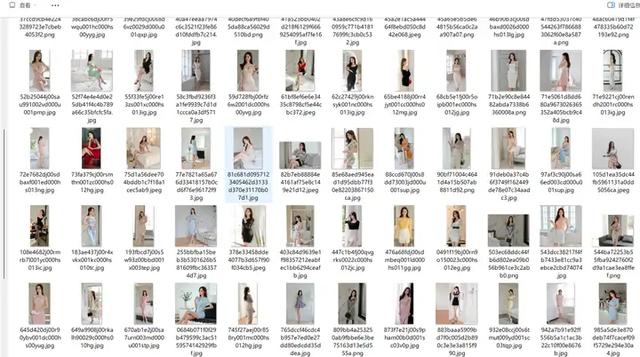
如何批量爬取下载搜狗图片搜索结果页面的图片?以孙允珠这个关键词的搜索结果为例:
https://pic.sogou.com/pics?query=%E5%AD%99%E5%85%81%E7%8F%A0&mode=2
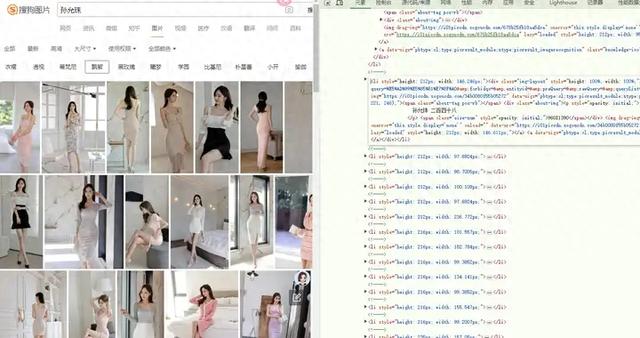
翻页规律如下:
https://pic.sogou.com/napi/pc/searchList?mode=2&start=384&xml_len=48&query=%E5%AD%99%E5%85%81%E7%8F%A0&channel=pc_pic
https://pic.sogou.com/napi/pc/searchList?mode=2&start=336&xml_len=48&query=%E5%AD%99%E5%85%81%E7%8F%A0&channel=pc_pic
https://pic.sogou.com/napi/pc/searchList?mode=2&start=288&xml_len=48&query=%E5%AD%99%E5%85%81%E7%8F%A0&channel=pc_pic
这三个URL都指向同一个服务,即搜狗图片搜索的API,用于获取孙允珠相关的图片搜索结果。它们之间的规律主要体现在查询参数 `start` 和 `xml_len` 上:
**start** 参数:这个参数控制了搜索结果的起始位置。在第一个URL中,`start` 的值是384,第二个URL中是336,第三个URL中是288。这表明每次请求的搜索结果是从前一次请求的结果之后开始获取的。例如,如果每页显示48张图片(由 `xml_len` 参数决定),那么第一个URL将从第8页开始(384 / 48 = 8),第二个URL从第7页开始(336 / 48 = 7),第三个URL从第6页开始(288 / 48 = 6)。**xml_len** 参数:这个参数指定了每次请求返回的图片数量,其值为48,意味着每次请求都会返回48张图片。**query** 参数:这个参数指定了搜索的关键词,这里是“孙允珠”,表示搜索与孙允珠相关的图片。**channel** 参数:这个参数指定了请求的渠道,这里是 `pc_pic`,表示这是一个针对PC端图片搜索的请求。总结规律:这三个URL通过调整 `start` 参数的值,实现了分页获取搜索结果的功能。每次请求都是从前一次请求的下一页开始获取图片,每次获取48张图片。这种设计允许用户或应用程序逐步加载更多的搜索结果,而不需要一次性加载所有结果,从而优化了数据加载的效率和用户体验。
返回的是json数据:
{
"status": 0,
"info": "ok",
"data": {
"adPic": [
{
"docId": "e154002750821088-37dc5468319bfb35-9215f4c834c26f0856ee7b118f22b559",
"index": 0,
"mfid": "128a42e5ea3535cd",
"thumbHeight": 1043,
"thumbWidth": 500
},
{
"docId": "abe1eea3ca79fc28-c577ebdcb0f3dbcc-a5f4cbbb2bfe711fad33ce48dce150b3",
"index": 1,
"mfid": "46ff91955836d2f8",
"thumbHeight": 767,
"thumbWidth": 499
},
{
"docId": "c286ca7ecc6f7a79-20248c558009c911-5d0f8afe47cd75de9dcce97d6d0e92d4",
"index": 2,
"mfid": "99a6652c227b8833",
"thumbHeight": 768,
"thumbWidth": 500
}
],
"blackLevel": 5,
"cacheDocNum": 48,
"hasPicsetRes": 0,
"isQcResult": "0",
"is_strong_style": 1,
"items": [
{
"anchor1": "",
"anchor2": [],
"anchor_extend": {},
"author": "http://pic.sogou.com",
"author_name": "",
"author_pageurl": "",
