
引用
Kang S,An G,Yoo S.A Preliminary Evaluation of LLM-Based Fault Localization
论文:https://arxiv.org/pdf/2308.05487.pdf
摘要
大型语言模型(LLM)在多个软件工程问题上表现出了令人惊讶的性能水平。然而,它们还没有应用于故障定位(FL),在故障定位中,必须从可能庞大的代码库中找到导致错误的代码元素。尽管如此,LLM在FL中的应用有可能在性能和可解释性方面使开发人员受益。在这项工作中,我们介绍了AutoFL,这是一种自动故障定位技术,只需要一个失败的测试,并且在其故障定位过程中生成关于给定测试失败原因的解释。使用OpenAI的LLM的函数调用API,ChatGPT,我们提供了允许它“探索”大型源代码存储库的工具,否则这将带来重大挑战,因为不可能在有限的提示长度内容纳所有源代码。我们的结果表明,在广泛使用的Defects4J基准模型上,AutoFL可以在第一次尝试更多时识别出错误的方法。尽管如此,仍有足够的空间来提高性能,我们鼓励将基于语言模型的FL作为一个有前途的研究领域进行进一步的实验。
引言
语言模型是近似于一种语言的概率分布的统计模型。机器学习的最新进展表明,当使用成比例的大数据集训练具有大量参数的可训练语言模型时——因此被称为大语言模型——它们显示出在较小的模型中无法观察到的“融合”特性,如少样本学习、常识推理和以下逻辑步骤。因此,LLM也吸引了软件工程研究人员的极大关注,从而他们研究了错误诊断、补丁生成、测试生成和错误复制。
故障定位(FL),或查找导致错误的代码元素的问题,在该列表中明显缺失,因为我们不知道先前的研究应用LLM来预测故障位置。在故障定位中,给定错误的特征(如失败的测试或错误报告),任务是识别对错误负责的代码元素。故障定位的一个关键输入是整个软件存储库,但这个输入太大了,LLM无法简单地处理——据我们所知,可以同时处理最多令牌的LLM,OpenAI的gpt-4-32k,只能处理32000个令牌,而调试中使用的项目两位作者对这项研究的贡献相同。搜索可以有96000行代码。因此,在将LLM应用于FL之前,需要克服一个技术障碍。
尽管如此,能够利用LLM进行故障定位可能会使开发人员受益。首先,在程序修复和测试中,给定相同的软件配置和计算资源,LLM显示出比传统技术更好的性能。如果基于LLM的FL可以类似地优于现有技术,这将有助于开发人员采用自动FL技术,因为开发人员期望自动FL技术具有一定程度的性能。此外,开发人员经常需要更多的上下文,或解释如何导出FL结果。现有的自动FL技术以与人类明显不同的方式得出答案,因此不适合生成可理解的解释;另一方面,LLM可以生成对其调试过程的解释,因此基于LLM的FL可以帮助开发人员理解结果。
为此,我们提出了AutoFL,这是一种结合OpenAI LLM的函数调用功能的技术,并为LLM提供了查看存储库中选定部分的工具,以及将LLM答案与实际代码元素匹配的后处理管道,从而显著降低了提示要求,并使LLM能够有效地定位故障。具体来说,给定一个测试及其失败堆栈,我们允许LLM浏览源代码,允许它调用返回有关覆盖类、其覆盖函数以及任何覆盖函数的实现和Javadoc(如果可用)的信息的函数。给定LLM使用可用函数找到答案的提示,LLM将调用函数调用序列来收集相关信息,并得出错误如何表现的结论。在这个过程的最后,我们要求最有可能导致错误的方法的输出,这被视为故障定位结果。我们开发了一个后处理管道,该管道收集多个LLM输出,然后对这些结果执行后处理,以将文本预测与现有代码元素相匹配,并提高排名性能。
