传统的推荐模型(Conventional Recommendation Model,CRM)往往以Embedding+深度网络为backbone,通过拟合用户反馈信号提升推荐效果。CRM的主要特点是:
模型相对较小,时间空间开销低;可以充分利用用户反馈信号;只能利用数据集内的知识;缺乏语义信息和深度意图推理。相对的,大语言模型(LLM)以Transformer为backbone,通过大规模预训练语料和自监督训练提升通用语义理解和生成能力。LLM的主要特点是:
引入外部开放世界知识,语义信号丰富;具备跨域推荐能力,适合冷启动场景;用户反馈信号缺失;计算复杂度高,难以处理海量样本。因此,一个核心问题是推荐模型如何从大模型中取长补短,从而提升推荐性能,优化用户体验?
为了解答这一问题,作者从应用角度出发,将该问题进一步拆解为:
何处运用大语言模型(WHERE to adapt)如何运用大语言模型(HOW to adapt)
下面会围绕这两个方面来展开介绍。
2、何处运用大语言模型:WHERE to Adapt根据现代基于深度学习的推荐系统的流程,作者抽象出以下五个环节:
数据采集阶段:线上收集用户行为和记录,得到原始数据(raw data);特征工程阶段:对原始数据进行筛选、加工、增强,得到可供下游深度模型使用的结构化数据(structured data);特征编码阶段:对结构化数据进行编码,得到对应的稠密向量表示(neural embeddings);打分排序阶段:对候选物品进行打分排序,得到要呈现给用户的排序列表(recommended items);流程控制:作为中央控制器,把控推荐系统的整体流程。也可以细化到对排序阶段的召回、粗排、精排的控制。大模型主要可以从特征工程、特征编码、打分排序和流程控制这几个部分来提升推荐系统的表现,对应的最近几年的工作如下图所示:
 2.1、特征工程
2.1、特征工程现有工作中,LLM在特征工程阶段主要发挥如下作用:利用大语言模型的外部通用知识和逻辑推理能力,进行:
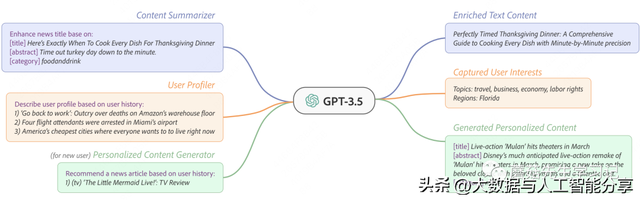
用户理解:利用LLM丰富用户画像,代表工作有GENRE、PALR、NIR等;内容理解:利用LLM进行item画像抽取,代表工作有GENRE、OpenRec等;样本扩充:利用LLM进行item生成,代表工作有AnyPredict、GENRE等。代表性工作1:GENRE(PolyU, 2023)代表性工作GENRE[3],出自香港理工大学,
同时涉及了用户理解、内容理解和样本扩充三个方向。

GENRE 基于GPT3.5进行新闻推荐:
内容理解:输入新闻标题、摘要、类目信息,生成简短内容描述;用户理解:输入用户历史行为数据,生成用户感兴趣的话题和区域;样本生成:对于历史行为数据稀疏的用户,基于少量行为样本生成相似的伪样本,用于扩充用户表征输入。GENRE框架示意图:基于已生成伪样本增强用户理解,然后再生成更准确的伪样本。

通过prompting增强样本的过程示意:
整体架构:

