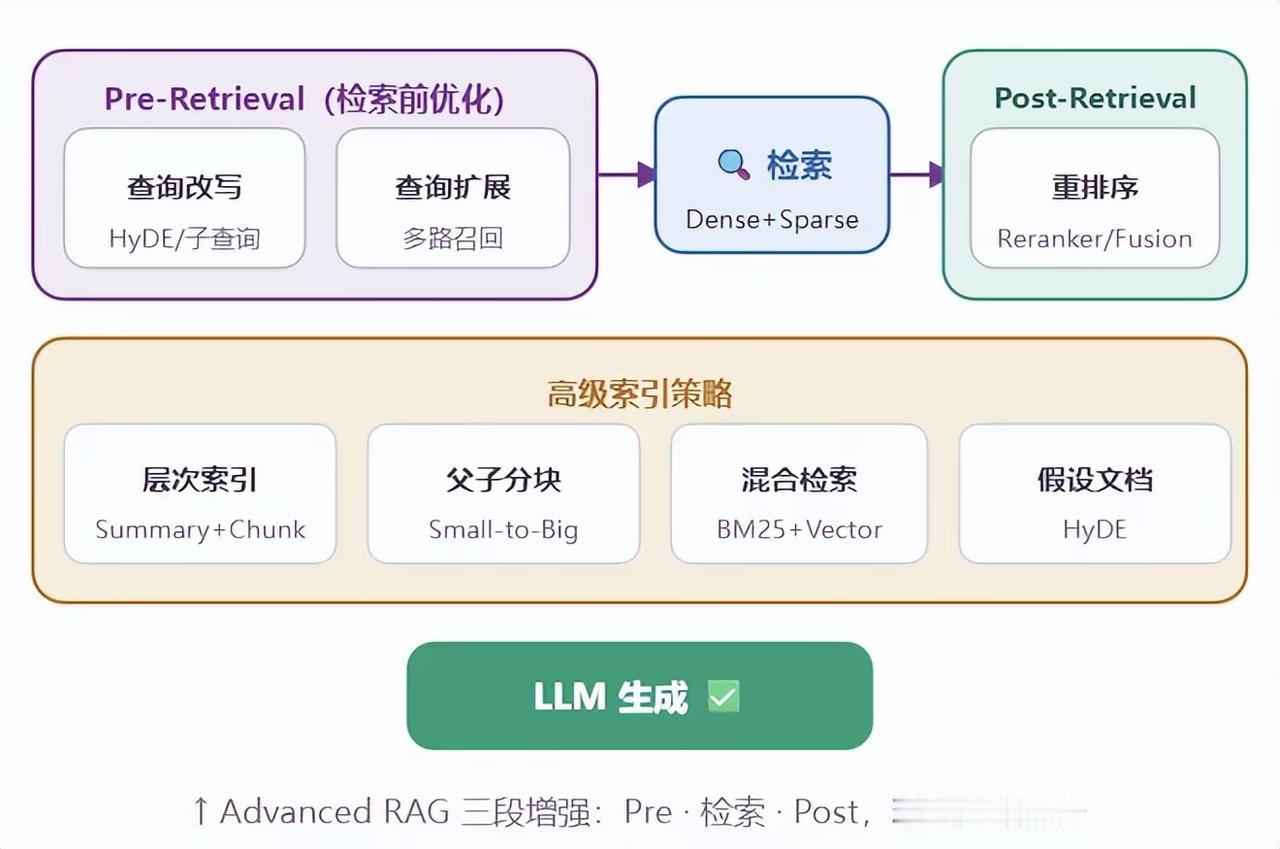
2. Advanced RAG(进阶版)
在基础流程上,加入三段式优化,大幅提升检索质量:
- Pre-Retrieval(检索前):查询改写、扩展(HyDE/子查询),优化用户问题
- Retrieval(检索中):混合检索(稠密向量+稀疏BM25),多路召回
