今年以来,PC业界最大的风口毫无疑问就是“AI”了,从年初的Stable Diffusion AI绘画到后来的ChatGPT,仿佛一夜之间PC里沉寂已久的庞大算力找到了出头之日,各路热点关注纷纷涌向AI计算,各厂商一夜之间纷纷推出自己的模型,显卡价格暴涨,随后迎来制裁......看似热闹非凡,但是距离普通用户还是太远太虚幻,网上各种乱七八糟的APP,都号称能让普通用户也能体验AI功能——话里话外还是充钱!充钱!充钱!
那么,有没有能在自己家里电脑上就能简单部署的AI应用呢?还真有!其实ChatGPT和Stable Diffusion都有开源版本,可以非常简单的在本地部署,不过ChatGPT对于机器的算力配置以及存储要求都比较高,门槛不低,而且模型小了体验很一般,而Stable Diffusion就灵活多了,虽然要想跑爽还是需要强一点的CPU、显卡和大内存、大显存的,但是最低只需要集成显卡就可以跑!
今天在这里我就给大家介绍一下最简单、最省事的AMD显卡AI跑图教程!
需要什么配置?目前AI绘画基本上都是基于Github上的Stable Diffusion模型进行的(还有个付费的Midjourney),可以进行“文生图”、“图生图”等等神奇的功能,完全开源且免费,各种网上教的“AI绘画班”以及收费的“AI绘画工具”,不能说全都是骗人吧,至少绝大多数都是智商税,最复杂的部署和模型训练部分已经有无数大神做好了工作,只要机器配置满足要求,按着教程走就可以玩起来了!
那么大概需要什么样的配置呢?在发布之初,Stable Diffusion的配置要求还比较高,至少需要16GB以上的内存、主流级的CPU、10GB以上显存的N卡,这个要求不说挡住了99%,至少也挡住了90%的用户,毕竟以老黄的抠门程度来看,当时只有3060和3080、3090这几张卡能运行,而且3060还是空有显存,算力残废,在那会跑图很是费劲。但是经过一年时间不断迭代升级,目前Stable Diffusion已经支持从N卡、A卡甚至I卡,独立显卡到集成显卡,Windows、Linux甚至MacOS各种操作系统,硬件要求也低了很多,大概配置如下:
CPU:主流平台,原则上性能越强越好(非必须,如果不用显卡CPU硬跑也可以,但是真的很慢一张1-10分钟不等)
内存:越大越好
显卡:显存越大越好,独立显卡需要4GB以上显存,集成显卡需要16GB以上内存(集成显卡最好是Radeon 680M/780M,性能强些)
硬盘:最好是SSD
操作系统:Windows 11/10 21H2及之后版本,显卡驱动越新越好
说白了,如今的Stable Diffusion对硬件的要求已经很低了,只要不是N年前的上古电脑,5年内的中高端电脑,甚至这两年的一些笔记本电脑,独显只要有4G显存(狂牛!),集显只要是6800H/7840HS集成的Radeon 680M/780M以上,都可以跑(老APU的Vega也行,但是慢),与高端显卡的区别主要还是速度方面,本身只是输出图片的话对GPU性能要求不是特别高,但是对显存要求比较高。
目前SD对显存的要求大致区分4档:4G、4-8G、8-12G以及12G以上,越大的显存跑图时间越短,毕竟模型体积不小,如果能一次加载进显存中,就能大大减小加载模型的时间,否则只能多次加载,出图很慢——当然,显卡性能太差也不行,比如Intel的核显,虽然Iris Xe核显最高可以划分8GB内存用作显存,但是性能实在是太弱鸡,跑图速度就不行,还不如用CPU硬跑,而AMD的集成显卡Radeon 680M/780M就轻松很多。
那么什么显卡合适呢?从跑图的角度出发,因为本身瓶颈主要还是在显存上,显卡核心的优先级不是那么重要(当然还是越快越好),主要还是优先选显存大的!
当然,最快的显卡无疑是RTX4090 24GB了,不论是核心性能还是显存容量,都是民用市场绝对最强的存在,以至于太强被禁了......(PS:虽然听说老黄要出 二次阉割的RTX4090D来绕过监管,但是今天又听说还要封禁......总之不要抱太大希望)
那么如今能买到的卡皇是谁呢?是Radeon RX7900XTX 24GB!从跑图和AI应用的角度来说,同样拥有24GB海量显存的RX7900XTX也是相当优秀的,尤其是双11时候RX7900XTX一度降到6000出头的价格,以显存/价格来计算的话相当超值!(当然由于最近的禁令风云,新任卡皇RX7900XTX也有被抢购+涨价的趋势,且买且珍惜)
除此之外,再低一档就是A卡的二哥Radeon RX7900XT了,20GB显存同样具有优秀的AI性能,双11时候价格一度降到5000出头,对比同价位的N卡只有12G显存的4070TI,那真是不论核心性能还是显存上都大大落后了。
再往下的选择就多了,16GB显存有3000多的RX7800XT,12GB显存有2000出头的RX6750GRE,都是同价位性价比最高的存在——不是N卡不给力,实在是老黄的显存给得太抠门了,如今打游戏都不太够,哪里还给你跑AI的空间?连RTX4080都涨回9000了!虽然RTX4080跑图速度确实也很快,但是这个价格已经完全失去性价比了!
怎么玩?这里我测试使用的是蓝宝石Sapphire Radeon RX7900XTX 24GB超白金,目前最好的RX7900XTX非公版之一,最近蓝宝石又重开了京东自营,这下买起来放心多了。


对于Stable Diffusion的本地部署,这里有三套方案,效率依次提高,先说说最简单的:
整合包一键启动!(最省事,效率也相对较低)
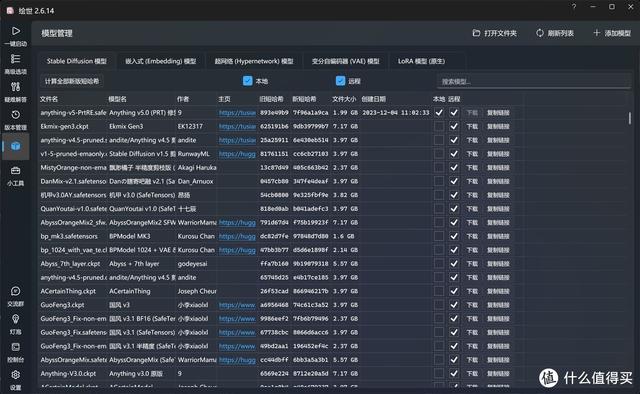
这里要首先感谢B站大佬,感谢大佬为大家带来了“绘世”一键整合包,直接下载适合A卡的整合包就可以轻松开始AI绘画了!
具体步骤如下:
①下载整合包,地址在;
②解压到英文目录位置,保险起见最好是放在某个盘根目录下;
③找到这个萌萌哒的图标:A启动器.exe,双击运行!

④启动器在联网状态下会自动更新,第一次启动还会提示启用Windows系统的长文件名支持,按照提示选择确定即可。另外还会需要安装微软.net 6.0运行库,如果是联网状态启动器会跳转相关网页自动下载,如果是离线状态的话可以在这里下载,拷到需要跑图的机器上安装即可。
⑤一切顺利的话就可以见到绘世启动器的主界面了!
