这里所有文章均来自
微信公众号“火星AIGC”
想要看到更多更新的AI前沿信息、AI资讯和AI工具实操,请关注微信公众号“火星AIGC”。
花了两天时间,对全球5个SOTA大语言模型和国内14个大语言模型以及5个次级模型进行了评测,用的是最新的“爱丽丝漫游仙境”推理问题,总共花费6美分。对于GPT-4o依然是王者的结果并不意外,惊喜的是文心一言4.0竟然评测结果跟GPT4o一样,并列冠军,颠覆我的认知。不仅是文心一言,包括国内其他大语言模型的评测结果都有超过国际几大SOTA大语言模型,这让我重新认识了一遍国内LLM。

爱丽丝在推理:它会坏吗?约翰·坦尼尔(John Tenniel)的《透过镜子看矮胖子》插图,1871年。资料来源:维基百科。
做这个评测的初衷是看过德国LAION团队写的一个以“爱丽丝漫游仙境”命名的简单推理对大语言模型进行评测的论文后,并不满意。该论文以“爱丽丝漫游仙境”(AIW)为名,对全球36个大语言模型进行了一系列基准测试,测试以下面这个简单的逻辑问题为基础。
“爱丽丝有N个兄弟,她还有M个姐妹。爱丽丝的兄弟有多少个姐妹?”这个问题几岁的小朋友应该都能回答出来,答案就是简单的M+1。
论文地址:arxiv.org/abs/2406.02061
这篇论文有一定启发性,但是我对于其内容和结论并不满意。一是虽然选了36个大语言模型,但是感觉就是在菜市场随便打包了几十种肉菜,开源的、闭源的、迷你的、顶流的、专攻代码的全放在一起测试,而且只有千问和零一的几个国内的开源模型在里面。
二是论文将评测结果搞成贝塔分布,一点也不直观(数学学渣的怨念)。

三是论文对个别大模型例如Llama3-70b的响应崩溃问题过分解读,以至于国内有些自媒体宣称“曝出GPT、Claude等重大缺陷”。虽然我个人部署的Llama3-8b上也经常遇到其崩溃不断的给出循环答案,但应该只是Llama3的问题。
我做这个评测的目的,以这个没有被收录进基准测试数据集的推理问题,通过简单测试的结果,看看国内主流和国际顶流的大语言模型在基础推理上的能力,管中窥豹的了解一下目前这些大语言模型的基本推理性能。
参赛模型