"author_picurl": "",
"author_thumbUrl": "https://i02piccdn.sogoucdn.com/0000000000000000_author",
"author_thumb_mfid": "0000000000000000",
"beauty": 7,
"biaoqing": 0,
"ch_site_name": "搜狐网",
"clarity": 5,
"content_major": "裙子的部分是一个直筒型的规划,简略直接的裙边线条调配上裙子内向缩短的规划,使裙子的风格偏向于简练,内敛的风格。别的延展至膝部的裙尾也遮盖了大部分腿部线条,调配浅褐色的使用,营建出了一种保守,庄雅的感觉。 衣服的外层有一个以腰部为支点,斜向的X型的面料系",
"cutBoardInputSkin": "c24c00231bcf459d|11|1718942349116|99418a699300bedc52a7df9b832a7aa0|http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20200212%2Fab9b05decd8d4b4eb39bb287cf0c14ad.jpeg",
"docId": "abe1eea3ca79fc28-c577ebdcb0f3dbcc-4b0aa372e8378eaa63bf649210d0bfc4",
"docidx": 96,
"gifpic": 0,
"grouppic": 1,
"height": 991,
"https_convert": 0,
"index": 0,
"lastModified": "1581484601",
"like_num": "0",
"link": "http://pic.sogou.com/d?query=%CB%EF%D4%CA%D6%E9&mode=2&mood=0&did=97&dm=0&id=abe1eea3ca79fc28-c577ebdcb0f3dbcc-4b0aa372e8378eaa63bf649210d0bfc4",
"locImageLink": "https://i02piccdn.sogoucdn.com/cf2dc47f12f2d0e9",
"mf_id": "cf2dc47f12f2d0e9",
"mood": "0x80",
"name": "ab9b05decd8d4b4eb39bb287cf0c14ad.jpeg",
"oriPicUrl": "http://5b0988e595225.cdn.sohucs.com/images/20200212/ab9b05decd8d4b4eb39bb287cf0c14ad.jpeg",
"painter_year": "",
"picUrl": "http://5b0988e595225.cdn.sohucs.com/images/20200212/ab9b05decd8d4b4eb39bb287cf0c14ad.jpeg",
"pic_norm_score": 0.998463,
"pic_porn_score": 0.000002,
"pic_sexy_score": 0.001535,
"pic_vulgar_score": 0,
"publish_time": "1581448740",
"publishmodified": "",
"rank": -100.9800033569336,
"size": 118807,
"summarytype": "NormalSummary",
"thumbHeight": 569,
"thumbUrl": "https://i02piccdn.sogoucdn.com/cf2dc47f12f2d0e9",
"thumbWidth": 499,
"title": "孙允珠 浅咖缠叠修身礼裙鉴赏",
"type": ".jpeg",
"url": "https://www.sohu.com/a/372330552_100198733",
"wapLink": "https://pic.sogou.com/pic/download.jsp?v=5&eid=1951&keyword=%E5%AD%99%E5%85%81%E7%8F%A0&index=97&groupIndex=96&xurl=https://i02piccdn.sogoucdn.com/cf2dc47f12f2d0e9&durl=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20200212%2Fab9b05decd8d4b4eb39bb287cf0c14ad.jpeg",