- Post-Retrieval(检索后):重排序(Reranker/Fusion),筛选最相关文档
- 高级策略:层次索引、父子分块、假设文档(HyDE)
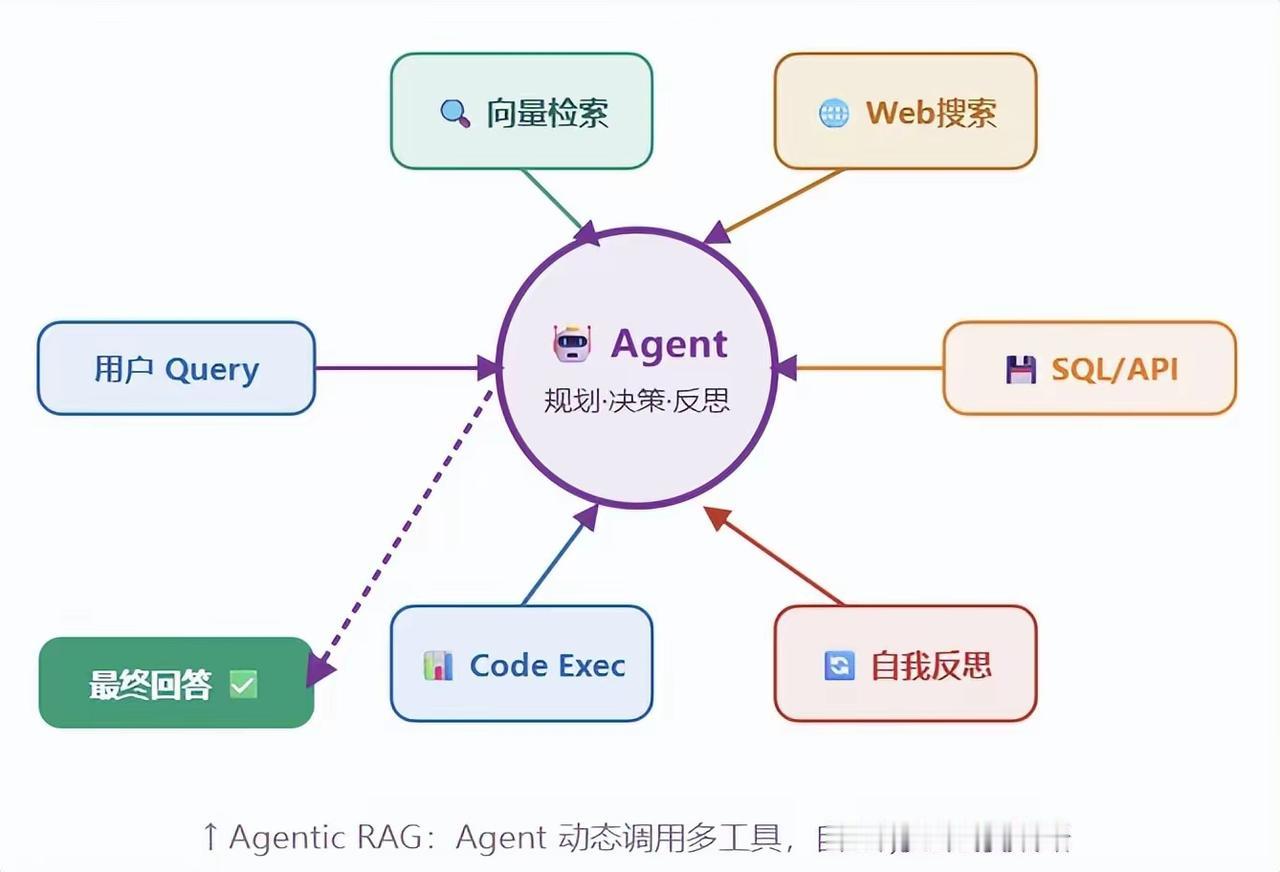
3. Agentic RAG(智能体版)
由Agent动态决策检索策略,自主调用多工具:
- 支持向量检索、Web搜索、SQL/API调用、代码执行、自我反思