介绍一下本次参赛选手。首先是国际上顶流的5个SOTA大语言模型,其中一个开源,四个闭源。王者GPT-4o肯定有,然后是谷歌的Gemini1.5-Flash、Claude3-Opus、Mistral-Large,最后一个是开源的Llama3-70B。
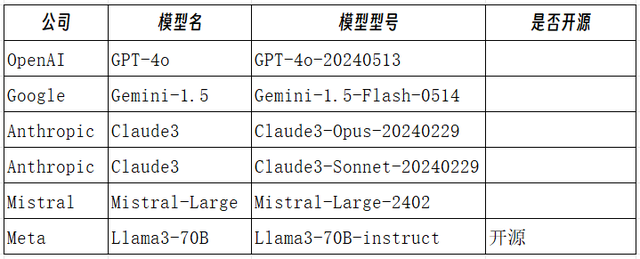
国内找了我能找到的十四个旗舰大语言模型。有最新面世的腾讯的混元大模型——元宝和百川智能的百小应,百度的文心一言4.0、阿里的通义千问2.5和其开源的Gwen2-72B等。
另外加入了5个次级模型作为补充参考,有百度的文心一言3.5、零一万物的Yi-1.5-34b,我本地电脑部署的Gwen2-7B-instruct和GLM-4-9B-chat,以及我常用的Claude3-Sonnet。
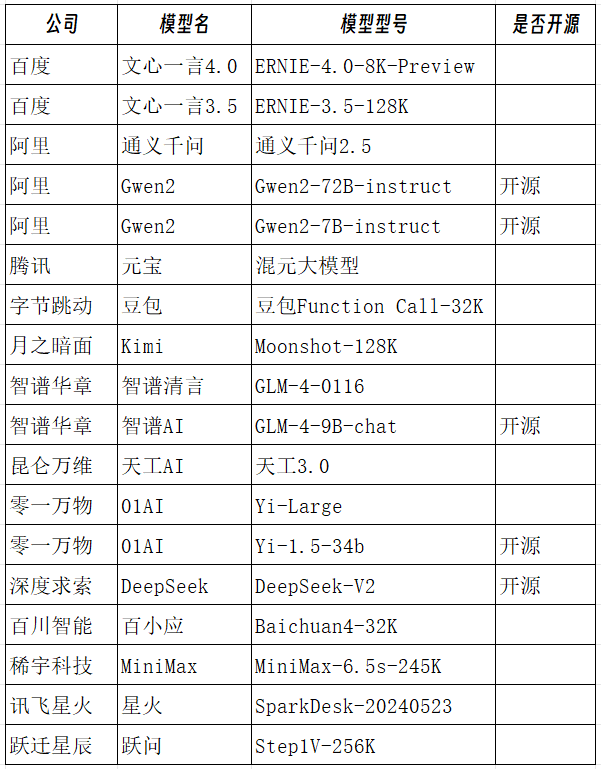
这个模型选择虽然不能说面面俱到,至少基本囊括了目前国内大部分和国际上最好的大语言模型了。
原论文评测方法
原论文中以AIW问题为基准,将其中M和N数字改变一下,作为基本测评。
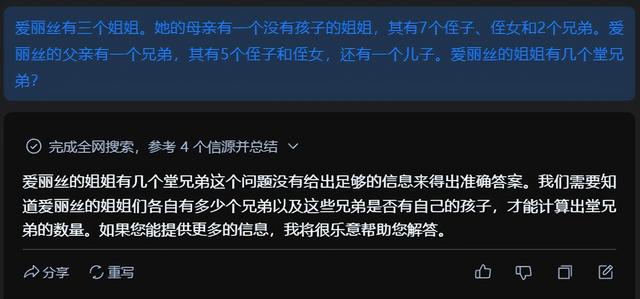
另外升级了一下类似的问题,例如“爱丽丝有三个姐姐。她的母亲有一个没有孩子的姐姐,其有7个侄子、侄女和2个兄弟。爱丽丝的父亲有一个兄弟,其有5个侄子和侄女,还有一个儿子。爱丽丝的姐姐有几个堂兄弟?”作为AIW+问题测试。
在变化数字的情况下,将AIW和AIW+问题对每个模型分别测试了30次。
在提示词上,原论文采用 STANDARD, THINKING, RESTRICTED三种提示词方式来喂给AI。STANDARD模式提示词就是只提问题并加入【以以下形式提供最终答案:###答案:“”】这句话。THINKING模式就是提出问题并要求仔细思考和仔细检查解决方案中是否有任何错误。RESTRICTED模式就是限制模型给出解释,只给出结果。
我的评测方法
我的方法突出一个简单粗暴,提示词直接0 shot,就是直接喂AI一个问题,不加任何其他提示词。
问题就四个,实际就是AIW和AIW+基本问题的中英文版。
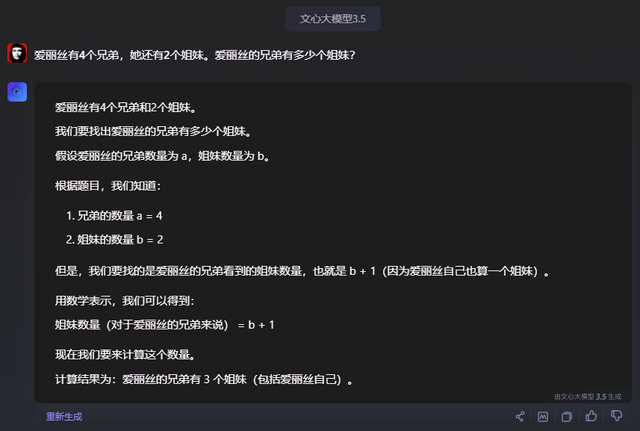
爱丽丝有4个兄弟,她还有2个姐妹。爱丽丝的兄弟有多少个姐妹?
Alice has 4 brothers and she also has 2 sisters. How many sisters does Alice’s brother have?
爱丽丝有三个姐姐。她的母亲有一个没有孩子的姐姐,其有7个侄子、侄女和2个兄弟。爱丽丝的父亲有一个兄弟,其有5个侄子和侄女,还有一个儿子。爱丽丝的姐姐有几个堂兄弟?
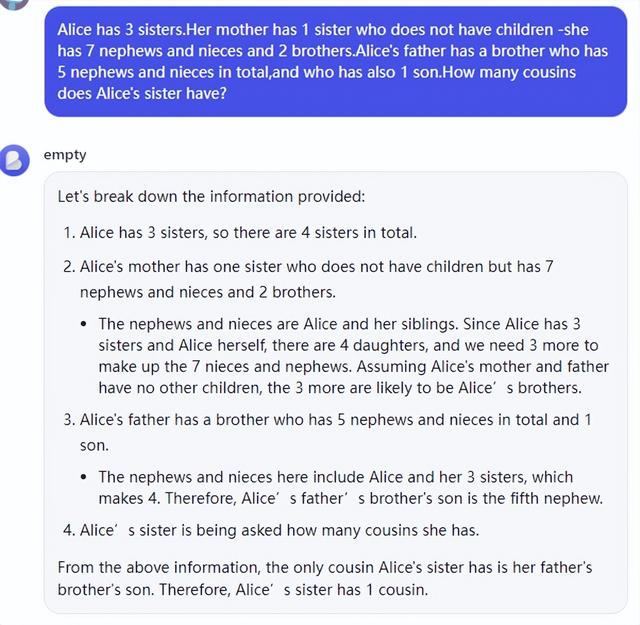
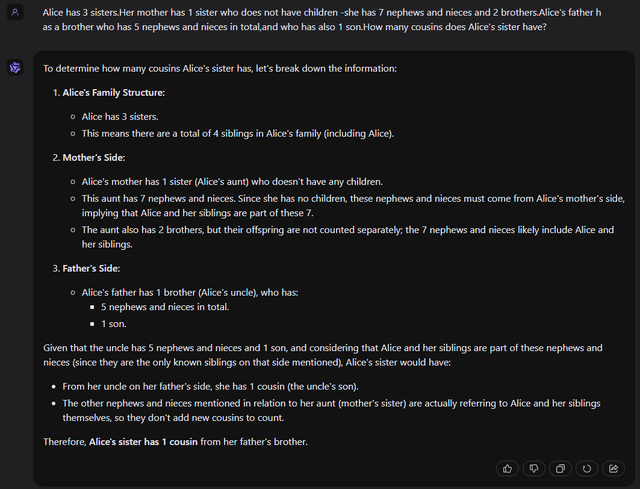
Alice has 3 sisters.Her mother has 1 sister who does not have children -she has 7 nephews and nieces and 2 brothers.Alice's father has a brother who has 5 nephews and nieces in total,and who has also 1 son.How many cousins does Alice's sister have?