2.2、特征编码利用LLM的通用语义信息丰富推荐特征表示:
增强文本特征(用户表征、物品表征) 表示,代表工作有PLM-NR、UniSeqRep、VQ-Rec、PREC、U-BERT、UNBERT等;改善基于ID的特征表示的跨场景迁移能力。
 代表性工作2:U-BERT(Tencent, AAAI 2021)
代表性工作2:U-BERT(Tencent, AAAI 2021)代表性工作2:U-BERT: Pre-training user representations for improved recommendation[4] 出自Tencent, AAAI'21,基于大模型进行用户表征学习。
背景:电商推荐系统中如何使用用户和item侧丰富的文本特征技术方案:Review Encoder:基于BERT对用户所写的评价进行语义编码;User Encoder:基于attention网络对review token表征进行聚合;两个子任务,rating & MLM。输入:用户历史交互行为以及购买后的评价信息;预训练阶段微调阶段(训练):增加item侧编码网络,拟合用户反馈数据。U-BERT预训练阶段:

U-BERT微调阶段:
 代表性工作3:UniSRec(Alibaba, KDD 2022)
代表性工作3:UniSRec(Alibaba, KDD 2022)代表性工作3:UniSRec: Towards universal sequence representation learning for recommender systems[5],出自RUC&Alibaba, KDD'22,基于item文本信息进行序列模型预训练,实现跨域推荐的目标(inductive learning)。
Universal Textual Item Representation:基于BERT对item文本信息编码,通过MOE Adaptor实现跨越样本的Domain Fusion and Adaptation;Universal Sequence Representation:基于MHA对序列信息进行聚合;预训练阶段:对比学习任务,Sequence-sequence contrastive task & Sequence-item contrastive task;微调阶段(新领域):inductive/transductive,fix parameter加速微调。
此外,KDD2023 Amazon的Text Is All You Need: Learning Language Representations for Sequential Recommendation,也属于该路径下的代表性工作。
2.3、打分排序打分/排序是推荐系统的核心任务,目标是得到和用户偏好相符的物品(列表)。根据如何得到最终排序列表的形式,作者将大语言模型应用于打分/排序的工作分成以下三种:
物品评分任务(Item Scoring Task):大语言模型对候选物品逐一评分,最后根据分数排序得到最终的排序列表;物品生成任务(Item Generation Task):通过生成式的方式生成下一个物品的ID,或者直接生成排序列表;混合任务(Hybrid Task):大语言模型天然地适合多任务场景,因此很多工作会利用大语言模型来实现多个推荐任务,其中包括评分任务和生成任务。代表性工作4:Google LLM+评分预测任务代表性工作4:Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction(Google, 2023)[6]
探究语言模型分别在零样本(Zero-Shot),少样本(Few-Shot)和微调场景下的评分预测的能力;基于用户反馈数据进行LLM微调;结论:zero-shot vs statistics:指标基本可比,说明LLM在推荐任务上有一定的zero-shot能力;zero-shot vs few-shot:few-shot在AUC指标上胜出,说明few-shot有一定的提升作用;fine-tuned LLM vs 传统模型:AUC胜出,说明LLM有用作推荐模型的潜力。零样本和少样本prompt示例:

LLM微调:

实验结果:
 代表性工作5:PALR (Amazon, 2023)
代表性工作5:PALR (Amazon, 2023)PALR: Personalization Aware LLMs for Recommendation[7]
利用用户历史交互得到用户画像,然后基于用户画像、历史交互和提前过滤得到的候选集信息生成推荐列表;经过指令微调,PALR在公开数据集上显著超过传统推荐模型baseline。
prompt例子:
 代表性工作6:P5(Recsys, 2022)
代表性工作6:P5(Recsys, 2022)Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)[8]
用一个统一的大语言模型在不同的推荐任务上进行预训练,针对不同任务使用不同推荐模版;用自然语言为桥梁,规范不同推荐场景的输入输出,并在跨域样本上进行预训练,具备新场景下的zero-shot迁移能力。
也可详见我以前的解读:P5 | NLP模型一统推荐系统? 谈新型推荐系统建模范式
2.4、流程控制代表性工作7:RecLLM,Google 2023Is chatgpt fair for recommendation? evaluating fairness in large language model recommendation[9]
提出了一种使用LLM来集成推荐系统流程各模块(检索、排序、用户画像、用户模拟)的一个对话式推荐系统路线图。

3、如何运用大语言模型从训练和推理两个阶段出发,作者根据以下的两个维度将现有工作分为四个象限:
在训练阶段,大语言模型是否需要微调。这里微调的定义包含了全量微调和参数高效微调。在推理阶段,是否需要引入传统推荐模型(CRM)。其中,如果CRM知识作为一个预先过滤candidate的作用,则不被考虑在内。
由上图可以发现两个趋势:
模型:通过引入传统推荐模型(CRM)为语言模型注入协同信号。数据:通过引入推荐场景的数据,结合微调技术,为语言模型注入协同信号。3.1、不微调LLM、引入CRM研究怎么把推荐模型的信号引入LLM,但是不进行LLM的微调,代表性工作KAR。
代表性工作8:KAR(SJTU, 2023)Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models.[10]
背景:LLM具备强大的语义理解和推理能力,可以帮助推荐系统完成用户理解(推理能力)和item理解(理解能力)。为此提出了一种利用大语言模型开放知识辅助推荐的通用推荐框架KAR。
难点:
大语言模型的构成差距问题(Compositional Gap) 无法准确回答复合推理问题,但可以准确回答复合问题的各个子问题;用户偏好复杂多面,世界知识混合海量,难以直接生成有效知识。
解法:受因式分解的启发,将开放知识生成问题动态分解为多个关键子因素,按因素分别进行用户兴趣推理和知识提取。
技术方案:
知识推理和生成基于推荐场景对于决定用户偏好,动态分解出相应的关键因素,对于用户偏好和物品外部知识分别对大语言模型提问;生成相应的兴趣推理知识和物品事实知识文本。知识适配:所生成的文本信息内容复杂多面(500~1000 tokens),且存在噪声和冗余问题,推荐系统无法直接理解和利用设计多专家网络进行知识提取、压缩、映射,适配至推荐空间,输出结果鲁棒。知识利用:将所生成的知识增强向量作为额外的特征域,结合原本数据特征,进行特征交互,输出最终结果。效率问题:预存用户长期兴趣(或向量)和item知识(或向量),LLM不建模用户短期兴趣。
prompt工程:

系统架构:

实验:

总结下方法创新性:
有效结合大语言模型的通用世界知识与传统推荐系统的领域知识:通过Factorization Prompting,有效激发大语言模型针对用户兴趣的推理和知识获取能力,缓解构成差距的问题。提出混合多专家网络知识适配器,将语言模型生成的世界知识由语义空间适配至推荐空间,进行降维、噪声处理的同时保存有效信息。推理复杂度与传统推荐模型一致。3.2、微调LLM、引入CRM研究怎么把LLM和推荐系统模型结合起来,让LLM也能拥有协同信号。代表性工作CTRL。
代表性工作9:CTRL(Huawei, 2023)CTRL: Connect Tabular and Language Model for CTR Prediction[11],Huawei 2023
背景:仅使用语言模型进行推荐目前效果不理想,需要通过引入推荐场景的数据,结合微调技术,为语言模型注入协同信号。为此,华为提出了一种对齐语言模型和协同模型的框架CTRL。
具体技术方案:
Prompt construction:通过7个模板把表格数据转换为文本数据。用户和物品特征:特征名+连接词+特征值。用户历史行为序列:用户的历史类型+动作连接词+历史1|历史2|历史3。采用','作为特征之间的分隔符;采用'.'作为用户信息和物品信息的分隔符。Cross-model Knowledge Alignment:将协同模型和语言模型的知识进行对齐。利用对比学习预训练融合两种模态的信息。Supervised Finetuning:在经过细粒度对比学习预训练之后,两种模态的信息已经进行充分融合。使用监督信号使协同模型适配下游任务。通过在不同的任务上微调,可以适配不同的推荐任务。Serving:仅使用更轻量的传统模型进行serving,不会对RT造成影响。
实验:

总结下方法创新性:
以混合粒度知识对齐的方式,同时建模协同信号和语义信号;从数据角度进行双向知识注入,语言模型与推荐模型互相解耦;可以单侧推理,推理复杂度低。4、挑战和展望4.1、工业应用场景下的挑战训练效率问题:显存用量过大、训练时间过长可能解决思路:1. 参数高效微调(PEFT)方案;2.调整模型更新频率(e.g.长短更新周期结合)推理时延预存部分输出或中间结果,以空间换时间;通过蒸馏、剪枝、量化等方法,降低推理模型的真实规模;仅用于特征工程和特征编码,避免直接在线上做模型推理问题:推理时延过高可能解决思路:推荐领域的长文本建模问题:长用户序列、大候选集、多元特征都会导致推荐文本过长,不仅难以被大模型有效捕捉,甚至可能会超过语言模型的上下文窗口限制(Context Window Limitation)可能解决思路:通过过滤、选择、重构,提供真正简短有效的文本输入ID特征的索引和建模问题:纯ID类特征(e.g. 用户ID)天然不具备语义信息,无法被语言模型理解可能解决思路:探索更适合语言模型的ID索引和建模策略4.2、展望现有的语言模型在推荐系统中的应用存在以下两个发展趋势:
突破传统定位,重塑推荐流程:LLM在推荐系统中扮演的角色逐渐突破传统定位,从简单的编码器、打分器逐渐向外延伸,在特征工程,乃至推荐流程控制都发挥重要作用;语义协同兼顾,跨域知识融合:需要通过微调大语言模型(数据层面)或引入传统推荐模型(模型层面)的方式来为语言模型注入推荐的域内知识。LLM未来有可能在推荐系统中发挥重要作用的环节:
缓解稀疏场景:LLM的zero-shot和few-shot能力可以用于解决冷启动和长尾问题;引入外部知识:LLM拥有大量关于Item的世界知识,对于资讯类场景这种通用知识的引入可以大大丰富Item侧的信息;改善交互体验:用户可以主动通过交互式界面自由地描述他们的需求,从而实现精准搜索推荐。参考[1] Lin J, Dai X, Xi Y, et al. How Can Recommender Systems Benefit from Large Language Models: A Survey[J]. arXiv preprint arXiv:2306.05817, 2023.
[2] https://github.com/CHIANGEL/Awesome-LLM-for-RecSys
[3] Liu Q, Chen N, Sakai T, et al. A First Look at LLM-Powered Generative News Recommendation[J]. arXiv preprint arXiv:2305.06566, 2023.
[4] Qiu Z, Wu X, Gao J, et al. U-BERT: Pre-training user representations for improved recommendation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(5): 4320-4327.
[5] Hou Y, Mu S, Zhao W X, et al. Towards universal sequence representation learning for recommender systems[C]//Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2022: 585-593.
[6] Kang W C, Ni J, Mehta N, et al. Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction[J]. arXiv preprint arXiv:2305.06474, 2023.
[7] Chen Z. PALR: Personalization Aware LLMs for Recommendation[J]. arXiv preprint arXiv:2305.07622, 2023.
[8] Geng S, Liu S, Fu Z, et al. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5)[C]//Proceedings of the 16th ACM Conference on Recommender Systems. 2022: 299-315.
[9] Zhang J, Bao K, Zhang Y, et al. Is chatgpt fair for recommendation? evaluating fairness in large language model recommendation[J]. arXiv preprint arXiv:2305.07609, 2023.
[10] Xi Y, Liu W, Lin J, et al. Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models[J]. arXiv preprint arXiv:2306.10933, 2023.
[11] Li X, Chen B, Hou L, et al. CTRL: Connect Tabular and Language Model for CTR Prediction[J]. arXiv preprint arXiv:2306.02841, 2023.
