CodeRetriever: Large-scale Contrastive Pre-training for Code Search
Xiaonan Li1∗ , Yeyun Gong2 , Yelong Shen2 , Xipeng Qiu1† , Hang Zhang2 , Bolun Yao2 , Weizhen Qi2 , Daxin Jiang2 , Weizhu Chen2 , Nan Duan2
Shanghai Key Laboratory of Intelligent Information Processing, Fudan University
引用
Xiaonan Li, Yeyun Gong, Yelong Shen, Xipeng Qiu, Hang Zhang, Bolun Yao, Weizhen Qi, Daxin Jiang, Weizhu Chen, and Nan Duan. 2022. CodeRetriever: A Large Scale Contrastive Pre-Training Method for Code Search. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2898–2910, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
论文:https://aclanthology.org/2022.emnlp-main.187/
仓库:https://github.com/microsoft/AR2/tree/main/CodeRetriever
摘要
本文提出了CodeRetriever,一种通过大规模代码-文本对比预训练来学习功能级代码语义表示的技术。CodeRetriever采用了两种对比学习模式:单峰对比学习和双峰对比学习。单峰对比学习是一种基于文档和函数名构建语义相关代码对的非监督学习方法;双峰对比学习利用代码的文档和行内注释来构建代码-文本对,这两个模式都可以充分利用大规模代码语料库进行预训练。
1 引言
代码搜索旨在检索给定自然语言查询的功能相关代码,以提高开发人员的生产力。最近的研究表明,代码预训练技术,如CodeBERT和GraphCodeBERT,可以通过使用大规模代码语料库的自我监督预训练来显著提高代码搜索性能。然而,现有的代码预训练方法通常采用(mask)语言建模作为训练目标,其目标是学习在给定的代码上下文中预测(masked)token。
然而,由于两个原因,这种基于标记的方法通常会导致较差的代码语义表示。第一个是各向异性表示问题。如在(Li et al.)中,令牌级自训练方法导致高频令牌的嵌入聚集并主导表示空间,这极大地限制了长尾低频令牌在预训练模型中的表现力。因此,各向异性表示空间导致较差的功能级代码语义表示。在程序设计语言中,标记不平衡的问题比自然语言更为严重。例如,常见的关键字和运算符如“=”、“{”和“}”几乎出现在Java代码的任何位置。
第二个问题是跨语言表达问题。广泛使用的CodeSearch-Net语料库(Husain et al.)包含来自Python、Java等六种不同编程语言的代码。由于具有混合编程语言的代码很难出现在相同的上下文中,因此对于预训练模型来说,学习具有相同功能但使用不同编程语言的代码的统一语义表示具有挑战性。
为了解决这些限制,我们提出了CodeRetriever,该工具专注于学习函数级代码表示,专门用于代码搜索场景。CodeRetriever由一个文本编码器和一个代码编码器组成,后者将文本/代码编码为单独的密集向量。我们采用了常用的CodeSearchNet语料库(Husain et al.,2019)来训练CodeRetriever。CodeSearchNet主要包含成对数据集(与文档成对的函数)和不成对数据集(只有一个函数),配对数据集可以直接用于双模态对比学习。对于单峰对比学习,我们通过无监督的语义引导方法建立代码-代码对。此外,生成的代码-代码对可以使用不同的编程语言,这可以减轻跨语言表示问题。为了进一步利用未配对数据和配对数据中的大规 模代码,我们提取了代码和行内注释对以增强CodeRetriever中的双峰对比学习。
内联注释(简短注释)也可以反映代码的语义和内部逻辑,这种细粒度的语义信息还可以帮助学习更好的代码表示。通过对比这些单峰和双峰对,代码检索器可以1.更好地学习函数级代码语义表示,缓解各向异性表示问题;2.显式建模代码与不同编程语言的相关性,并将统一自然语言视为减轻跨语言表示问题的支点。我们在涵盖六种编程语言、真实场景和不同粒度 (函数级、代码段级和语句级)代码的11个代码搜索数据集上对CodeRetriever进行了评估,结果表明CodeRetriever达到了一个新的水平。
本文主要介绍了结合单峰和双峰对比学习的代码检索器作为代码搜索的预训练任务。对于单峰对比学习,我们提出了一种语义引导的方法来构建正向代码对。对于双峰对比学习,我们利用文档和行内注释来建立正向的文本-代码对。在几个公开可用的基准上的大量实验结果表明我们提出的CodeRetriever带来了显著的改进,并在所有基准测试中达到了新的最高水平。此外,进一步的分析结果表明,CodeRetriever在低资源和跨语言代码搜索任务上也是强大的,并证明了单峰对比学习和双峰对比学习的有效性。
2 技术介绍
2.1 模型架构
我们将介绍CodeRetriever的模型架构和训练目标。
T1:代码-代码对(c, c+)和文本-代码对(t, c+)的语义相似度计算
用Ecode(·; θ)和Etext(·; ϕ)分别表示代码和文本编码器,代码-代码对(c, c+)和文本-代码对(t, c+)之间的语义相似度计算如下:

其中⟨,⟩表示余弦相似运算。
T2:单峰对比学习损失
给定一个成对的代码-代码训练样本(c, c+),单峰对比损失由下式给出:

其中τ是温度,为了简单起见,我们设τ=1;集合C由配对代码C+和通过批量负采样获得的N-1个不成对代码样本组成(Karpukhin等人,2020b)。特别是,一批可以由混合编程语言组成,这可以帮助预训练的模型学习具有不同编程语言的代码的统一语义空间。
T3:双峰对比学习损失
给定成对的文本代码训练实例(t,c+),双峰对比损失以相同的方式定义:
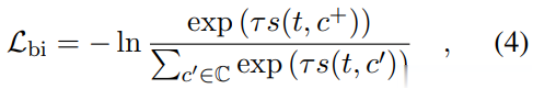
其中τ和C的定义与等式3中的定义相同。文本-代码批处理的代码还包括混合编程语言,这有助于调整不同编程语言和自然语言的语义空间。由于文档或注释反映了源代码的功能和关键语义信息,这样的正对可以帮助模型更好地理解代码的语义。
T4:预训练目标
如图1所示,我们使用和来分别表示代码-文档和代码-注释的对比损失,CodeRetriever预训练的总体目标是:


图1 单峰和双峰对比学习
2.2 正向配对
T1:代码-文档对
源代码文档通常能够提供丰富的语义信息并高度描述代码的功能。在图2中,文档“将输入数组按升序排序”清楚地总结了代码的目标,这可以帮助模型更好地理解代码。所以我们把代码c和它对应的文档t作为正向配对。

图2 冒泡排序
T2:代码-注释对
我们将代码注释视为正向配对,以进一步帮助模型学习更好的代码表示。
我们首先利用代码解析器(tree-sitter)将代码块分成两部分:纯代码和相应的行内注释。然后,我们执行如下后处理以过滤有噪声的成对样本,从而获得代码注释语料库:
1.我们将带有连续行的注释合并成一个注释。这是受开发人员通常将一个完整的注释写成多行以使其更容易阅读的现象的启发。
2.信息很少的注释被删除,包括:1)短于四个令牌;2)以“TODO”开头的注释;3)用于自动代码检查的注释。
3.删除语义信息很少的函数,如名称为“getter”、“setter”等的函数。
T3:代码-代码对
尽管相同功能的两个代码可能有不同的实现,但它们的文档或函数名可能非常相似,如图3所示。受这一现象的启发,我们提出了以下非监督技术来收集大规模的代码到代码语料库:
1.通过匹配函数名和文档收集有噪声的代码-代码对,方法如下:1)我们采用最近提出的无监督方法SimCSE(Gao et al.,2021b),用函数名语料库进行训练,得到“名称匹配器”模型;并用文档语料库进行训练以获得“文档匹配器”模型;“名称匹配器”和“文档匹配器”都是密集检索模型。2)对于语料库中的任何给定函数,我们使用“名称匹配器”通过函数名称匹配来检索其相关函数。我们只保留通过“名称匹配器”和“文档匹配器”检索分数大于阈值(0.75)的代码-代码对。

