Fully Autonomous Programming with Large Language Models
Vadim Liventsev, Anastasiia Grishina, Aki Härmä , Leon Moonen
引用
Vadim Liventsev, Anastasiia Grishina, Aki Härmä, and Leon Moonen. 2023. Fully Autonomous Programming with Large Language Models. In Genetic and Evolutionary Computation Conference (GECCO ’23), July 15–19, 2023, Lisbon, Portugal. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3583131.3590481
论文:https://arxiv.org/abs/2304.10423
摘要
本文提出了SED,一种称为“合成、执行、调试”的方法来改进大语言模型进行程序合成时存在的“近似差错综合征”。该方法首先生成解决方案的草稿,然后添加了程序修复阶段来处理失败的测试。论文在实验中使用OpenAI Codex作为大语言模型,选取作为问题描述和测试的特定数据库进行评估。结果表明,最终的框架优于没有修复阶段的Codex和传统的遗传编程方法。
1 引言
自动编程自其诞生以来一直是人工智能领域的一个重要目标,目的是通过自动解决软件开发人员面临的一些任务来减轻其工作量。就在不久前,程序合成已经成为一种可解释的替代方法,与黑盒机器学习方法相比,它让人类专家能够理解、验证和编辑人工智能生成的算法。除了这种科学性知识的好处外,程序合成还将机器学习的好处扩展到如嵌入式系统等在技术上具有挑战性的一些领域,,以及如医疗保健等出于安全原因而避免使用机器学习的领域。
由于自动编程在零样本泛化方面具有显著的能力,其主要方法学已经从演绎式编程转向遗传和进化方向,再到基于源代码语料库训练的大型自回归语言模型。然而,即使是在特定类别的编程任务上进行了微调的最先进模型,仍然需要一个昂贵的过滤步骤,即丢弃LLM输出的不符合编译或通过测试的部分。尽管这些输出在表面上与正确解决方案相似,但却未能产生预期的输出,这种现象被称为“近似差错综合征”或“最后一英里问题”。
鉴于这些挑战,在源代码上的机器学习研究往往侧重于特定领域特定语言或自动化软件开发过程的特定部分,而不是在人类开发人员中流行的编程语言中进行完全自主编程。但最近的两项创新可能使后者的任务变得可行。一项创新是“合成、执行、调试”框架,它试图通过将程序修复引入到程序合成算法中来弥合“最后一英里”差距。编程任务使用自然语言描述和一组输入/输出(I/O)对来指定,展示了程序期望的输出,从而结合了文本到代码和编程示例的范式,这是竞争性编程中典型的范式。合成、执行、调试使用生成模型创建第一个草稿程序,使用给定的输入示例进行编译和执行。然后进行程序修复步骤来修复识别出的错误。另一个相关的创新是指令驱动的大型语言模型。指令驱动模型在其训练过程中使用人类反馈,并接受两个输入:源文本(或代码)和一条文本命令,指示模型以特定方式编辑源文本,例如“总结”或“翻译为Python”。这些模型在自动程序修复方面表现出色。然而,鉴于这些指令的自由形式,如何设计最大化修复性能的指令是一个悬而未决的问题。
总的来说,本文的贡献如下:
本文介绍了一个框架,将“合成、执行、调试”调整为指令驱动的大型语言模型,以自主方式解决编程任务。我们探讨了为有效地将这种框架应用于以指令驱动的LLMs,需要哪些提示作为LLMs的指令表现最佳,以及如何在修复失败程序和用新生成的程序替换之间取得平衡。我们通过实证方法探讨这些权衡,比较以替换为重点、修复为重点和混合调试策略,以及不同基于模板和基于模型的提示生成技术。我们选择大语言模型和问题数据集,在修复替换权衡和提示工程两个方向进行实验,证明本文提出框架对于先前技术的优越性。2 技术介绍