- 能根据问题复杂度,自主规划检索路径,处理多步骤复杂问题
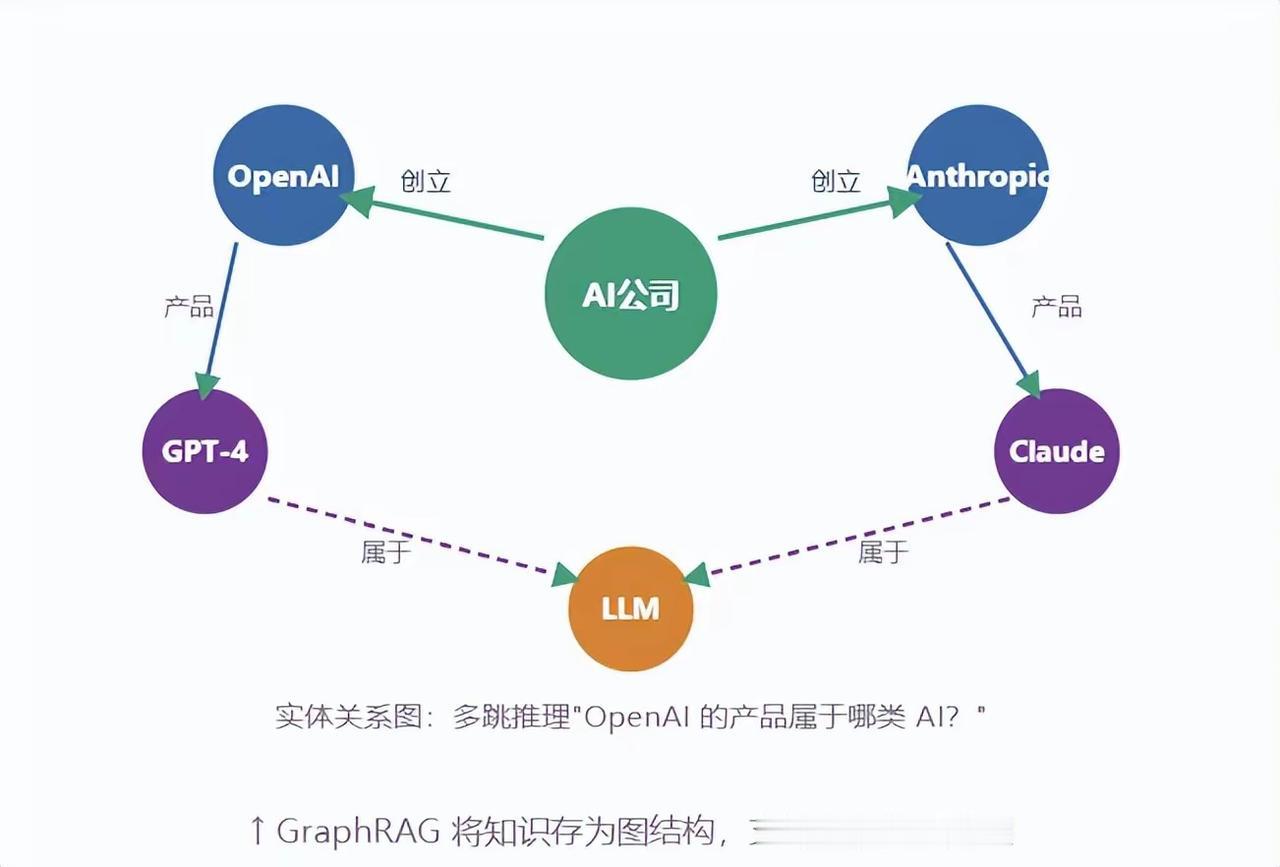
4. Graph RAG(知识图谱版)
将知识存储为图结构,支持复杂关系推理:
- 解决实体间的多跳推理问题,比如“OpenAI的产品属于哪类AI?”这类需要多层关联的问题
- 适合处理存在大量关联关系的复杂业务场景
四、关键技术细节
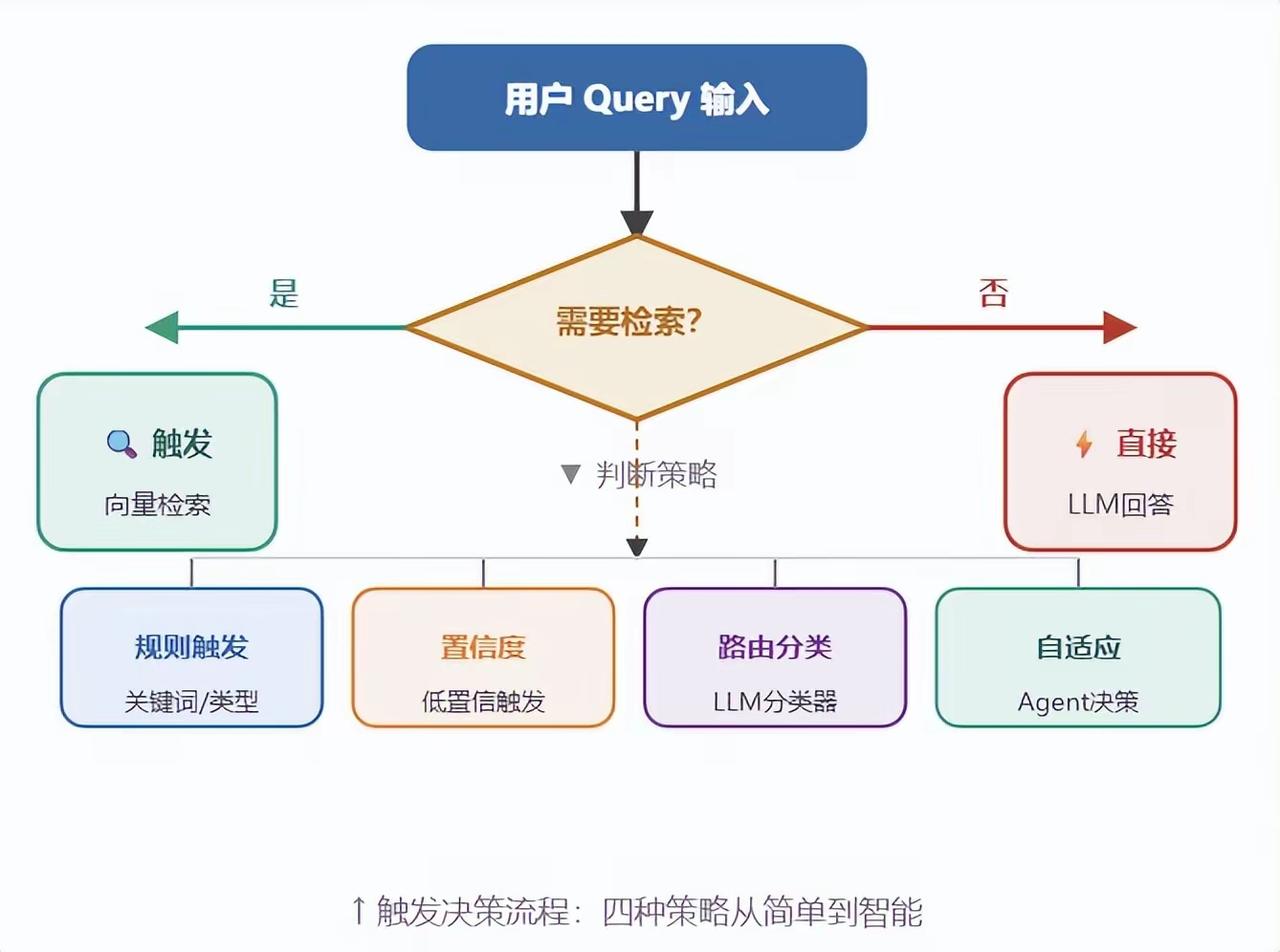
1. 检索触发决策流程
不是所有问题都需要检索,通过以下策略判断是否触发检索:
- 规则触发:通过关键词、问题类型匹配触发
- 置信度触发:模型置信度低时自动触发
- 路由分类:用LLM分类器判断是否需要检索
- 自适应触发:由Agent自主决策是否检索
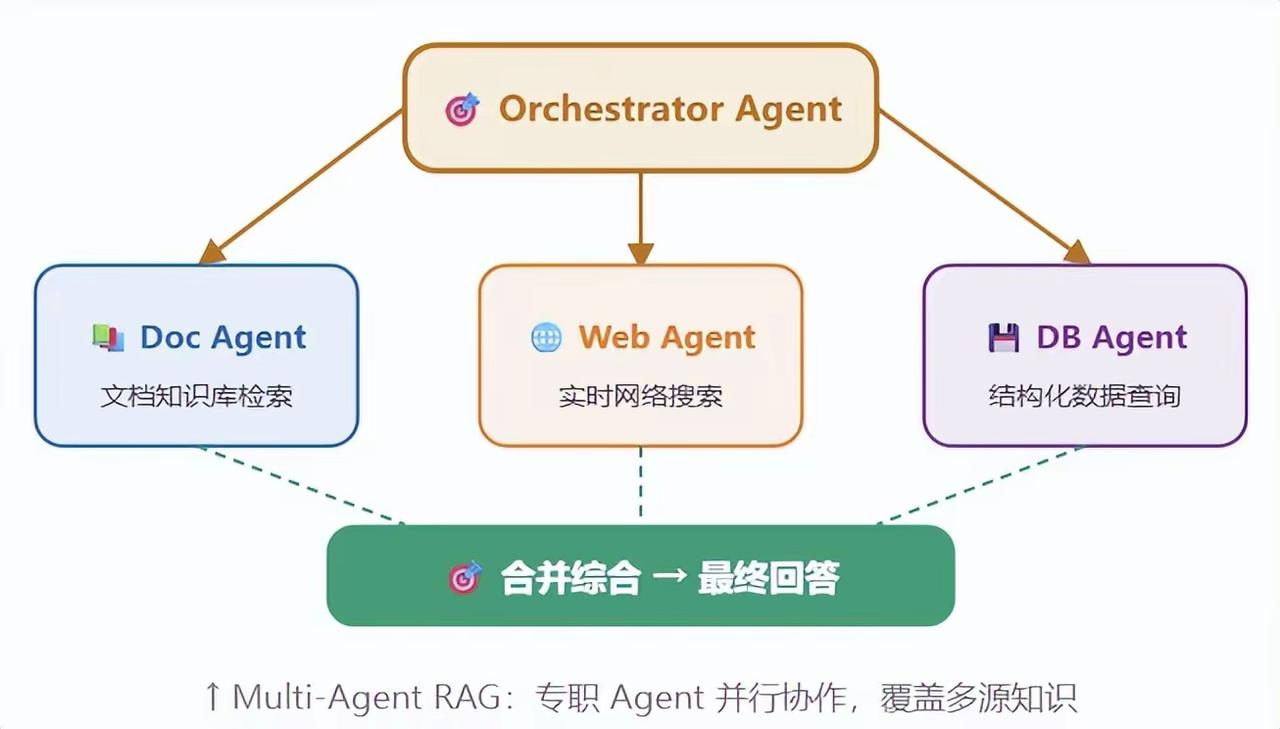