为了评估AutoFL并对LLM执行FL的效果进行初步评估,我们在广泛使用的去bug基准Defects4J上评估了AutoFL。我们发现,仅使用失败测试,AutoFL就可以在353个案例中的149个案例中成功识别出真正的错误位置,这比Zou等人评估的任何独立技术都要好。这不值得注意,因为其中一些技术需要在失败测试的基础上通过测试,而不像AutoFL。进一步将AutoFL与性能次佳的独立技术(Spectrum BasedFL)进行比较,但在仅使用失败测试的设置下,AutoFL的性能优于SBFL 338%,这表明当在与AutoFL一样的适当管道中使用LLM时,LLM可以是有效的故障定位器。此外,我们发现我们的后处理管道产生了实质性的贡献。通过在困难的测试中提供AutoFL调试痕迹的成功和不成功的例子,尽管错误的方法并没有立即显现出来,但我们强调了AutoFL的优势,以及指出未来研究需要的潜在弱点。
方法
在本文中,我们介绍了AutoFL,这是一种新颖的自动化和自主FL技术,它利用LLM在给定单个失败测试的情况下定位软件中的错误。如前所述,处理大型代码存储库对LLM来说是一个挑战,但我们通过为LLM配备自定义设计的功能来解决这个问题,从而实现代码探索和相关信息提取。
AutoFL的概述如图1所示。我们采用两个阶段的提示过程,第一阶段涉及询问给定故障的根本原因,第二阶段请求输出故障位置。在第一阶段,1. AutoFL向LLM提供提示,其中包含故障测试信息和可用于调试LLM的可用功能的描述。2. LLM与所提供的功能频繁交互,以提取给定故障的调试所需的信息。3. 基于收集的信息,LLM生成关于所观察到的故障的根源的解释。在第二阶段,4. 用户查询已识别错误的位置,5. LLM通过提供过失方法(FL输出)进行响应。通过这样做,我们可以明确地获取根本原因解释和bug位置。

图一:AutoFL示意图。每个箭头表示组件之间的prompt/response,圆圈数字表示交互的顺序。函数调用最多进行N次,其中N是AutoFL的预定义参数。
2.1 阶段一:生成根本原因的解释
为了向LLM提供有关失败测试的信息,AutoFL自动生成一个对LLM的查询,其中包含错误的详细信息,例如失败的测试及其错误堆栈。清单2显示了提示模板,故障详细信息以青色突出显示
首先,提示指定失败测试的名称,并提供测试代码片段(第1-9行)。测试代码片段在三个倒勾内闭合,表示它是一个代码块。为了只提供基本信息,我们将代码段最小化,以便只包括到失败发生时为止的语句,失败发生时会明确标记为注释“//error occurred here”。如果故障发生在嵌套块中,则包含错误的整个最外语句都会包含在内。此外,任何前面的断言语句都会被检测并删除。例如,清单2中的第384行被删除,因此不可见。

在代码段之后,提示显示故障症状,包括错误消息和堆栈跟踪(第13-14行)。通过只保留与目标存储库相关的信息(例如,省略与外部库相关的行),堆栈跟踪会自动最小化。此外,循环次数超过五次的重复子序列被压缩,以提高读取能力和简洁性,这有助于处理长堆栈跟踪,例如StackOverflow错误。
最后,提示结束时建议LLM调用get_covered_classes函数(第16行),以鼓励LLM在生成答案时使用函数。初步实验表明,这提高了LLM的函数调用成功率。当AutoFL在其提示中使用单个测试时,请注意,通过连接每个测试的信息,可以很容易地扩展提示以处理多个失败测试