"water_mark_confidence": 0.78199702501297,
"width": 870,
"did": 97,
"scale": 0.8769771528998243,
"imgTag": "",
"bgColor": "#e3ddf6",
"imgDefaultUrl": "/d?query=%E5%AD%99%E5%85%81%E7%8F%A0&forbidqc=&entityid=&preQuery=&rawQuery=&queryList=&st=&channel=pc_pic&mode=2&did=97"
},
图片下载地址在 "picUrl"这个键的值中。
但是写了爬虫程序后,json数据爬取失败。仔细检查请求头,原来是里面加了时间戳:
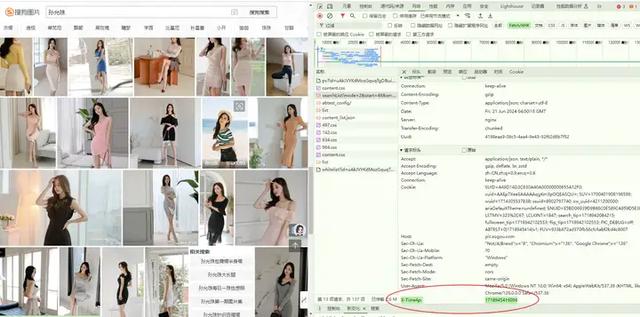
X-Time4p 是一个自定义的HTTP头部字段,通常用于传递与时间相关的信息。在这个上下文中,它可能被用来传递服务器处理请求的时间戳。不同的 X-Time4p 值表示不同的时间戳,这些时间戳对应于服务器处理不同请求的时刻。
例如,X-Time4p: 1718942347427 和 X-Time4p: 1718945416096 之间的区别在于它们代表了两个不同的时间点:
1718942347427 对应于服务器处理第一个请求的时间。
1718945416096 对应于服务器处理第二个请求的时间。
这两个时间戳之间的差异(大约3068677秒)表明服务器在处理这两个请求之间经过了多长时间。在Python脚本中,X-Time4p 的值应该与请求头中的其他字段一起设置,以模拟真实的浏览器请求。需要在不同的请求中使用不同的时间戳,因为要模拟不同时间点的请求,或者服务器可能期望看到不同的时间戳以正确处理请求。
在Python中生成时间戳,你可以使用内置的time模块中的time()函数。这个函数返回自1970年1月1日00:00:00(UTC)以来的秒数,这是一个常见的时间戳格式。
如果你想要生成类似于X-Time4p中使用的特定时间戳,你可以使用time.time()函数,然后根据需要调整返回的值。例如,如果你想要生成一个与给定时间戳相似的时间戳,你可以添加或减去一定数量的秒数。
'X-Time4p': str(int(time.time() * 1000)) # 生成当前时间的时间戳,单位为毫秒
在ChatGPT中输入提示词:
你是一个Python编程专家,写一个Python脚本,爬取网页图片:
请求网址:
https://pic.sogou.com/napi/pc/searchList?mode=2&start={pagenumer}&xml_len=48&query=%E5%AD%99%E5%85%81%E7%8F%A0&channel=pc_pic
{pagenumer}值从48开始,以48递增,一直到1008结束;
请求方法:
GET
状态代码:
200 OK
远程地址:
61.151.229.174:443
引荐来源网址政策:
no-referrer
请求标头
Accept:
application/json, text/plain, */*
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Connection:
keep-alive
Host:
http://pic.sogou.com
Sec-Ch-Ua:
"Not/A)Brand";v="8", "Chromium";v="126", "Google Chrome";v="126"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
empty
Sec-Fetch-Mode:
cors
Sec-Fetch-Site:
same-origin
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36
X-Time4p:{thistime}
{thistime}是一个时间戳,比如这样:1718945416096,要用str(int(time.time() * 1000)) 来 生成当前时间的时间戳,单位为毫秒;