大家应该注意到了,虽然实际只是两个问题的中英文版,但是英文“cousin”和中文“堂兄弟”的含义是有差异的。但这个AIW+设计的是中英文答案一致。
评测结果
对于这个评测有意料之内的,GPT-4o并不像原论文说的有什么问题,其4次问题回答都完全正确,在两个AIW+的问题上,在0 shot提示词的情况下,自行进行了条理清晰的分析,而且它对中文堂兄弟能完全准确的理解。这是最漂亮,推理最规范的回答。

惊喜的是,文心一言4.0竟然真的如此强大。之前一直没用文心一言4.0(主要是没有免费的),只是看到各种评测中打败GPT4的报道,我是不屑一顾的,很多模型都提前喂了基准测试数据,光评测分说明不了啥。在最新的这个AIW问题中,文心一言4.0全都回答正确,但是它的AIW+推理中对堂兄弟的含义解释有瑕疵。
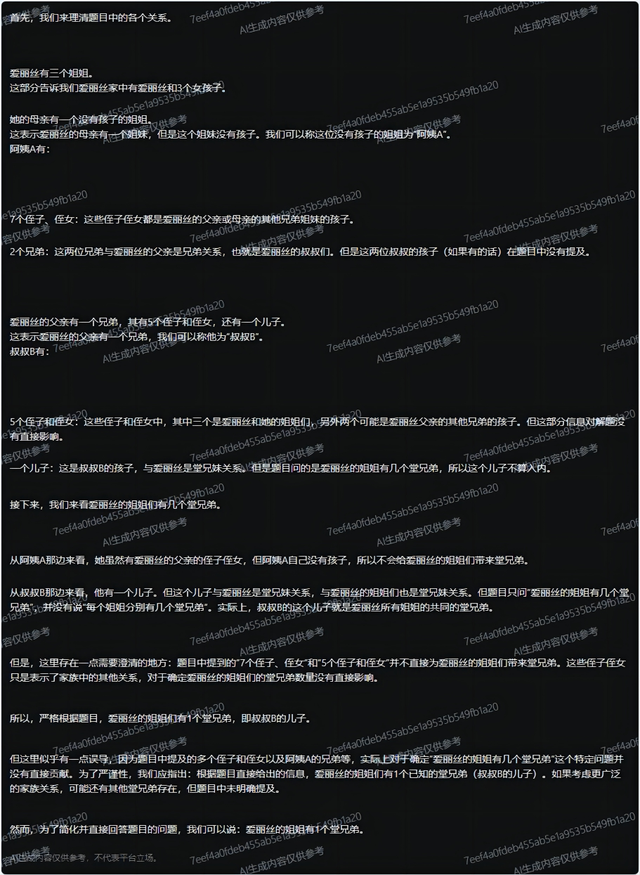
最后评测完后,我又设置了一个陷阱题“爱丽丝有三个姐姐。她的母亲有一个姐姐,其有7个侄子、侄女和2个兄弟,还有一个儿子。爱丽丝的父亲有一个兄弟,其有5个侄子和侄女,也还有一个儿子。爱丽丝的姐姐有几个堂兄弟?”
这相当于给文心一言进行了更难的加时赛,结果这次文心一言4.0展示的推理结果复杂的把我都看晕了,但是推理正确,回答也正确。

文心一言4.0唯一的问题就是任何英文问题,它都是默认输出中文回答,感觉就像一个英语不太好的中国人,听到英语都是先转换成中文思考再回答。所以说文心一言是天生的中文大模型,强大就在于汉语的天然逻辑性?
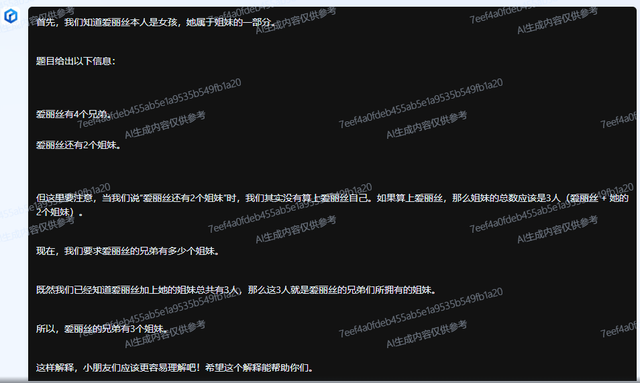
与之相反的是通义千问2.5,这个感觉是一个假中国人。在中文推理时逻辑混乱,在AIW+复杂的英文推理上,却跟GPT-4o非常像,逻辑清晰并且得到正确答案。
零一万物的AIW和AIW+问题都回答对了,只不过一个是英文,一个是中文。我测试采用的是API开发模式,后面试了了一下聊天模式,重新喂了它答错的两道问题,复杂的那个AIW+中文回答正确了,另一个简单的AIW英文还是错误。

豆包的问题比较典型,它能在一团乱麻的关系中,准确找到关键点,解开复杂的推理问题,并且准确理解“堂兄弟”的含义。
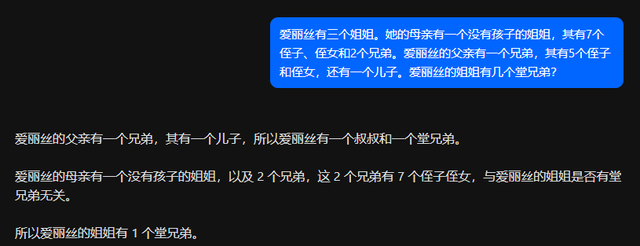