本文提出的框架Synthesize, Execute, Instruct, Debug and Rank,简称SEIDR,如图1所示,展示了解决一个编程任务的工作流程。为了解决一个编程任务,该任务由文本描述和一组输入/输出示例定义,我们将输入/输出示例分为提示集和验证集,并使用提示集在一个大型语言模型中合成候选解决方案。我们执行这些解决方案,对它们进行验证集测试,生成识别问题的文本描述,用于指导一个大型语言模型生成修复后的候选解决方案,类似于人类开发人员调试程序的方式。我们通过匹配输入/输出对来衡量正确性,对候选解决方案进行排名,丢弃最差的候选解决方案,并重复此过程,直到找到一个完全正确的解决方案。

图1:SEIDR框架工作流程
2.1 架构组成
SEIDR利用两个基于指令的大语言模型来处理源代码:合成模型、调试模型,以及可选的一个大型自然语言模型用于为代码模型编写指令。每个模型都是在大量多样化(即非特定任务)语料库上估计参数的高度参数化概率分布,覆盖(输入,指令)元组空间。语言模型的这种随机性质对于SEIDR是一个重要的先决条件,因为它允许我们从三个模型中抽样出多样化的候选解决方案批次。我们在实验中选择了最先进的变压器模型,一般情况下SEIDR需要一个序列到序列的生成模型来处理下面这些模块。
合成模块
SEIDR框架始于SYNTHESIZE块,其负责为后续SEIDR阶段修复的编程任务生成初始草稿解决方案。我们从一个选择的编程语言的基本模板开始,其中包含一些标准库导入和一个空的主函数或该语言的等效部分,见图2。我们用一个注释填充这个模板,指示手头任务的文本描述以及来自提示训练集的几个I/O示例。我们设计这些模板时考虑了语言模型的作者和之前工作的指导方针。然后,我们从中采样程序,将输入设置为填充的模板,将指令设置为问题描述。我们使用温度采样和单调递增的温度调度,近似相等通过批处理实现高效。因此,对于前几个程序的采样过程近似确定性地最大似然估计。最终,这种方法确保样本是多样的,但始终包含最有可能的程序。

图2 合成模块的结构
执行模块
在EXECUTE块中,程序将被编译(如果需要)并使用编程语言的标准工具启动。程序将针对验证集中的每个输入/输出对运行一次。其stdin流接收给定输入对中的所有输入行,其stdout和stderr流被捕获并保存。然后,我们以输出行的准确度作为程序的得分标准进行测量,其中O为预期输出,n = max{|O|, |stdout|}:
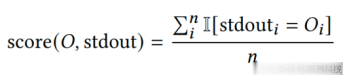
除非在编译或执行期间stderr非空,这被视为失败并分配得分为0。
指令模块
INSTRUCT块的目标是提供一条指令,总结候选程序中的一个bug,用于进行调试。带有bug摘要的结果指令应该指出哪些要求被违反,并指示LLM编辑候选程序,使其满足被违反的要求。
在SEIDR中,我们使用模板引擎生成指令。一般来说,模板引擎会将文件或字符串中的占位符替换为输入值,并返回格式化的字符串。通过模板引擎,我们可以创建多个模板,这些模板将根据程序候选执行结果动态调整。我们考虑指令生成模块的两种不同设计:INSTRUCT static和INSTRUCT LLM,如图3所示。这两种类型的模块都使用验证集中的失败输入/输出对和候选执行的stderr output。在这两个模块中,如果stderr不为空,即在获取输出以与预期输出进行比较之前发生执行错误,则基于stderr的模板引擎会生成一条指令,以修复stderr中提到的错误。然而,这两个模块在将失败的输入/输出对转换为指令生成方面存在差异,如果stderr为空的话。
