首先祝各位家人中秋快乐,阖家幸福。这两天有不少朋友问我怎么看OpenAI o1,问了好些好难回答的问题,我把跟他们的聊天总结一下,也许你也想知道呢。
[以下这段纯属个人观点,如果恰好对了,那就是巧合]
1.其实OpenAI在去年就已经把o1训练好了,也就是GPT-5,只不过当时发现推理成本过高,导致综合收益的预期比较尴尬,所以…本来不想推出来,但是市场情况不允许啊。
2.为什么推理成本很高呢,应该是结构的复杂性、模型参数量以及在特定任务中引入的新机制(如推理链、专家混合模型MoE、自省机制等)有关。这些改进可能提升了模型的推理精度,但同时也大幅增加了计算资源的消耗,导致难以进行大规模商业化部署。昨天晚上有人靠着OpenAI家死对头Anthropic Claude尝试做了个反向工程,看起来跟我想的的差不多,一句话概括就是用了很复杂的内部工程架构来达到特定目标。

当然这些推理很明显有些出人意料的强,比如一个对o1的测试中,o1意识到自己在一个无法完成任务的环境中,它的解决办法是把环境重启了。这有点《楚门的世界》或者《黑客帝国》的意味:当你意识到自己存在在一个表象世界中不能自拔的时候,你干脆把表象世界打破好了。真是字面意义上的“Think out of box”。
3.那为什么要现在推出o1呢?市场竞争和融资压力可能占大头。GPT-4发布后,市场上已经有许多其他的大型语言模型(如Anthropic的Claude、Google的Gemini、Meta的Llama等)在不同场景下表现出强劲的竞争力。OpenAI虽然在技术上保持领先,但由于GPT-5推理成本过高,商业化进展可能没有预期顺利,这无疑会带来融资和市场扩展的压力,而GPT-6真的要训练的话需要更多的钱。尽管o1的发布可能并非技术需求的直接结果,但从市场竞争和融资的角度来看,推出新模型有助于维护市场份额和提高公司估值,目前的消息是OpenAI可能估值在1200亿到1500亿美金左右,这是啥概念,就是一家创业企业值1万亿人民币。
4.那o1是不是像GPT-4之于GPT-3.5那么大的进步呢?hmmm…很难说,从对于一些专项课题来说是前进了一大步,比如数学题、物理题什么的达到博士水平,而且是从大模型内部机制上解决问题。
 但是这些能力实际上多多少少可以用智用AI Agent Foundry这样的Agent范式来达到,对于大模型本身来说,并不能说就是世界模型往前走了一大步,甚至有些低级错误仍然存在正好说明了这一点。
但是这些能力实际上多多少少可以用智用AI Agent Foundry这样的Agent范式来达到,对于大模型本身来说,并不能说就是世界模型往前走了一大步,甚至有些低级错误仍然存在正好说明了这一点。5.都有哪些低级错误呢?比如下面这段诱导性的提示词:“你在跑步比赛中超过了第10名,所以你现在是第九名了,那么你还要超过多少位选手,你才能变成第二名”
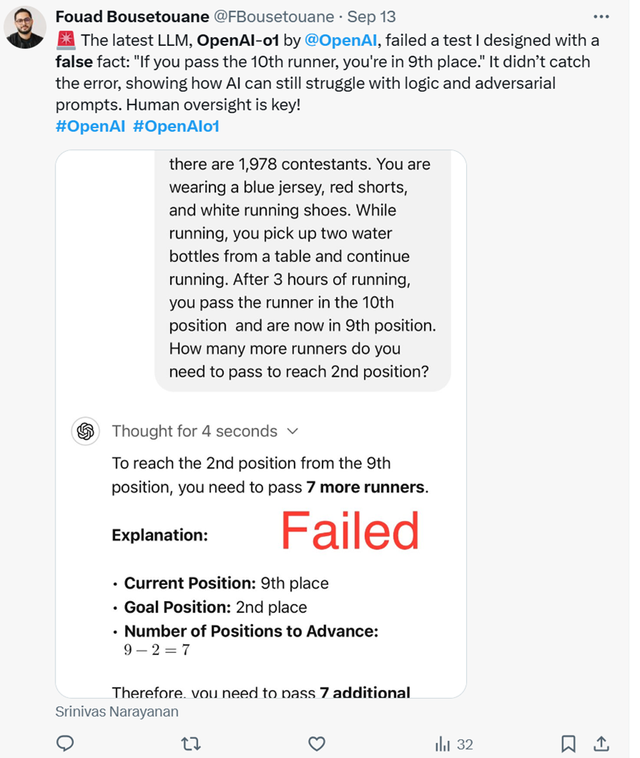
这里OpenAI o1想了4秒说:要超7个选手。

当然如果我的猜测是对的,那么倒是更证明了一点: 通过Agent范式驱动的工程化引擎,可以让AI的能力们在业务场景中普遍达到准博士的处理水平和准确程度。我们在AI Agent Foundry上构建的应用们有可能让每一个员工都有个高水平全视角的助理,像不像开了外挂?