请求响应是多层嵌套的json数据,输出这个json数据到屏幕上;
将 JSON 字符串解析为一个 Python 字典,首先获取 "data" 键对应的子字典,然后访问子字典中的 "items" 键,"items" 键对应的值是一个列表,获取所有列表中"picUrl"键对应的值 ,这是一个图片url,将url写入Excel表格第1列,Excel表格文件保存到文件夹:"C:\Users\dell\Pictures\孙允珠"
注意:每请求一个网页,随机暂停3-6秒;
每一步都输出信息到屏幕
源代码:
import requests
import json
import time
import random
from openpyxl import Workbook
# 设置请求头部信息
headers = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Host": "http://pic.sogou.com",
"Sec-Ch-Ua": '"Not/A)Brand";v="8", "Chromium";v="126", "Google Chrome";v="126"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
# Excel文件保存路径和文件名
excel_file = r"C:\Users\dell\Pictures\孙允珠\pic_urls.xlsx"
# 创建一个新的Excel工作簿
wb = Workbook()
ws = wb.active
ws.title = "Pic URLs"
ws.append(["图片链接"]) # 添加表头
# 定义生成时间戳的函数
def generate_timestamp():
return str(int(time.time() * 1000))
# 主程序逻辑
base_url = "https://pic.sogou.com/napi/pc/searchList"
start_pagenum = 48
end_pagenum = 1008
page_increment = 48
for pagenum in range(start_pagenum, end_pagenum + 1, page_increment):
try:
# 构建请求URL和参数
url = base_url + f"?mode=2&start={pagenum}&xml_len=48&query=%E5%AD%99%E5%85%81%E7%8F%A0&channel=pc_pic"
thistime = generate_timestamp()
headers["X-Time4p"] = thistime
# 发送GET请求
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
# 解析JSON响应
data = response.json()
# 输出JSON数据到屏幕上
print(f"获取到的 JSON 数据:\n{json.dumps(data, indent=2, ensure_ascii=False)}")
# 获取图片链接并写入Excel表格
if data and "data" in data and "items" in data["data"]:
items = data["data"]["items"]
for item in items:
pic_url = item.get("picUrl")
if pic_url:
print(f"图片链接:{pic_url}")
ws.append([pic_url]) # 写入Excel表格
else:
print("未找到图片链接")
else:
print("未找到data或items键")
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
# 随机暂停3-6秒
pause_time = random.uniform(3, 6)
print(f"随机暂停 {pause_time:.2f} 秒")
time.sleep(pause_time)
print("所有操作完成!")
# 保存Excel文件
wb.save(excel_file)
# 关闭Excel工作簿
wb.close()
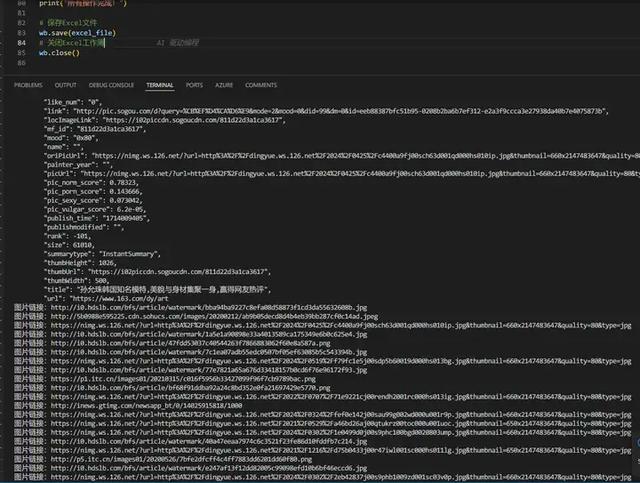
获取到图片下载地址,然后用迅雷批量下载,这样下载速度更快: