Commitbert: Commit message generation using pre-trained programming language mode
Tae-Hwan Jung
引用
Jung T H. Commitbert: Commit message generation using pre-trained programming language model[J]. arXiv preprint arXiv:2105.14242, 2021.
论文:CommitBERT: Commit Message Generation Using Pre-Trained Programming Language Model
摘要
这篇文章主要介绍了一种使用预训练的编程语言模型生成提交消息的方法,以解决人工编写提交消息的困难。文章提出了数据收集方法、模型构建方法和性能改进方法,并展示了使用这些方法生成提交消息的成功结果。作者指出,尽管可以使用预训练模型生成高质量的提交消息,但未来的研究仍需深入理解代码语法结构。文章的结论是,这项工作可以帮助那些即使使用应用程序也难以编写提交消息的开发人员。
1 引言
提交信息是用自然语言总结源代码更改的最小单位。一个好的提交信息可以让开发人员一目了然地将提交历史可视化,因此许多团队试图通过为提交信息创建规则来进行高质量的提交。例如,常规的Commits 1是提交规则之一,对第一个单词使用指定类型的动词,如“Add”或“Fix”, 并限制字符的长度。要遵循所有这些规则并写出一个高质量的提交信息是非常棘手的,因此许多开发人员由于缺乏时间和动机而忽略了它。因此,如果在给出代码修改时自动编写提交消息将是非常高效的。
与文本摘要类似,许多研究都是通过取代码修改X = (x1,…, xn)作为编码器输入和提交 消息Y = (y1,…, ym)作为基于NMT(神经机器 翻译)模型的解码器输入。然而,在不区分添加和的情况下进行代码修改将被删除的部分作为模型输入使得很难理解NMT模型中修改的上下文。
此外,以往的研究在训练模型时倾向于从零开始训练,但这种方法在编程语言(PL)和自然语言(NL)之间的上下文表示上存在很大的差距,因此表现不佳。为了克服以往研究中的问题并训练出更好的提交消息生成模型,我们的方法遵循两个阶段:
(1) 用代码中添加和删除部分的对来收集和处理数据X = ((add1, del1),…, (addn, deln))。 为了将该对数据集纳入基于transformer的NMT模型,我们使用BERT对由添加和删除部分组成的两个句子对进行微调方法。这显示了比以前 使用原始git diff的作品更好的BLEU-4分数。 与 Code-SearchNet 类似,我们也从Github收集了六种语言(Python, PHP, Go, Java, JavaScript和 Ruby)的数据,以显示各种语言的良好性能。我们最终发布了345K代码修改并提交了消息对数据。
(2) 为了解决编程语言(PL)和自然语言(NL) 在上下文表示方面的巨大差距,我们使用 CodeBERT作为初始权值,CodeBERT是一种在代码域经过良好训练的语言模型。使用Code-BERT作为初始权值表明, BLEU-4在提交消息生成方面的得分优于使用随机初始化和RoBERTa。此外,当我们预训练code -to-NL任务以在CodeSearch Net中记录源代码并使用提交生成的初始权重时,PL和NL之间的上下文表示进一步减少。
2 技术介绍
2.1 基于编码器-解码器模型的文本摘要
随着序列到序列学习(Seq2Seq) 的出现,源域和目标域之间的各种任务正在得到解决。文本摘要就是其中一项任务,通过使用更先进的编码器和解码器的Seq2Seq模型显示出良好的性能。编码器和解码器模型通过最大化下面的条件对数似然来训练,基于源输入X = (x1,…, xn)和目标输入Y = (y1,…ym)。
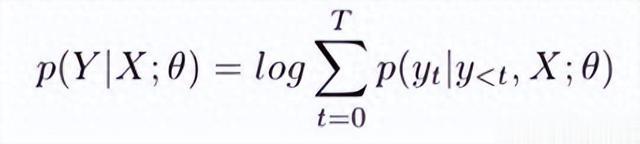
其中T是目标输入的长度,y0是开始token, yT 是结束token,θ是模型的参数。在 Transformer模型中,源输入通过自注意力(self-attention)作为编码器层数被矢量化为隐藏状态。在此之后,目标输入也通过自注意力和对编码器隐藏状态的注意力来学习生成分布。它比现有的基于rnn的模型显示出更好的汇总结果。
为了提高性能,大多数机器翻译使用波束搜索。它在每一步都保留K个最可能的标记来搜索区域,并搜索下一步以生成更好的文本。当预测的yt是一个结束标记或达到最大目标长度时,生成停止。
2.2 CodeSearchNet
CodeSearchNet是一个用自然语言搜索代码函数片段的数据集。它是六种编程语言(Python, PHP, Go, Java, JavaScrip t和Ruby)的代码函数片段的配对数据集,以及用自然语言汇总这些函数的文档字符串。从具有重新分发许可证的项目中收集了总共6M个配对数据集。利用CodeSearch-Net语料库,可以解决检索由自然语言组成的查询所对应的代码。此外,还可以通过用自然语言(code - to-NL)进行总结来解决记录代码的问题。
2.3 CodeBERT
最近的NLP研究通过包括预训练和微调的迁移学习在各种任务中显示了最先进的技术。特别是BERT是一种预训练语言模型,通过随机掩码序列输入预测掩码单词,并且仅使用基 于Transformer的编码器。它在各种数据集上都表现出了良好的性能, 现在正在从自然语言领域扩展到语音、视频和代码领域。CodeBERT是一种代码领域的预训练语言模型,用于学习编程语言(PL)和自然语言(NL)之间的关系。为了学习不同域之间的表示,他们参考了ELECTRA的学习方法,该方法由生成器-判别器组成。NL 和代码生成-用于从代码标记和注释标记中预 测以特定速率屏蔽的单词。最后,NL-Code Discriminator是经过二值分类训练后的 CodeBERT,可以预测它是重新放置的还是原始的。CodeBERT对代码域中的所有任务都显示 出良好的结果。特别是在代码到自然语言 (code -to-NL)和使用CodeSearchNet语料库从 NL中检索代码的任务中,它显示出比其他预训练模型更高的分数。此外,CodeBERT使用 RoBERTa中使用的字节对编码(BPE)到kenizer,并且不会在代码域输入中生成unk令牌。
2.4 数据集
我们收集了一个345K的代码修改数据集,并在Github上从六种编程语言(Python、PHP、 Go、Java、JavaScript和Ruby)的52K存储库中提交消息对。当使用原始的git diff作为模型输 入时,很难区分添加和删除的部分,因此与Jiang和McMillan(2017)不同,我们的数据集只关注git diff中添加和删除的行。
详细的数据收集和预处理方法如算法1中的伪代码所示:
算法1:

为了只收集可重新分发许可证的代码,我们在CodeSearchNet数据集中列出了Github 存储库名称。之后,所有的仓库都是通过多线程进行克隆的。存储库中收集提交哈希值的函数和代码modifi-的详细描述commit hash中的阳离子如下所示:
get_commits是一个从仓库中获取提交历史的函数。此时,主分支的提交被过滤,不包括合并提交。6程序语言(.py, .php, . js, .java, .go, .ruby)扩展对应的代码修改的提交被收集。为了实现这一点,我们使用了开源的pydriller。get_modification是一个函数,用于获取提交中修改的行。通过这个函数,可以只收集添加或删除的部分,而不是所有git diff。在收集pair数据集的同时,我们发现了一些代码修改之间的关系并且相应的提交信息是模糊和非常抽象的。此外,我们检查一些代码修改或提交消息是一个没有意义的虚拟文件。为了过滤这些,我们创建了过滤函数和如下规则:
为了收集各种格式发行版的提交信息,我们限制在一个仓库中最多收集50个提交。我们过滤每个提交消息中更改的文件数量为 1个或2个的提交。带有问题号的提交信息被删除,因为详细信息是缩写的。与Jiang和McMillan(2017)类似,非英语提交消息被删除。因为有些提交消息非常长,所以只获取第一 行。如果通过解析器生成器工具tree-sitter3的代 码标记超过32个字符,则被排除。这就消除了code diff中对二进制文件的更改等不必要的东西。 通过参考Jiang和McMillan(2017)和Conventio nal Commits规则,以动词开头的提交信息将被收集。我们使用spaCy4进行词性标注。我们用13种最常见的动词类型来过滤提交消息。图2显示了收集到的动词类型及其在整个数据集上的比例。
图2:
因此,我们从52K Github仓库收集了345K代 码修改和提交消息对数据集,并将提交数据拆分 为80-10-10个训练/验证/测试集。这一结果如表1 所示。
表1:

2.5 CommitBERT
我们提出了通过CodeBERT模型与我们的数据集生成提交消息的想法。为此,本节描述了如何提供输入代码修改(X = ((add1, del1),…), (addn, deln))) 和提交消息(Y = (msg1,…(msgn))到CodeBERT,以及如何更有效地使用预训练的权重来减少编程语言(PL) 和自然语言(NL)之间的上下文表示差距。
(1)提交消息生成的CodeBERT
我们通过遵循NMT模型将代码修改提供给编码器,并将提交消息提供给解码器输入。特别是对于编码器中的代码修改,相似的输入被 联起来,不同类型的输入被句子分隔符(sep)分隔。以同样的方式将其应用于我们的CommitBERT,添加到kens (Add = (add1,…), addn)) 和删除令牌(Del = (del1,…, deln))的相似类型的token相互连接,并在它们之间插入句子分隔符。因此,条件似然如下所示:
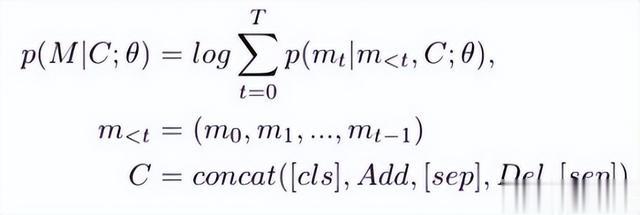
其中M是提交消息令牌,C是代码修改令牌,concat是列表连接函数。[cls]和[sep]是特 殊标记,分别是开始标记和句子分隔符标记。 与之前的工作不同,git diff中的所有代码修改都不用作输入,只使用代码修改中更改的行。由于这消除了不必要的输入,因此在以自然语言汇总代码修改时表现出了显著的性能提升。图3显示了代码修改实际上是如何被作为模型输入的。

图3:
(2)初始化预训练权重
为了减少两个主要(PL, NL)之间的差距,我们使用预训练的codeberas作为初始权值。此外,我们确定从我们的 数据集中删除已删除的令牌类似于 CodeSearchNet中的代码到nl任务。使用该特征,我们使用CodeBERT作为初始权重 的代码到nl任务训练后的初始权重。在提交消息生成中,这种训练方法比仅使用Code-BERT 权重表现出更好的效果。
3 实验评估
为了在提交消息生成任务中验证第5节中的提案,我们做了两个实验:
(1)比较使用所有代码修改作为输入和仅使用添加或删除的行作为输入的提交消息生成结果。
(2)消融研究多个初始模型权值,寻找PL和NL在语境表征上差距最小的权值。
3.1 实验设置
我们的实现使用CodeXGLUE的代码-文本管道库。对于下面的两个实验,我们使用相同的模型架构和实验参数。作为模型架构,编码器和解码器使用12层和3层Transformer层。我们使用5e-5作为学习率,并在一个具有32 batch size 的V100 GPU上进行训练。我们还使用256作为 最大源输入长度,128作为目标输入长度,10 个训练epoch, 10作为波束大小k。
RQ1 比较模型输入类型
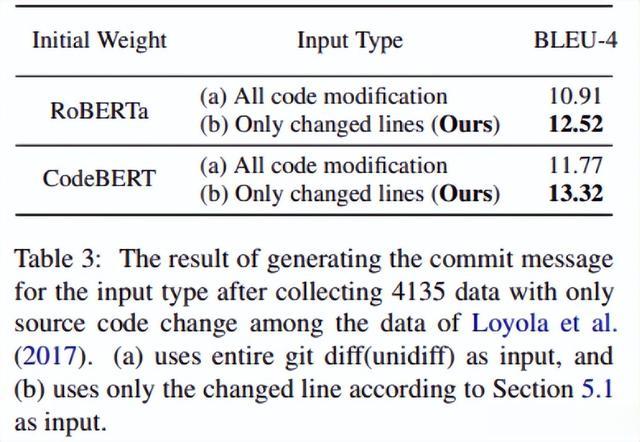
为了实验根据输入类型生成提交消息,在Loyola等人的26K训练数据中,从“。 java”文件中经过代码修改的数据中只收集了 4135个数据。然后我们将这4135个数据分别转 换为两种类型,并使用RoBERTa和CodeBERT 权重的训练数据进行实验:(a)在git diff中修改整 个代码,(b)在代码修改中只更改行。
图3详细展示了这两种差异。表3给出了这两种类型训练后用测试集进行推理时的BLEU-4值。两个初始权重都显示出比(b)更差的结果,即使类型(a)对模型采取了更广泛的输入。这表明,在生成提交消息时,除了作为输入数据更改的行外,其他行都会干扰训练。
RQ2 初始重量消融研究
我们在对收集的6种编程语言的345K 数据集进行消融研究的同时改变了模型的初始 权重。当使用代码域理解度较高的模型权重作为初始权重时,假设PL和NL 之间在上下文表示方面的巨大差距将大大减小。
为了证明这一点,我们训练了4个权重的提交消息生成任务作为初始模型权重:Random, RoBERTa6, CodeBERT7,以及训练的权重使用Code-BERT完成Code-to-NL任务。除了这个初始权重,所有的训练参数都是一样的。

表2显示了训练后四个权重的测试集的 BLEU-4和开发集的PPL。因此,使用CodeBERT作为初始权重在Code-to-NL任务上训练的 权重显示测试BLEU-4和开发PPL的最佳结果。 无论使用哪种编程语言,都显示出良好的性能。
转述:韩廷旭
