全文约2488 字;
阅读时间:约6分钟;
听完时间:约12分钟;

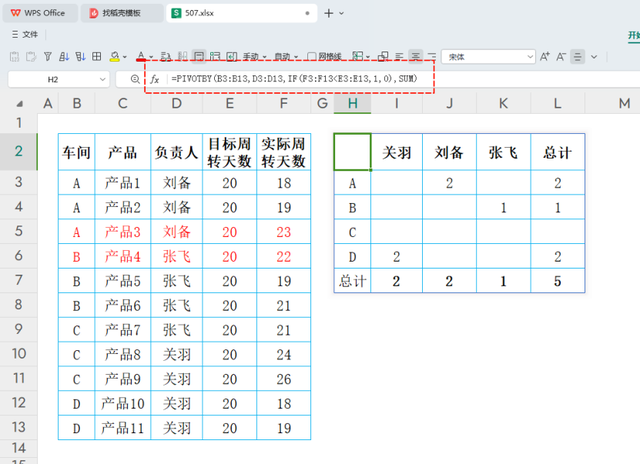
昨天通过一个实际的工作场景进一步探讨了PBY函数的应用。在工厂环境中,分析库存周转天数有助于提升资金效率和运营效率。我们展示了如何使用PBY函数轻松地汇总每个车间不同负责人名下产品的库存周转天数达标情况,与传统的使用多个函数(如UNIQUE、TOROW、SUMIFS等)和辅助列相比,PBY函数的操作更为简便直观。
今天我们将继续分享一个数据统计分析的场景,针对工厂下达的订单进行数量统计、总金额统计及均价统计等指标的全面分析与展示。
 案例数据
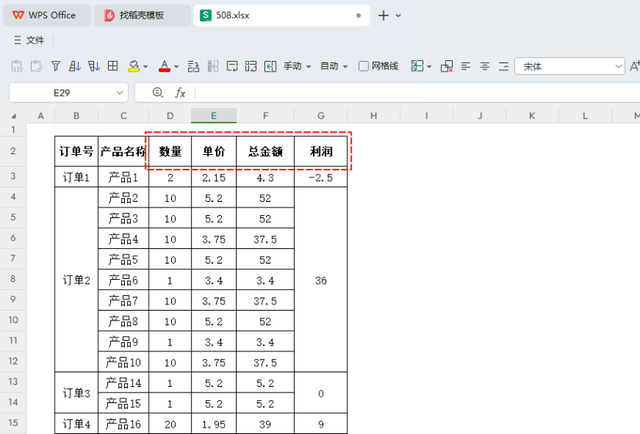
案例数据下图展示了一个由工厂统计员手工统计的《订单明细表》,其中B列到G列分别记录了“订单号”、“产品名称”、“数量”、“单价”、“总金额”和“利润”。数据记录大约有几千条(演示案例中仅截取了部分数据)。现在需要针对每个订单进行单独的数据分析:
每个订单中下达的产品数量是多少?不同产品的订单总量分别是多少?每个订单的总金额是多少?订单的平均价格是多少?每个订单的利润是多少?以上分析涉及求和、统计及计算平均值等方面。然而,由于数据结构中存在合并单元格的情况——即每张订单对应的产品数量进行了单元格合并,尽管这样做能使表格看起来更清晰,但也给数据分析带来了困难。
 传统函数
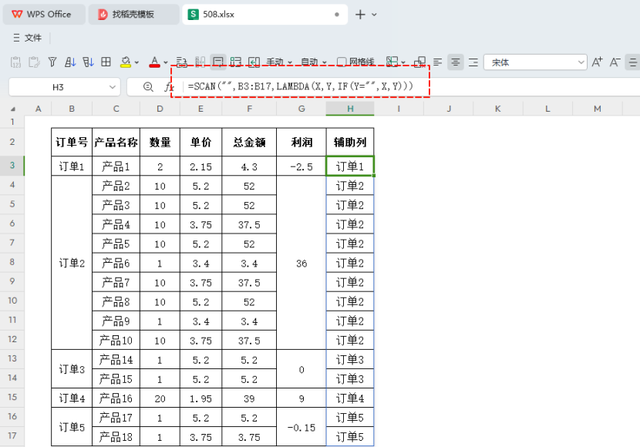
传统函数在进行PBY函数进行数据分析前,还是先用传统函数进行求解。对于有数据合并的单元格数据区域,首要解决的问题就是把合并单元格取消。在H列中插入一列辅助列,录入以下公式:
=SCAN("",B3:B17,LAMBDA(X,Y,IF(Y="",X,Y)))
公式解释:
SCAN(初始值, 数组, 函数):
参数1: 这是一个初始值,在本例中是 "",表示一个空字符串。SCAN 将从这个值开始累积。
参数2: 这是指定的数组范围 B3:B17,SCAN 将在这个范围内迭代每一个元素。
参数3: 这是一个用户定义的函数,用来指定如何处理数组中的每一个元素。在本例中,LAMBDA 定义了这个处理逻辑。
LAMBDA(X, Y, IF(Y="", X, Y)):