图3 斐波那契数列
2.利用交叉模型对码-码对进行去噪。我们训练了一个二进制分类器模型(Mc),用于过滤有噪声的码-码对。如图4所示,以下是两个步骤的说明:1)我们将噪声较小的码-码对作为训练集来训练交叉模型Mc。在Mc的训练中,我们使用集合作为正训练实例,而采样随机码-码对作为负实例。2)如果Mc对和中的码-码对的预测分数小于某个阈值,则删除它们。
3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下研究问题:
RQ1:在基准数据集上与最先进的方法相比,CodeRetriever的性能如何?
RQ2:CodeRetriever在低资源和跨语言代码搜索任务中表现如何?
RQ3:CodeRetriever的可扩展性如何?
RQ4:CodeRetriever对函数级表示空间的影响是怎样的?
RQ5:CodeRetriever中每个组件的效果是怎样的?
评估数据集。我们在几个代码搜索基准上评估了CodeRetriever,包括CodeSearch、Adv、CoSQA、CoNaLa、SO-DS、StaQC。Adv数据集对方法名和变量名进行规范化,这使其更具挑战性。CoNaLa、SO-DS和StaQC是从stackover-flow问题中收集的,而CoSQA是从web搜索引擎中收集的。因此,CoSQA、CoNaLa、SO-DS和StaQC中的查询更接近真实的代码搜索场景。同时,CoNALA、SO-DS和StaQC包含不同粒度的代码,即语句级和代码段级代码。
对比方法。我们比较了CodeRetriever和最先进的预训练模型,包括:CodeBERT,GraphCodeBERT,SynCoBERT,ContraCode,UniXcoder。我们采用微调实验的方法,将CodeRetriever和其他代码预训练模型在11个特定于语言/领域的代码搜索任务上进行微调。
评估指标。评估所有方法性能时主要采用了Ruby,JavaScript,Go,Python,Java,PHP六种语言,针对真实世界场景和不同粒度(函数级、代码片段级和语句级)的代码,使用的指标是代码搜索的准确率。
RQ1修复结果比较
实验设计。我们在几个代码搜索基准上评估了CodeRetriever,包括CodeSearch、Adv、CoSQA、CoNaLa、SO-DS、StaQC。此外,我们还探讨了以下三种代码测量仪微调的方法:
1.批内阴性。对于批处理中的查询-代码对,它使用批处理中的其他代码作为阴形样本。2.硬否定。它可以挑选“硬”代表性阴性样本,而不是随机阴性样本。与批量否定相比,硬否定训练效率更高3.AR2。这是最近提出的密集检索的训练框架。它采用对抗训练方法迭代选择“硬”负样本。在本文中,我们重点研究了使用AR2来增强用于代码搜索的编码器。在微调实验中,我们对{2e-5,1e-5}的学习率和{32,64,128}的批量进行网格搜索。在所有任务中,训练纪元、热身步数和重量衰减分别设置为12、1000和0.01。
结果。首先,我们报告CodeRetriever(批内阴性)的性能,如表1和表2所示,它使用与其他基线相同的微调方法来确保公平的比较。它表明,与所有其他比较方法相比,CodeRetriever获得了最佳的整体性能。具体来说,CodeRetriever在代码搜索数据集上比GraphCodeBERT提高了4.0个平均绝对点,这证明了CodeRetriever的有效性。与此同时,CodeRetriever在所有有报告结果的任务上都优于以前最先进的模型UniXcoder。在Adv、CoSQA、CoNaLa、SO-DS和StaQC数据集上,CodeRetriever也优于基线模型,这表明CodeRetriever在各种情况下始终优于基线模型。比较不同的微调方法,我们可以看到AR2通常优于批处理底片和硬底片。即,CodeRetriever(AR2)比批处理负样本平均提高3.0个绝对点,比硬负样本平均提高1.1个绝对点。实验结果表明,选择一个好的微调方法对于下游代码搜索任务也非常重要。此外,一个有趣的观察结果是,在StaQC基准测试中,批内负样本优于硬负样本和AR2。一种可能的解释是,与其他基准相比,StaQC在训练集中包含更多错误的查询代码对,因为它是通过基于规则的方法从stackoverflow收集的,没有任何人工注释,批处理负则比AR2和硬负则更能容忍噪声。
表1:CodeSearch数据集上的性能比较