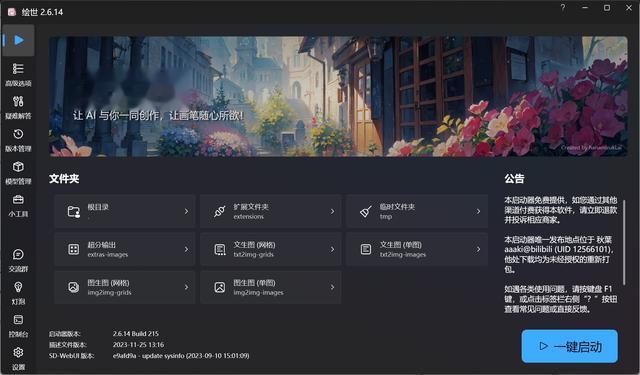
⑥先不要着急点击右下角的“一键启动”,因为默认设置不一定能跑起来,先来到第二页“高级选项”中,针对自己机器的配置稍微调整下:
其中,生成引擎可以选CPU和GPU两种,CPU就是硬跑啦,真的很慢,一张512×512的图大约需要3-5分钟不等,当然如果CPU足够强的话也不算慢,比如用7950X跑一张只需要1分钟,然而这个水平连Radeon 780M集成显卡都不如......所以还是用显卡吧!
显存优化选项根据显卡的显存情况设置,Radeon 680M/780M集成显卡建议设置成“低显存”,4-8G显存建议选择“中等显存”,8-12G建议选择“仅SDXL中等显存”,12G以上就选“无优化”即可,压线的显存容量比如8G、12G建议向下选一档,例如8G显存就选“中显存”,不然爆显存的话会报错。
Cross-Attention优化方案建议保持默认或者选择“自动”。
其余选项可以不动,设置完成后就可以点击“一键启动”了!
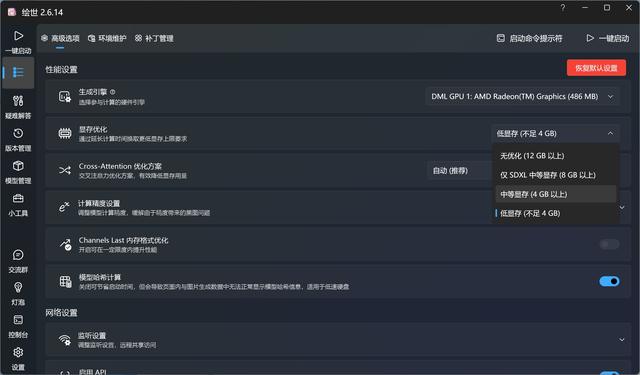
⑦正常启动后就会自动打开Stable Diffusion的Automatic111 UI界面,看起来是不是有点复杂?其实只简单生成图片玩玩的话很简单,上面那个大输入框是正面提示词,尽量用英文,也就是想生成图片的关键词,大致上分为质量控制和内容要求两类,比如“best quality”之类的就是控制质量的,而“girl,long leg”之类的就是负责内容的,这里就可以尽量发挥自己的想象力填写了,如果默认的模型里有相关内容,UI会提示的;
第二个大框里就是反向关键词,就是不想在图里出现的内容了,这里有个万能的负向关键词:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
(来自秋葉aaaki 大神的教程)
粘进反向提示词的框里,基本能满足90%的需要了。

填好关键词之后(其实不填也能出图,但是啥质量就不好说了),接下来点击旁边硕大的橙色“生成”按钮,稍等几秒~几十秒就会生成一张图啦!
关于关键词的选择,有很多教程,甚至还可以让ChatGPT帮你出,个人推荐,使用起来比较方便,直接选择合适的关键词复制即可。
默认是512×512大小精度,做个头像什么的足够用了,如果要大图需要改一下下面的大小参数,但是生成时间也是成倍增长的。
⑧想要生成其他风格的图片怎么办?默认的绘世启动器只带了基本的Stable Diffusion其中1套模型,只能满足基本的文生图需求,更多的需求就要增加不同的模型了:
绘世启动器里带了很多模型的链接,而且是国内镜像速度很快,关于额外的模型和其他参数怎么使用,这就说来话长了,有需要的可以自行搜教材和相关材料摸索。不过总体来说,如果只是尝试一下神奇的AI画图的话,前面①~⑦的步骤就足够了!
 再进一步?