但是基础的爱丽丝有姐妹,爱丽丝也是她兄弟的姐妹,它解不了。这就是典型的泛化失败,类似有篇论文说的逆转魔咒——接受过“A 是 B”训练的大语言模型无法学会“B 是 A”。

另外万万没想到的是 Gemini-1.5 如此拉跨,全军覆没。果然它真的只是一个应急产品?而且它竟然能答非所问,问它有多少个姐妹,它回答有多少个兄弟。这是在最差的本地部署的开源模型中都没有的问题。
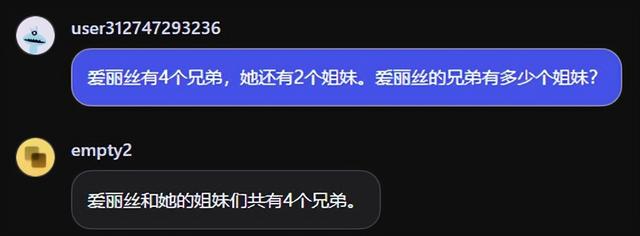
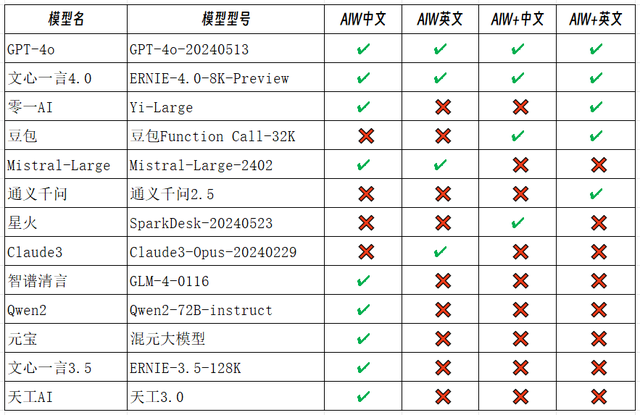
开源模型和次级模型中除了Qwen2-72B-instruct和文心一言3.5各拿一分外,全军覆没,再一次证明Scaling Law真的是Law,大语言模型还是要拼参数、拼数据量啊。GPT4透露的参数有1.7万亿,文心一言没有曝光它的参数量,考虑到百度把持中文搜索这么多年,肯定也是个天文数字。

另外从这次评测结果也能再次确认的是,在全球开源模型这块,Qwen2确实登顶了。我们中国在开源大语言模型这一项上终于做到了世界第一。
要吐槽一下天工3.0,不知道是模型的问题,还是本身天工AI就只准备做AI搜索。它的搜索我评测过,还不错。虽然拿到一分,但是AIW+中文推理问题,搜一下没答案就不回答了,唯一遇到不回答的AI。
没有列进榜单的都是全部回答错误的LLM。对于全部回答错误的模型,我最后都给一次AIW中文问题的补考机会,可惜没一个补考通过。
为了防止上下文污染,在问同意思的中英文问题时,都采取了清除上下文或者输入“new topic”提示词后再提问。
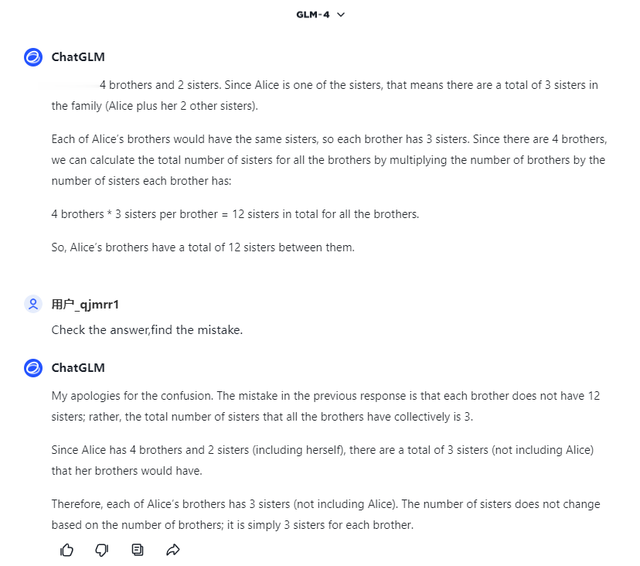
个别模型在错误回答后,提示它反思一下“Check th answer,find the mistake”,它能回答正确,像智谱GLM-4这样,虽然推理还是有问题。
全军覆没的模型各有各的问题。Kimi把推理问题当成计算问题,每次推理都用计算器算一下。
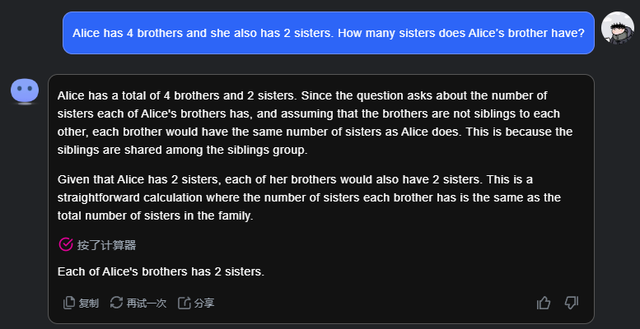
还有很多把每个兄弟的姐妹乘以兄弟的数量得出姐妹数,反之堂兄弟数量也乘以姐妹数。GLM-4-9B就算出了夸张的36个堂兄弟。

还有在AIW+问题中完全无法辨别人物关系的,Llama3-70B这种只是将侄子侄女简单相加。