除了提示,LLM还提供了四个用于调试的特殊功能(如图1所示)。图中用红色表示的前两个功能允许LLM获得与故障测试相关的术语级和方法级覆盖信息。有了这些功能,LLM可以缩小与观察到的故障相关的方法范围,从而能够有针对性地分析根本原因。后两个函数在图中用蓝色表示,构成了通用的代码导航工具。这些函数将感兴趣的方法的签名作为输入,并返回代码片段和相关文档(如果存在)。无论多么简单,这些功能都允许LLM有很大的灵活性来探索存储库并访问方法的当前实现和指定。
总体而言,AutoFL将初始提示和功能描述一起提供给LLM(图1,1),并允许其“决定”是请求函数调用还是解释错误。如果LLM请求函数调用,AutoFL会执行该函数,并通过将结果添加到消息历史记录中,将返回值提供给模型(图1, 2)。一旦LLM在没有请求进一步函数调用的情况下为根本原因生成解释,阶段1就结束了(图1, 3)。如果LLM耗尽了其功能调用预算,则AutoFL只需进入第2阶段。在这种情况下,LLM不再被允许请求函数调用,必须使用可用信息生成响应。
2.2 精确定位故障位置
在第1阶段结束后,LLM会被提示根据可用信息预测筛选方法(图1,4)。这个请求的提示如清单3所示。在这个阶段,与阶段1不同,我们不向LLM提供任何功能。相反,我们强制模型立即响应,假设LLM已经(隐含地)识别了故障位置,同时了解了故障的根本原因。最后,整个FL过程以LLM提供包括潜在故障位置在内的响应结束(图1,5)。

例如,给定阶段1中关于Lang-48(清单2)的初始提示,LLM依次进行四个函数调用:首先,获取失败测试所涵盖的类和方法,然后检索两个方法的代码片段,isEquals()和append(Object,Object),EqualsBuilder。LLM随后确定了错误的根本原因:错误地使用了BigDecimal对象的equals方法,导致基于append方法中的引用而非值进行比较。在阶段2中,LLM建议将EqualsBuilder.append(Object,Object)作为罪魁祸首,这与开发人员的补丁位置相匹配。
2.3 最终确定故障定位结果
为了解决LLM的固有可变性,我们建议重复AutoFL过程R次(在我们的实验中R=5)。之后,我们将这些结果合并为一个单一的FL结果。值得注意的是,若存在多个失败的测试,我们会在每次运行AutoFL时使用不存在的失败测试用例。具体来说,如果只有一个失败的测试用例,那么所有迭代都是在特定的测试用例中进行的。然而,当有几个失败的测试用例时,我们采用循环方法,为每次运行选择一个失败的测试案例,以确保迭代的均匀分布。为了澄清,如果失败测试用例的数量超过了预先定义的最大重复次数,R, 我们只限制我们的选择R失败的测试用例。
给定R从AutoFL生成的预测,我们聚合输出以驱动可疑方法的排序列表。首先,根据AutoFL标记为可疑的方法是否出现在从R跑。具体地说,如果最终预测包含总共n方法,我们给1/n对于这些已识别的方法中的每一种。然后将这些单独的分数合并到所有R预言。为了说明这一点,假设5次运行中的最终预测是{m1,m2},{m2},{m2,m3},{m3}和{m2,m4},则方法2的得分计算为:0.5+1.0+0.5+0.0+0.5=2.5在得分相等的情况下,我们将较早出现的预测方法优先于其他方法。例如,在给定的示例中,得到的排序列表将是[m2,m3,m1,m4]。
最后,如果有一些方法不是最终AutoFL结果的一部分,但被失败的测试用例覆盖,我们将它们附加到排序列表的末尾,以确保列表包括与失败相关的所有方法。这些方法按照覆盖每个方法的失败测试数的降序进行排序。对于中断,我们优先考虑在AutoFL的功能交互过程中更频繁提及的方法(图1,2),这是基于这样的直觉,即LLM或者与检查的方法相关的方法比调试过程中从未观察到的方法更有可能是错误的。