再进一步?需要说明的是,大佬制作的一键整合包主要是为了我等小白用户使用,兼容性上非常好,但是基于PyTorch的模型效率很一般,再加上Windows的各种拖后腿,完全无法发挥出显卡的真实性能,因此这里再提供剩余2套方案的大致素材供参考:
Microsoft Olive速度起飞!默认绘世启动器带的模型效率一般,因此微软与AMD合作推出了Olive工具,可以把市面上大量基于PyTorch训练的模型转换为ONNX,基于DirectML来运行,效率提升不少,基本上可以使A卡达到同价位N卡的AI画图效率,但是这种方法就不能用绘世启动器来一键部署了,需要单独安装Git、Python和Anaconda或者Miniconda,这些都是比较好找的开发工具,能够自己部署这些工具的人大概也不需要我这篇教程,因此我只提供个思路,具体可以看这篇文章。
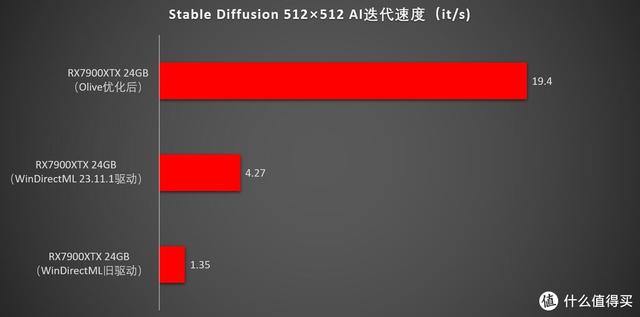
经过Olive优化之后,RX7900XTX可以跑出大约18-20it/s的速度,生成一张标准512×512图从原来的10秒左右提升到2-3秒左右,提升了3-5倍,还是相当可观的!(原文里还是早一点版本的模型,如今绘世启动器里带的模型用RX7900XTX跑一张图大约在3-5it/s左右)

需要说明的是,之前在网上搜到的AMD显卡跑图效率,基本都是旧驱动跑的,效率很一般,而且没有区分度,最高端的独立显卡RX7900XTX和集成显卡RX780M速度差别不大,都在1.X it/s徘徊,这明显不符合常理,一方面是当时Stable Diffusion的DirectML支持还不够完善,另一方面是老驱动对AI画图优化不够,毕竟这个东西才出来刚满一年。不过在今年11月初,AMD放出了新版的23.11.1驱动,驱动里重点说明了对AI画图功能的优化,主要就是使用DirectML在Stable Diffusion以及Lightroom、DaVinci等生产力软件上的性能,涵盖RDNA2以来的所有6000、7000系列独立显卡以及600、700M集成显卡。因此前面也说了,驱动要越新越好,毕竟最近1年来AI技术迭代速度,已经有点目不暇接了。

即便是不使用olive优化,新驱动在Windows+DirectML环境下,依然使用绘世启动器,就可以获得大约2-3倍的提升,使用RX7900XTX 24GB显卡时,一张512×512的出图时间从原来的大约30-50秒提升到10-15秒左右,效果非常明显!当然,还是比不过使用Olive进行优化后的性能,此时性能直追同价位N卡!
但是如果我说,这还不是A卡跑AI的完整性能呢?要想彻底释放性能,后面还有一招!
ROCm+Linux,彻底释放!而想要彻底释放显卡的性能,就得抛弃效率低下的Windows,改用效率极高的Linux了。在Linux下,装好Python+Anaconda或者Miniconda,部署Stable Diffusion,抛弃效率低下的DirectML改用ROCm跑CUDA,可以完全释放显卡的性能!这块的部署就太复杂了,小弟也没能力尝试,这里提供大神的教程供参考。
根据文章中的说法,一张RX7900XT 20GB生成512×512的图大约需要1.4秒,相较于上面的Olive方案又大约快了1-2倍左右,如果把默认的绘世启动器DirectML效率看成1x的话,Olive方案效率大约是3~5x,ROCm效率大约是8~10x,还是相当可观的!不过从普通用户来说,一张图10秒还是一张图2秒,区别都不是太大!大概对集成显卡和低端显卡用户意义比较大吧,重点还是创意和模型的使用,毕竟电脑只是工具,最重要的还是如何使用它!