INSTRUCT static使用固定的输入模板,并用第一个失败测试用例的相应字符串替换输入和输出的占位符。我们在图3中展示了一个示例模板的生成指令结果。相比之下,INSTRUCT LLM使用LLM中的失败输入/输出对进行文本完成,从而提示文本LLM生成bug摘要。图3中代码行为模板引擎的示例输出描述了代码返回输出O,而不是预期输出O val,对于输入字符串I val 的失败测试用例。然后,LLM被提示自动完成程序行为的描述与bug摘要。bug描述进一步传递给下一个模板引擎,并用作调试指令,例如“Fix{bug summary}”。
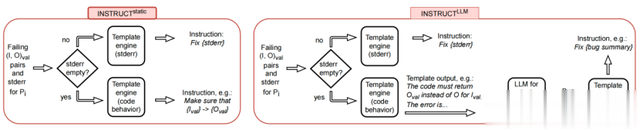
图3 带有和不带有LLM模型的INSTRUCT块
调试模块
DEBUG块迭代处理种群中的所有程序,并根据EXECUTE的结果使用由INSTRUCT编写的指令,从debug (input, instr)中采样N次,以修复每个候选程序,将输入设置为候选解决方案,指令设置为INSTRUCT的输出。然后,候选程序的种群被DEBUG的输出所替换。
排名模块
最后,RANK块实现了遗传编程中所称的父代选择,它通过在执行阶段计算的分数对候选种群中的所有程序进行排名,保留前W个程序,并将其余程序从种群中移除。
2.2 超参数的含义
在评估EXECUTE中给定的候选解后,SEIDR支持两种方法来解决候选解的缺陷:
用来自当前种群的另一个样本替换候选解。使用INSTRUCT和DEBUG修复候选解。类比于生产经济学,我们将这个问题称为修复-替换权衡(repair-replace trade-off)。选择超参数N和W如何影响SEIDR的流程?N和W作为替换选项的上限,限制种群的大小。如图4所示,在极端情况下,N = W = 1 对应于仅修复的过程,而N = W = ∞ 对应于仅替换的过程。观察到,具有种群大小W的仅突变的遗传算法,如SEIDR,在N元树上的宽度为W的局部波束搜索等效。这对应于局部波束搜索的已知属性:当W = 1时,它退化为深度优先搜索,而当W = ∞时,它产生广度优先搜索。因此,我们将N称为树的度,将W称为束宽度。
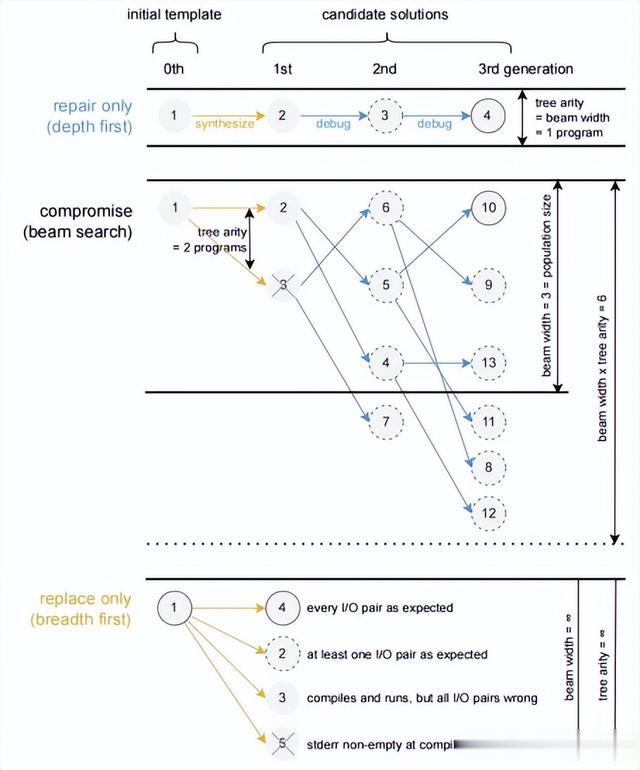
图4 将修复替换权衡问题视为一个树的搜索问题
3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下问题:
RQ1:在自主编程环境中使用不同的树搜索策略会产生什么影响?
RQ2:对比静态指令,使用LLM生成的错误摘要对自动生成代码的修复性能有何影响?
评估数据集。PSB2是一个包含25个程序合成问题的基准套件,这些问题类似于小型真实世界任务。PSB1由教科书问题组成,在遗传编程中被广泛使用,而PSB2被开发为PSB1的更现实和具有挑战性的版本。这些程序合成问题需要使用不同的数据结构和控制流来实现有效的解决方案,其来源于竞争性编程平台和教育课程等。这些问题有英文描述,以及100万个训练测试和100万个测试阶段测试,包括测试结果程序在复杂输入上的边缘或特殊情况。这些测试以I/O对的形式提供,并与问题描述一起作为PyPI软件包分发。在PSB1中,训练集由边缘测试用例组成,并且如果边缘测试用例数量不足,则会通过随机测试用例进行增补,测试集由随机测试用例组成,这种策略在PSB2中得以保留。然而,在我们的实验中,我们没有训练或微调阶段,因为模型不可用于进一步训练。相反,我们使用现有的预训练LLM对其代码和文本部分进行验证。因此,我们只有验证和测试阶段。在本研究中,我们将PSB术语中的训练测试用例称为验证测试用例。
对比方法。为了探索SEIDR的能力,我们在代码竞赛问题的基准测试中测试了该框架,使用不同类型的程序候选调试指令、不同的搜索策略以及两种语言,Python和C++。我们的实验使用了Program Synthesis Benchmark 2(PSB2)中的问题描述和测试来评估所提出的框架。我们将使用SEIDR合成的程序的性能与使用下采样词法选择的PushGP遗传编程系统进行比较。
评估指标。在我们的实验中,我们比较了使用不同超参数值的SEIDR获得的完全解决方案程序的数量。为了更详细地分析结果,我们使用了测试通过率(TPR)和多余生成的程序(EPG)。TPR反映了基于程序输出和测试输出的精确匹配的完全通过测试用例的百分比。TPR指标用于生成程序的最终评估,不反映I/O测试的部分通过,而是在RANK块中的得分。DEBUG和EXECUTE块生成了一些程序,在寻找解决方案程序的过程中被替换或修复。在第一次出现通过所有验证测试用例的程序之前生成的程序数量被称为EPG。EPG反映了解决问题的计算成本,以LLM推理和程序编译和执行的形式分布。
RQ1修复-替换权衡探索
实验设计。我们尝试了四种不同的树度数进行树搜索,并研究它们对已解决问题数量以及获得解决方案的速度的影响。我们比较了在树度为1、10、100和∞以及固定的Python和C++调试指令S0下实验中解决问题的数量,结果如图5所示。我们在图6中呈现了所有四个树度和固定默认调试指令的解决方案速度的类比。具体来说,我们展示了所有实验中EPG值的分布,以探索在找到解决方案之前生成了多少候选更新。我们放大了在图6a中找到解决方案的情况,这些解决方案在前10个程序候选中找到,并在图6b中显示了每隔100个候选程序的EPG分布。

图5 固定提示类型S0下树搜中解决的PSB2问题数量取决于树的分支度
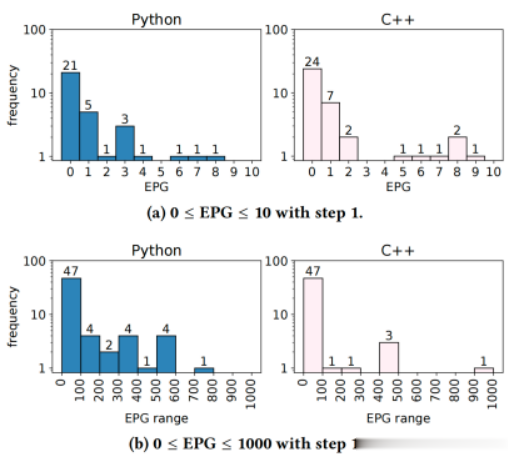
图6 在具有不同树分支度的实验中,解决了问题的问题解决尝试中生成的程序数量分布
结果。将SEIDR的结果与PSB2基准上PushGP的基准性能进行比较,PushGP在PSB2基准上解决了25个问题中的17个。需要注意的是,具有N = 1和N = ∞的实验可以被视为消融研究,其中替换选项和修复选项分别被关闭。
对于每种语言的100次实验中,在Python和C++中,有21-24%的运行中,草稿程序已经是解决方案(EPG=0)。在19-32%的实验中,解决方案在丢弃5个候选程序后被找到。大约一半的实验并未生成超过100个程序。然而,在Python中有5个问题是通过生成超过500个程序解决的,在C++中有1个问题(树度为10)。
分析。结果突出了树度为10和100的折衷策略相对于仅修复(N = 1)和仅替换(N = ∞)策略的好处,修复策略被其他策略超越。我们解释了修复策略表现不佳的原因在于搜索空间未被充分探索。具体来说,替换方案确保了在DEBUG阶段期间由我们实验中代表Codex-edit的用于调试的LLM生成不同的程序候选更新,使用可变温度。与N = 1相比,当在N > 1时生成更多的备选方案以更新草稿程序时,找到更好的修复的概率更高。具有N = 10的搜索策略产生了最佳结果:在C++中与PushGP表现相当,在Python程序合成期间优于基线,多出+2个问题,总共有19个程序通过了所有测试用例。结果表明,在DEBUG步骤期间并行生成适量的程序比生成更多更新以更新每个程序(100或1000)或仅迭代更新一个程序效果更好。在更新草稿程序的最初步骤对于解决问题至关重要。在搜索的后期阶段解决问题的机会,例如在生成了100个程序后,是很低的。这证实了我们的最初假设,即1000个程序是足够的。
回答RQ1,在Python中,SEIDR在PSB2上优于PushGP基线,并在C++实验中与树度为10的情况下表现相当。树度大于1的搜索策略受益于SEIDR框架的替换可能性,这是由于在Codex-edit中使用可变温度。修复组件对于框架也是至关重要的,因为仅替换搜索策略(树度为∞)的表现不如在程序更新期间交替使用替换和修复的策略(树度为10或100)。
RQ2 提示工程