3 结果
3.1 实验设置
为了评估AutoFL能够在多大程度上揭示故障位置,我们使用了广泛使用的真实世界错误基准Defects4J。我们选择该基准是因为它一直是多个故障定位研究的主题,特别是Zou等人的比较实证研究,该研究使用堆栈跟踪(Zou等人基于Schroter等人的堆栈中的姿态预测方法)、谓词切换、IRFL和基于历史的故障局部化,比较了各种故障定位族的故障定位性能:SBFL、MBFL、切片。其中,IRFL和基于历史的故障定位被排除在外,因为在Zou等人的评估中,它们不能将任何真正的错误位置确定为最有可能的故障元素。引入与我们的工作相关的两个额外基线:(i)在没有任何函数调用的情况下,相同的LLM如何识别错误位置,即调用预算=0(LLM+测试基线),以及(ii)仅使用失败测试的SBFL(SBFL-F基线)。我们将AutoFL的比较限制在这些独立的指标上,通过将评估仅限于无监督的FL技术来保持公平性。由于AutoFL不涉及任何明确的学习过程,我们预计其结果也可以作为基于学习的FL技术的一个特征,该技术结合了多个FL结果。
继Zou等人之后,我们使用了Defects4J中的五个项目(Chart、Closure、Lang、Math、Time),它们总共包含353个错误,不包括Defects4J数据集中因问题(例如问题重复)而被弃用的一些错误。为了公平地进行比较,我们使用Zou等人公开共享的研究成果,在与我们相同的环境中得出排名,命名了一个有序的决胜局而不是平均决胜局,并从Defects4J基准中删除了四个不推荐使用的bug。为了方法评估,我们使用acc@k指标,用于测量任何错误代码元素在正确定位的数量前k个建议;这个acc@k度量还有一个额外的好处,那就是它更接近于开发人员对FL的期望。由于基于LLM的FL技术生成文本作为最终输出,而不是精确定位位置,因此该文本必须与存储库中的现有方法相匹配。在这项工作中,我们检查faultmethod的类名、方法名和方法参数是否都与预测的方法匹配,以检查AutoFL是否准确地找到了故障位置。在我们的实验中,我们使用了OpenAI的pt-3.5-turbo-0613语言模型。
3.2 FL表现
根据Zou等人的研究,将AutoFL的FL性能与显示非零性能的七种基线技术进行了比较。该比较的结果如表1所示。我们发现AutoFL可以在其第一选择上找到准确的错误位置(acc@1)在149种情况下,它显示出优于所有与之进行比较的独立技术的性能,包括来自先前确定的最佳故障定位家族的技术SBFL,同时在acc@3 和acc@5也值得注意的是,AutoFL显示出与独立FL技术相当的性能,独立FL技术需要开发人员提供更多的软件工件,尽管它只使用失败的测试来识别故障位置。相比之下,这是需要开发人员提供更多软件工件的其他FL技术,如SBFL技术DStar和Ochiai,它们通常需要通过测试才能获得良好的性能。此外,我们发现AutoFL比LLM+Test基线(不从存储库中检索信息)的性能提高了84.0%acc@1). 这表明函数调用有助于提高FL性能。总的来说,我们的结果表明,AutoFL提供了最先进的独立故障定位性能,并且这些结果是通过为LLM提供开发存储库的工具而实现的。
表1: AutoFL和FL技术性能
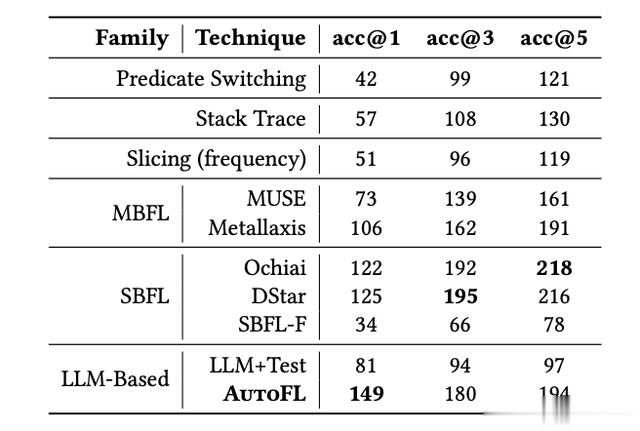
为了研究SBFL是如何使用与AutoFL相同的工件来执行的,我们还将其与SBFL-F基线进行了比较,后者只使用失败的测试;我们发现SBFL-F的表现基本上比AutoFL好。这些结果表明,与现有技术不同,即使没有预先存在的测试套件,AutoFL也可以提供最先进的FL性能,这突出了AutoFL的广泛应用性。例如,Kang等人指出,42%的顶级Java存储库没有可检测的JUnit测试套件,因此即使提供了失败的测试,SBFL性能也会很低。另一方面,即使没有预先存在的测试套件,AutoFL也可以提供强大的性能
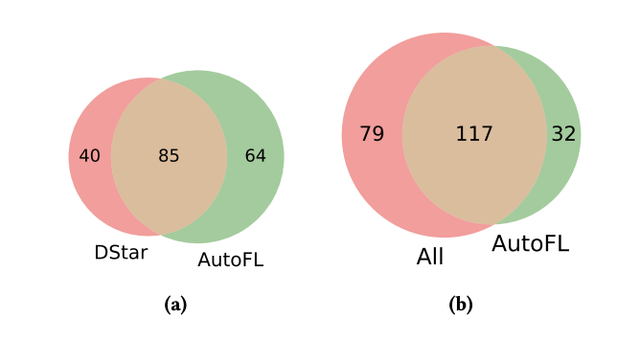
图2: 通过第一级技术成功定位的错误的重叠分析
虽然AutoFL与以前最好的自动FL技术相比取得了更好的acc@1成绩,但是它可能在与现有技术类似的一组类似的错误中提供了正确的结果,在这种情况下,自动FL的结果将不那么令人感兴趣,并且实际上为监督FL技术提供了很少的边际值。我们验证了AutoFL正确定位的一组错误与最佳基线SBFL技术DStar基本不同,如图2(a)所示;AutoFL能够成功定位的错误中,有40%以上没有被DStar正确定位在第一列。事实上,即使与我们使用的所有基线技术相比,AutoFL也可以对32个错误进行唯一定位(图2(b)),这表明它的性能确实与其他技术正交。

表3:当结合更多运行信息的性能
最后,我们在图3中展示了聚合多个运行的结果。如图所示,随着算法的重新运行和更多结果的合并,AutoFL的性能均匀地提高k, 这意味着重复跑步可以完善排名,并建议被前几次跑步忽视的新位置,从而持续提高成绩。此外,性能似乎并没有停滞不前,这表明更多的运行可以进一步提高性能。这些结果表明,我们的结果聚合算法(第2.3节)有助于提高单独运行的性能,同时仍然优于现有的方法acc@1测量的结果比合并后的结果表现得更好(准确地发现大约少40个位置)。合并也有助于提高AutoFL的精度:在我们的实验中,当所有五次运行都同意一个错误位置时,该位置实际上是错误位置的可能性为93.5%,这表明这些功能有可能用于评估AutoFL在预测中的可信度,从而减少开发人员在误报方面的麻烦。
3.3 函数调用模式

图4: 大多数常见的函数调用序列模式都是运行不成功和不成功。黑色方块表示LLM在下一步停止调用函数
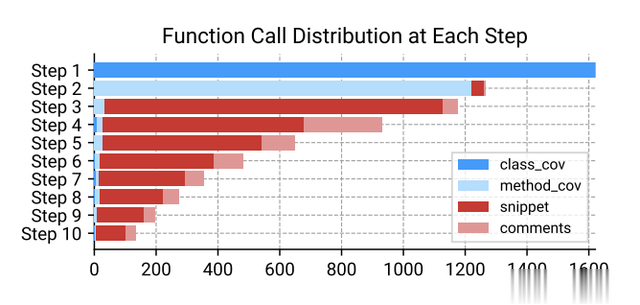
图5: 函数调用频率在AutoFL的所有五次运行中逐级递增。每一步的总长度都会减少,因为AutoFL可以在任何一步停止调用函数;例如,大约400个AutoFL进程在第一步之后停止调用函数
除了研究AutoFL相对基线的性能外,我们还检查了LLM如何在AutoFL框架内识别故障位置开关。首先,我们分析了AutoFL成功和失败运行中的代表性函数调用模式,结果如图4所示。成功率最高的函数调用模式如下:检索覆盖了哪些类,然后在感兴趣的类中覆盖了哪些方法,然后观察到三个连续的方法。一个常见的成功模式是类似地观察目标方法的代码和注释。经过这样的确认过程,AutoFL似乎可以成功地识别出检索到的方法确实存在故障。另一方面,当AutoFL失败时,AutoFL要么在满足调用预算之前毫无目标地检查了多个方法(左),要么没有检索到类覆盖范围之外的任何信息,然后跳过得出结论(右)。这表明过早或过度扩展的调试过程可能会产生较差的性能,LLM+Test基线的较低性能也表明了这一点。
在图5中,我们还为每个bug提供了每一步的方法调用频率。按照指示,在第一个函数调用步骤中,AutoFL始终请求所覆盖的类(蓝色)。在下一步中,AutoFL通常会检索失败测试所涵盖的方法,尽管LLM没有得到这样做的下一个应用程序指令。最后,从第3步开始,AutoFL主要通过调用get_code_snippet和get_comments函数来检查存储库的实际代码。如图所示,函数调用的平均长度存在显著差异;作为参考,函数调用的平均次数为5.36次,标准偏差为2.78次。
