Generating Bug-Fixes Using Pretrained Transformers
Dawn Drain1, Chen Wu1, Alexey Svyatkovskiy1, Neel Sundaresan1
1Microsoft
引用
Drain D, Wu C, Svyatkovskiy A, et al. Generating bug-fixes using pretrained transformers[C]//Proceedings of the 5th ACM SIGPLAN International Symposium on Machine Programming. 2021: 1-8.
论文:https://dl.acm.org/doi/abs/10.1145/3460945.3464951
摘要
检测和修复bug是软件开发周期中最重要的两个部分。现有的bug检测工具主要基于静态分析器,它依赖于程序执行的数学逻辑和符号推理来检测常见的bug类型。修复bug通常不由开发人员负责。在这项工作中,我们介绍了DeepDebug:一种数据驱动的程序修复方法,它学习检测和修复从真实世界的GitHub存储库中挖掘的Java方法中的bug。我们将bug补丁架构为一个序列到序列的学习任务,包括两个步骤: (i)去噪预训练和(ii)对目标翻译任务的监督微调。我们发现,与从头开始的监督训练相比,源代码程序的预训练提高了33%的补丁数量,而从自然语言到代码的领域自适应预训练进一步提高了32%的准确性。我们将标准的准确性评估度量细化为非删除修复和仅删除修复,并表明我们的最佳模型比以前的技术状态多生成了75%的非删除修复。与之前的工作相比,我们在生成原始代码时获得了最好的结果,而不是使用抽象代码,后者往往只有利于更小容量的模型。最后,我们观察到一个微妙的改进,即通过添加语法嵌入和标准的位置嵌入,以及添加一个辅助任务来预测每个token的语法类。
1 引言
自动bug-补丁的早期结果假设了一组测试功能,并采用了生成补丁的方法,直到其中一个补丁通过了测试套件。编辑被操作化为抽象语法树(AST)操作,如删除、插入或交换节点。GenProg将这些操作与遗传算法结合起来,声称在8个超过10k测试用例的项目中,在510万个LOC中修复了105个bug中的55个。然而,一篇后续论文发现,55个声称的修复中有53个仅仅是足够的测试套件,而且大多数都是简单地使用删除操作符生成的。
最近的工作探索了使用更严格的标准来生成补丁:生成与最初修复错误的开发人员完全相同的修复。我们使用来自Patches in the Wild的Java数据集,它由从提交中提取的短方法组成,这些提交的消息表明它们正在修复错误。SequenceR通过只关注一行更改,缩小和扩展了Patches in the Wild数据集中的补丁,同时也通过包含其他方法的签名,提供了除了buggy方法之外的额外上下文。这种扩展的上下文提供了15%的相对提升。这三种方法都可以从复制中获得很大的收益,这是合理的,因为修复的方法与有错误的方法有很大的重叠。ENCORE也研究了单线变化,在更多的语言中,尽管它们只给出了有错误的行作为输入,并且没有提供任何进一步的上下文。
对于某些类型的错误,有可能产生数百万个合成错误来进行训练。Devlin等人在Python上训练一个RNN,以修复不正确的比较操作符,如错误使用“is”和“is not”、变量误用和被遗忘的“self”访问者。总的来说,它们对合成漏洞的准确率为86%,对现实生活中的准确率为41%。Kanade等人在一个更大的Python数据集上预训练一个BERT风格的模型“CuBERT”,然后对一套相关的合成bug进行微调,达到超过90%的准确率。
在更广泛的NLP领域中,我们的任务在精神上最接近语法纠错(GEC)。从CoNLL GEC排行榜中可以看出,我们看到了使用transformer的几种不同方法。除了更多的标准技术,如注入拼写错误,应用从左到右的重新排序,以及使用句子级错误检测任务,Kiyano等人通过嘈杂的反向翻译进行数据增强获得了巨大的收益。Kaneko等人使用seq2seq模型,其中输入嵌入与BERT通过语法错误检测(检测给定token是否错误)而产生的嵌入连接。Zhao等人除了注入人工噪声和使用辅助token标记任务外,还应用了一种复制机制。Awasthi等人采用了一种仅限编码器的方法,该方法将令牌zi映射到在第i个位置执行的编辑操作。他们看到了很大的速度增益,并研究了迭代应用他们的模型。
我们保留了试图修复通用错误的工作范围,同时利用技术对强大的序列到序列转换器进行预训练。我们首先将原始代码视为文本,并使用一个搜索目标在从GitHub挖掘的67k Java存储库上预训练一个4亿参数的编码-解码transformer,然后对Patches in the Wild基准测试中的补丁进行微调。更具体地说,我们考虑了三个预训练实验:仅对Java进行预训练;直接从英语预训练的强基线BART中进行微调;并通过BART的暖启动对Java进行预训练。仅在Java上进行预训练就提高了三分之一的补丁数量,从1049/12380提高到1392/12380,而使用暖启动程序的预训练则进一步提高了三分之一,到1839/12380。我们将用于这个基准的标准的top-1精度度量细化为非删除和仅删除修复,并表明我们最好的DeepDebug模型比以前的先进技术状态多生成了75%的非删除修复。与之前的工作相比,我们在生成原始代码时获得了最好的结果,而不是使用往往有利于较小模型的抽象代码。最后,我们看到了使用编程语言特有的形式语法的一个微妙改进。具体来说,我们尝试在标准位置嵌入中添加语法嵌入,以及添加一个辅助任务来预测每个token的语法类。
2 问题概述
生成补丁程序的任务如下:给定一个有错误的Java方法(通过挖掘提交消息找到),生成与提交修复程序的开发人员完全相同的token序列。
在微调过程中,我们训练序列到序列的transformer,以最小化生成修复的预期对数概率。形式上,让B = {b1,…,bn}和C = {c1,…,cn}分别是错误和正确的函数集,我们可以标记ci=ci,1, . . . , ci,ki 。设θ表示模型参数。其目标是:

更简单地说,我们寻求

3 实验评估
3.1 实验设置
我们首先从头开始研究了具体代码与抽象代码(433个最常见的token)的训练,使用6000万个参数转换器和OpenNMT框架中实现的复制机制。
然后,我们实验了在Fairseq框架中实施的几种预训练策略。具体来说,我们考虑了以下三个实验: i)只对Java进行预训练,ii)直接从对英语进行预训练的强基线BART中进行微调;以及iii)在Java上进行领域自适应预训练,使用 BART 的 warmstart。我们假设从英语开始warmstart会有帮助,因为如果一个人已经懂英语,并且对字典、图表或列表等概念有直观的理解,并且可以从自记录方法和变量名读出这些角色,那么学习如何编程要容易得多。
接下来,我们将研究在标准的下一个token预测损失之上添加一个辅助token类型标记损失的影响。我们使用在抽象过程中使用的相同的token类型,即METHOD, VARIABLE、STRING_LIT和NUM_LIT。语法突出显示是一种无处不在的开发人员工具,尤其在开发人员内化其正式语法之前学习语言的早期阶段非常有用。
我们最后的实验更仔细地研究了语法突出显示。在编码过程中,我们在标准的位置嵌入和词汇表嵌入中添加了一个token类型的嵌入,如图1所示。对于这两个token类型的实验,我们发现从头开始训练时有一点改进,但仅在微调期间添加它们时没有改进。我们还部分地复制和扩展了来自Copy That!的工作,通过对没有习惯用法的具体的和完全抽象的代码上的小方法进行评估。

图1:在编码过程中添加语法嵌入以及标准的位置和词汇嵌入
评估数据集。我们对来自Patches in the Wild的Java数据集进行了评估。Tufano等人挖掘了截至2016年Github上所有公开的非分叉存储库,用于提交Java代码,其中包括提交消息,其至少包含以下单词中的一个:bug, error, issue 或者 fix, patch, correct,它约占所有提交的5%。从这些提交中,他们提取了最多包含100个token的所有修改方法,并将它们分成两个数据集:包含小于50个token的小方法的数据集和包含多达100个token的中等方法的互补数据集。为了便于学习和加速收敛,Tufano等人抽象化了代码片段,同时保留了必要的语法信息。为了抽象代码片段,他们用METHODi、VARIABLEi、STRING_LITi、NUM_LITi和TYPEi形式的抽象替换了大约500个常见token的白名单之外的所有token。最后,它们引入了习语——经常出现的编程语言标识符和文字,不应用抽象。图2说明了这些代码表示形式之间的差异。
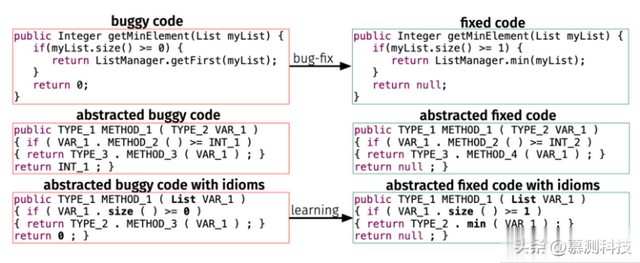
图2:原始代码、完全抽象的代码和用成语抽象的代码
作为规范化的一部分,数据集的作者还剥离了注释和不相关的空白和缩进。在本文中,我们给出了具体代码和带有习语的抽象代码的结果。我们在具体代码上获得了优越的结果,特别是在预训练后。
对比方法。抽象代码删除了变量和函数名的有价值的语义,并且坚持逐字修复是非常严格的,但在这些条件下仍然有可能获得非常高的准确性。使用一个1000万参数的双向LSTM与复制机制和谷歌的Seq2Seq Tufano等人的默认超参数,在小于50个token的小方法上能够获得9.2%的精确精度,在50到100个token之间的中基方法中,准确率为3.2%。更令人印象深刻的是,Copy That!使用带有新颖的跨度复制机制的bi-GRU实现分别获得了17.7%和8.0%的准确率。
我们推测 17.7% 和 8.0% 距离这项任务的最佳实际 top-1 准确率不远。基于提交消息挖掘的“错误修复提交”往往非常多样化和嘈杂,这与真正已知包含错误的方法形成鲜明对比,尤其是来自少量合成错误的方法。
模型。我们的DeepDebug模型使用了标准transformer架构。复制机制已被证明可以显著促进小型LSTM模型,并为transformer提供小幅提升,以完成特别相关的任务,如摘要和语法纠正。当从头开始训练我们的6000万参数模型和复制最新技术时,我们使用复制注意力。我们没有在全面的预训练实验中使用复制注意力,主要是由于技术限制。
对于具体代码,我们使用大约50k个token的字节对编码(BPE)词汇表,对于抽象代码使用所有433个唯一标记的词汇表。为了形成BPE词汇表,我们使用每个GPT-2、BART和RoBERTa使用的现有字节级BPE标记器,并按照从头开始训练的标记器学习的顺序附加空白token。在预训练期间,添加空格标记可以有效地将上下文窗口长度和处理速度提高约 40%,尽管在微调期间改进幅度较小,因为我们将重点限制在向左调整的方法上。通过扩展预先存在的分词器,我们可以重用经过英语训练的公共检查点,同时有效地使它们适应源代码。
我们尝试在标准词汇和位置嵌入的同时添加句法嵌入,如图 1 所示。通过这种方式,我们就可以立即区分是否存在像“return”或“static”这样的BPE token是关键词。总的来说,我们减轻了模型解析语言形式语法的一些困难,这对于transformer来说是不成比例的困难。我们也可以将这种策略视为包含使用原始代码的方法和使用抽象代码的方法
3.2 实验结果
我们发现,许多修复都落入了一些平淡无奇的模式,特别是考虑到方法的有限上下文:简单的删除,就像GenProg等经典模型一样;交换“protected”、“private”和“public”;和插入“native”。
事实上,我们在第一次尝试中发现的所有修复程序中,大约有三分之二只是删除。对于我们最强的模型,7%的非删除修复是某种受保护的/私有的/公共的交换或插入的“native”一词,而对于我们考虑的最弱的模型,这一比例高达50%。因此,在展示我们的结果时,我们还给出了简单的删除修复的数量和非删除修复的补充数量。
当考虑我们的模型没有找到的修复程序时,最重要的主题是,如果没有更多的上下文,该任务是不可能完成的。理论上,错误修复应该是近乎确定性的;在实现或优化附加功能时,可以以几乎任意的方式编辑代码,但是bug是一个需要解决的明显错误。
在实践中,正确的行为往往被低估,特别是因为我们的方法排除了有用的信息,如测试用例、示例用法和类构造函数。例如,考虑图3中的函数pop(),我们的模型在第一次尝试时没有修复它。一个接一个的错误是常见的。然而,仅考虑错误方法,头部指数应该低于零还是-1是不明确的。

图3:如果没有看到存储或i_head的定义,则此 off-by-one 错误是否是 bug 是模棱两可的
3.3 结果分析
首先,为中型规模方法生成修复比为短方法生成修复更难,因为较长的方法更复杂,并且可以以更多的方式进行编辑。
预训练是有帮助的,特别是对于中等方法。事实上,预训练时中等修复的数量增加了三倍。
较小的GRU模型和在带有习语的抽象代码上训练的transformers具有特别的破坏性,产生的删除数量是建设性修复的7倍。较小的GRU模型受益于抽象代码,而较大的transformers则不然。
英语预训练可以提高程序修复的性能,这可能是由于变量和函数名中固有的语义。即使对于非程序员来说,像getMinElement这样的函数名也很直观。事实上,仅使用英语预训练的公共BART检查点优于仅在Java上预训练的模型,尽管我们的纯java模型的训练时间仅为纯英语检查点的4%。我们采用强大的英语模型,并在Java上进一步预训练,得到了最佳结果。
我们观察到,在从头开始训练时,添加辅助语法标记任务在一定程度上有所帮助,但在微调预训练模型时没有区别。我们假设这是因为预训练模型已经对语言的语法有很强的理解,并且标准的下一个token预测任务已经提供了充足的语法反馈。
从头开始训练时,从6000万个参数扩展到4亿个参数的回报并不令人满意,特别是考虑到扩大T5或GPT等transformers带来的巨大和可预测的收益。我们假设这是因为训练数据的规模较小。我们的每个训练集只包含大约50k的例子,其中只有几十兆字节,而BART-large有4亿个参数,在FP16中加载时几乎是一个完整的GB。
最后,与添加语法标记任务类似,我们看到在编码过程中以向词汇表嵌入添加token类型嵌入的形式添加语法高亮显示了一个小好处,但在微调期间添加这些嵌入没有任何好处。我们假设,在微调过程中添加高亮显示缺乏好处是由于预训练模型已经开发了一种表示不同token类型的方法,这与添加的嵌入发生冲突。
转述:张雅欣