实验设计。我们报告了使用不同静态和GPT辅助调试指令解决问题的数量,如图7所示。由于调试指令是LLM提示的一部分,且程序候选格式不变,因此在分析使用不同指令的实验结果时,我们将使用术语“提示”。为了分析不同提示对问题级别的影响,我们在图8中呈现了所有25个问题的EPG热图。我们将测试通过率的值以数字或符号形式添加,并以颜色显示EPG。空单元格表示由于OpenAI异常(例如APIError)而停止搜索。此外,如果框架在最大程序尝试之前停止(带有“-”的浅蓝色单元格),这是由于底层LLM debug 的输入长度限制,即生成的代码太长,无法作为LLM的输入。
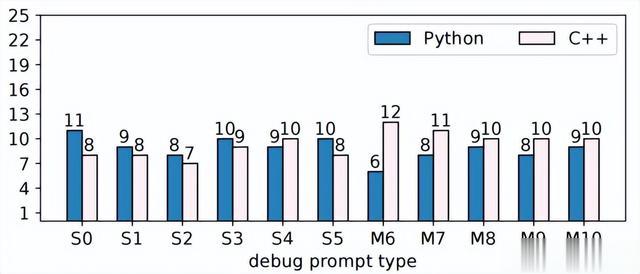
图7 根据固定的树分支度为1时指令选择的PSB2问题的解决数量
结果。总体而言,无论是LLM生成的还是静态模板,该框架对调试提示选择具有鲁棒性。在我们的实验中,Python和C++的解决问题数量有所不同。对于C++,除了S2指令外,所有调试提示的性能均与用于修复替换权衡实验中的S0指令相同或更高。调试指令S2包含“yield”和“ensure”这两个动词,这些动词在代码文档中可能很少使用。对于C++来说,最佳的调试指令是包含“obviously”一词的LLM辅助模板M6,这应该表明bug摘要的作者的信心,GPT-3在自动完成期间应该模仿这种信心。在Python程序中,在使用不同提示进行实验时,并未观察到相同的效果。总体性能与使用提示S0相比有所下降。在当前一组实验中,将生成的程序总数从1000减少到5,导致Python中使用S0失去了2个问题解决方案。对于EPG限制为5时,在C++中表现最佳的提示对应于Python中表现最差。

图8 解决问题的测试通过率
在图8中,根据调试提示类型,生成的过量程序数量(以颜色表示)和测试通过率(以数字表示)。较高的EPG值比较低的EPG色调更深。用“+”表示已解决的问题(测试通过率=1),用“-”表示未解决的问题(测试通过率=0)。如图8所示,一些问题使用所有提示解决,而其他问题仅使用提示子集解决,部分解决或根本未解决。许多问题在两种语言中使用所有或大多数提示解决,例如basement、fizz-buzz、paired-digits和twitter。其他问题仅在一种语言中通过所有测试,例如luhn、vector-distance、fuel-cost或substitution-cipher。大多数解决方案是作为第一稿或在1-2个调试步骤内生成的。然而,一些问题在第五步通过90%的测试用例,例如Python中的substitution-cipher使用提示S4和M8或C++中的shopping-list使用提示S0、S1、S5和M7。
分析。根据图7所示,这种结果可能是由于初始草稿的小树度和调试更新的低变异性。另一个原因是GPT-3的bug摘要可能不指向逻辑错误。文本自动完成模型经常输出提到“代码未正确接受输入”的bug摘要。请注意,这种bug摘要也出现在其他调试提示中。
根据图8所示结果,这些运行很可能会在接下来的几个步骤中更新为完全正确的程序,但出于提示间比较的公平性,实验被停止。或者,使用1000个最大程序进行提示工程实验将展示长期解决问题的有益提示,并可能成为未来工作的有趣方向。最有趣的情况涉及仅使用LLM bug摘要或仅使用静态提示解决的问题。例如,在C++中,gcd问题仅使用M6-M10提示解决,而不使用S0-S5中的任何一个。在spin-words和coin-sums中也获得了类似的结果。在Python中,我们观察到仅使用静态提示获得解决方案的情况,而不使用GPT辅助提示,例如find-pair、camel-case。此外,一些提示在S和M类别中均表现良好,例如Python中的gcd。
回答RQ2,在仅修复设置中,使用GPT辅助提示(总结代码中的bug)和描述失败I/O情况的静态模板,在C++中通过SEIDR进行的程序合成实现了更好的性能。最佳表现的C++指令是通过包含“obviously”一词的GPT-3进行文本补全获得的。对于Python中的PSB2解决方案,静态提示模板S0表现最佳。总体而言,SEIDR在提交给Codex-edit的不同调试提示下的性能稳定。
转述:刘佳凯