3.4 定性分析

最后,我们给出了从AutoFL运行的示例,一个成功,一个失败。在成功的例子中,我们展示了AutoFL从Defects4J基准测试中查找错误Math-30的原因的过程,在该测试中,失败的测试并不能明确测试的方法(错误的方法名称从未出现在测试中)。在这个bug中,由于在计算中的p值时出现整数溢出问题,清单4所示的测试失败计算渐近值函数,为了简洁起见,我们在本段中将其称为[CAPV]。图6显示了AutoFL如何调试问题以查找错误位置的示意图。AutoFL的函数调用序列如图6的左半部分所示。在这里,我们可以看到,AutoFL在识别存储库的哪个部分对错误负责的过程中检查了四个不同的函数。在前两个函数调用提供了关于失败测试执行了存储库的哪些部分的信息后,基于用户消息提供的测试代码(如清单2所示),AutoFL使用代码检查函数查看测试中提到的mann-Whitney U 检验的代码。反过来,这个方法调用了另外三个方法,其中两个方法随后被AutoFL检查:mann-Whitney U 检验和[CAPV]。在依次检查这些方法后,AutoFL再次检查测试方法(图6(4)),并根据断言和函数的预期行为得出结论,[CAPV]函数最有可能是错误的罪魁祸首。事实上,开发人员实际上修复了这个函数来删除bug。同时,SBFL(Ochiai)无法对该方法进行高级别排名,原因有两个:(i)由于该测试并非专门测试错误方法,失败测试的覆盖范围没有明确指定单一方法,以及(ii)在这种情况下,执行这部分代码的通过测试太少,无法提高SBFL的准确性。这个例子清楚地表明,AutoFL有可能在软件存储库中更深入地识别代码的哪一部分可能导致错误,并且它可以提供有意义的FL结果。
除此之外,我们还将在清单5中介绍AutoFL对其调试过程Math-30所做的解释。解释从解释测试检查内容开始(第1行),然后总结AutoFL在展示相关代码时查看了哪些方法以及这些方法在做什么(第2-7行)。最后,AutoFL正确地推断出p值计算产生了意想不到的结果,并预测[CAPV]是错误的位置。这个例子来自一个处于早期开发阶段的算法,它阐明了AutoFL如何在自动调试时为开发人员提供有用的解释,这是现有工作中缺少的一个重要功能,如前所述。

图5: AutoFLon Defects4J Math-30的运行示例


对于不成功的示例,我们介绍了错误Time-25的情况,其中AutoFL未能正确识别导致错误的代码元素。在这里,清单6中给出的看似无害的测试只是复杂性的冰山一角;只有在多次方法调用之后才能看到导致测试失败的代码,这使得AutoFL很难准确地允许所有方法调用到达真正的错误方法。我们没有准确地遵循第2行构造函数调用的方法的长跟踪,而是发现AutoFL遵循了调用过程两个步骤,在这一点上生成了关于错误发生原因的(错误的)解释,最终建议修复ZONE_MOSCOW变量。这突出了AutoFL的弱点,因为它还不能完全解决项目中深层次的bug问题,而经常执行“浅层”分析。这也是其相对较弱的可能原因acc@5表1中的性能:而AutoFL更能识别测试的意图,因此在识别第一级的责任方法时表现出更强的性能(acc@1)当这种猜测是错误的时,与基线相比,AutoFL很难评估大量方法,最终导致性能降低(acc@5). 反过来,这也指向了未来研究的途径为了解决LLM检查存储库的问题,必须做更多的工作,使LLM能够执行深度分析,并在真正困难的调试情况下帮助开发人员。
转述:肖媛