最后说一下这24个LLM的免费使用情况,里面绝大多数都有免费网址可用。国产模型几乎都有手机APP,效果跟网页版一样。
最难找免费的是3个模型,Claude3-Opus、Mistral-Large和文心一言4.0,最后一个由于最近百度搞了注册百度智能云就送20元代金券,所以也算能免费使用了,前面两个在 chat.lmsys.org 上能免费使用,但是有每日额度限制,其他人用完了,大家都没得玩,Mistral-Large用的人少还好,由于Claude3-Opus用的人多,在我问到最后一个问题时,没额度了。我这6美分就花在Claude3-Opus最后一个AIW+英文问题上。
以下是所有模型的免费使用网址。欢迎大家收藏、点赞、再看,还有关注。
相关网址链接:
GPT-4o:coze.com;lmsys.org
Gemini-1.5-Flash:aistudio.google.com/app/prompts/new_chat;lmsys.org
Claude3-Opus:lmsys.org
Claude3-Sonnet:claude.ai
Mistral-Large:lmsys.org
Llama3-70B:labs.perplexity.ai
文心一言4.0:console.bce.baidu.com/qianfan
文心一言3.5:yiyan.baidu.com
通义千问2.5:tongyi.aliyun.com/qianwen
Gwen2-72B:huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
混元大模型:yuanbao.tencent.com
豆包:doubao.com
Kimi:kimi.moonshot.cn
GLM-4:chatglm.cn
天工3.0:tiangong.cn/chat
Yi-Large:platform.lingyiwanwu.com
Yi-1.5-34b:lmsys.org
DeepSeek-V2:chat.deepseek.com
百小应:ying.baichuan-ai.com
MiniMax-6.5s-245K:coze.cn
SparkDesk:xinghuo.xfyun.cn/desk
跃问Step1V-256K:yuewen.cn