2. Multi-Agent RAG(多智能体版)
由不同专职Agent并行协作,覆盖多源知识:
- Orchestrator Agent(协调者):分配任务、汇总结果
- Doc Agent:文档知识库检索
- Web Agent:实时网络搜索
- DB Agent:结构化数据查询
- 最终合并多方结果,生成综合回答
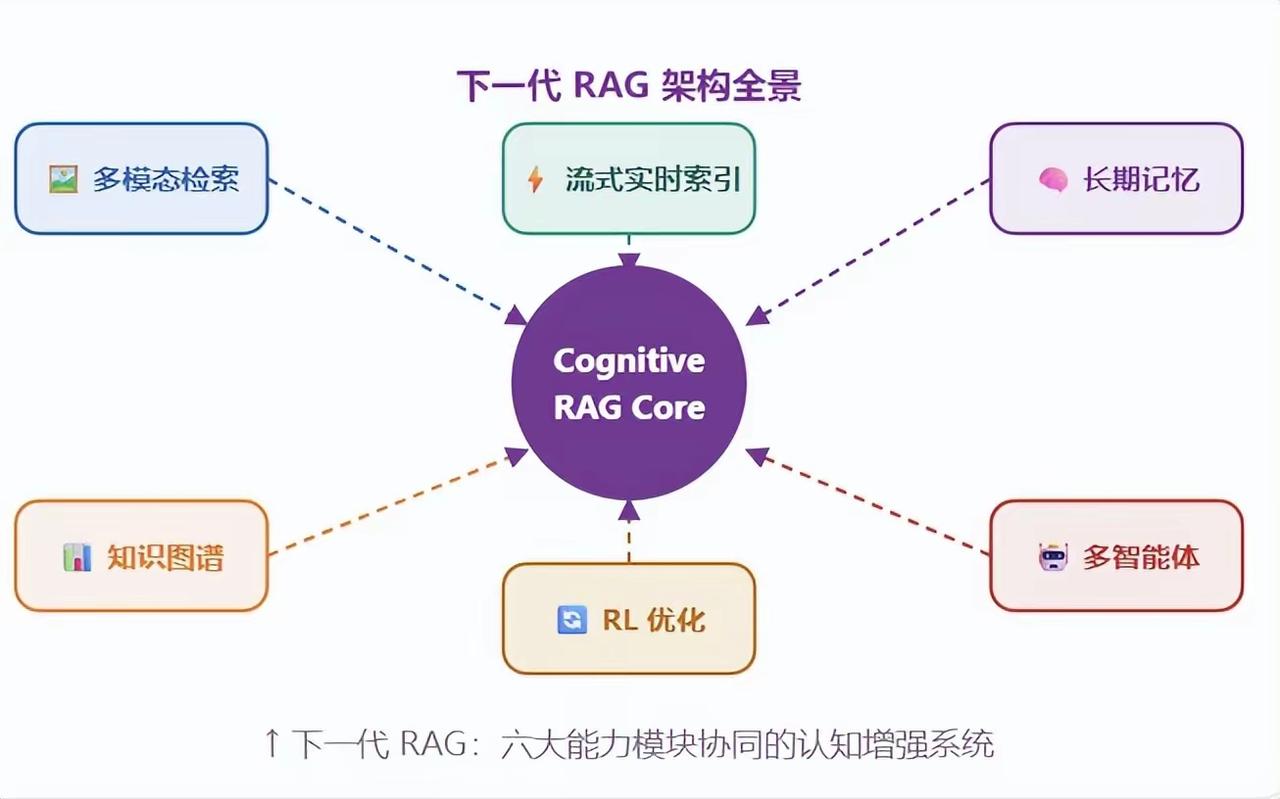
五、下一代RAG:认知增强系统
未来的RAG将从“检索工具”升级为“认知增强系统”,由六大模块协同工作:
1. 多模态检索
2. 流式实时索引
3. 长期记忆
4. 知识图谱
5. RL优化
6. 多智能体协作
AI底层架构 AHP层次分析 LLM原理 表征相似性分析 omr技术 rag反馈循环 RAG框架