表2:比较接近真实场景的数据集上的性能比较

RQ2 泛化能力分析
实验设计
1.我们评估了CodeRetriever在低资源场景下的性能,即只有几百个成对的查询代码数据用于微调。在CoSQA数据集的低资源设置下的进行实验,其中训练示例的数量从500到完整(19K)不等。
2.我们引入了一个新的设置,用“A”编程语言微调模型,并在“B”编程语言上进行测试。这可以缓解其他编程语言的数据匮乏问题。我们使用query-Python作为语料库,并用query-Java作为测试集。这两个数据集的查询都是从stackoverflow中收集的。
实验结果
1.表3展示了CodeRetriever和GraphCodeBERT在CoSQA数据集上的低资源设置下的结果,其中训练示例的数量从500个到全部(19K)不等。我们可以看到,与GraphCodeBERT相比,CodeRetriever在低资源环境下可以达到更合理的性能。
表3:低资源设置下CodeRetriever和GraphCodeBERT在CoSQA数据集上的性能

2.表4表明CodeRetriever中的单峰对比损失对跨语言代码搜索任务有显著帮助。通过结合双峰对比损失,CodeRetriever可以获得更好的性能。这一结果表明了CodeRetriever在真实场景中的潜在效用。
表4:跨语言代码搜索的对比

为了进一步分析单峰对比学习的效果,我们通过t-SNE可视化有或没有单峰对比学习的表示的二维潜在空间。在图5(a)中,我们可以看到Java和Python代码的表示出现在没有单峰对比学习的模型的两个独立集群中,而图5(b)它们的表示空间是重叠的。这表明单峰对比学习有助于学习不同编程语言代码的统一表示空间。

图5 Python和Java的二维可视化表示法,蓝色代表Java,橙色代表Python
RQ3 可扩展性分析
实验设计。在这个任务中,我们给定一个代码,要求模型返回一个语义相关的代码。我们在POJ-104数据集上进行实验并使用与先前工作相同的超参数,通过平均精度(MAP)对CodeRetriever的扩展性进行分析。
结果。通过平均精度(MAP)进行评估,如表所示5。我们看到CodeRetriever优于其它预训练模型,这证明了它在其他代码理解任务中的可扩展性和潜力。
表5:代码对代码检索任务的性能比较

RQ4 均匀性与对称性分析
实验设计。为了研究CodeRetriever对函数级表示空间的影响,我们使用对齐和均匀性度量来查看训练期间函数级表示分布的变化。
结果。如图6所示,我们发现CodeRtriever的均匀性损失逐渐下降,表明各向异性减轻。此外,我们发现对齐损失也有下降的趋势,这表明CodeRetriever的训练有助于对齐代码和自然语言的表示,并更好地理解它们。这两个指标表明,与以前的代码预训练模型相比,CodeRetriever减少了预训练和微调之间的差距。
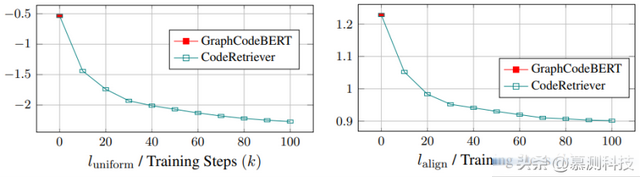
图6 均匀性与对称性曲线
RQ5 消融研究
实验设计。为了了解CodeRetriever中每个组件的效果,我们对CodeSearch Java数据集和SO-DS进行了消融研究。我们从最初的模型开始,一个一个地添加代码组件,查看CodeRetriever的性能。
结果。如表6所示,使用没有去噪的代码-代码对进行单峰对比学习会带来轻微的性能下降,而使用去噪后,性能会显著提高。这证明了去噪步骤的有效性,并表明单峰对比学习取决于正向对构建的质量。在这里,我们验证了一个简单有效的正向对构造方法,我们把开发更强大的方法作为未来的工作。从使用文档代码和注释代码进行双模态对比学习的结果中,我们看到该模型实现了进一步的性能改进,这表明双模态对比学习可以利用文档或注释中的关键语义信息来帮助更好地理解代码。
表6:消融研究

转述:叶恒杰