X: 表示累积器的当前值,在第一次迭代时等于初始值 ""。
Y: 表示当前正在处理的数组元素。
IF(Y="", X, Y): 这是一个条件语句,检查当前元素 Y 是否为空字符串。如果是空字符串,则返回累积器的当前值 X;否则,返回当前元素 Y。
整体来说,这个SCAN 函数的作用是遍历 B3:B17 范围内的每个值,如果遇到空字符串则跳过,否则将其加入到结果数组中。最终的结果将是一个不含空字符串的新数组。
通过这个函数是用来移除B3:B17 范围内的任何空字符串,并返回一个只包含非空字符串的数组。如果 B3:B17 中没有空字符串,则该函数返回的数组与原始数组相同。如果有空字符串,则会被忽略。
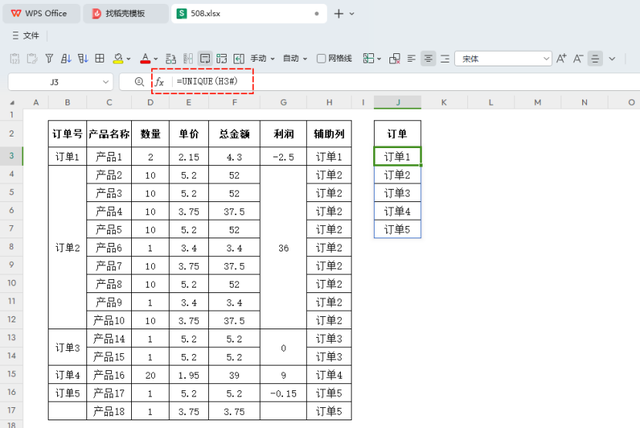
有了这个辅助列之后,我们再使用UNIQUE 函数进行去重,从而得到《订单明细表》中的统计基准数据。录入函数如下:
=UNIQUE(H3#)
公式解释:
H3# 为上方辅助列返回的结果,该公式将对此结果进行去重处理。
有了辅助列和订单统计基准后,针对五个问题分别录入以下公式:
产品数量: K3=COUNTIFS(H3#,J3#)
订单总数: L3=SUMIFS(D3:D17,H3#,J3#)
订单总额: M3=SUMIFS(F3:F17,H3#,J3#)
订单均价: N3=AVERAGEIFS(F3:F17,H3#,J3#)
订单利润: O3=SUMIFS(G3:G17,H3#,J3#)
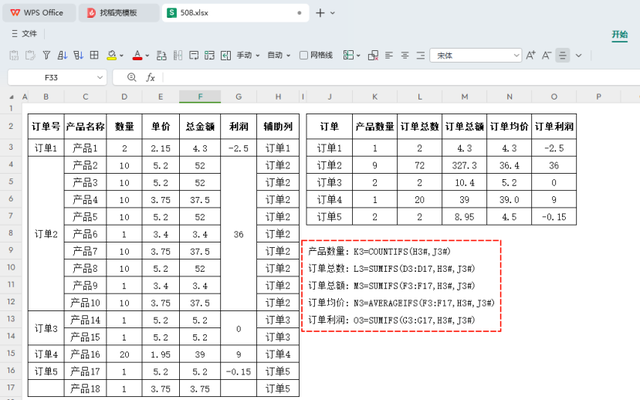
以上公式的解释:
这些公式分别运用了条件统计函数、条件求和函数以及条件平均值函数等多个方面的函数来分析数据。其基本原理是利用辅助列(H3#)作为参照区域,并以删除重复项后的订单号(J3#)作为条件来进行各项统计。
聚合函数接下来要介绍的就是本文的主角——PBY函数。使用聚合函数的解决方案相较于传统方法更为简洁高效。请在适当的位置插入以下公式:
=PIVOTBY(SCAN("",B3:B17,LAMBDA(X,Y,IF(Y="",X,Y))),,HSTACK(C3:C17,D3:D17,F3:F17,F3:F17,G3:G17),HSTACK(COUNTA,SUM,AVERAGE,SUM,SUM))
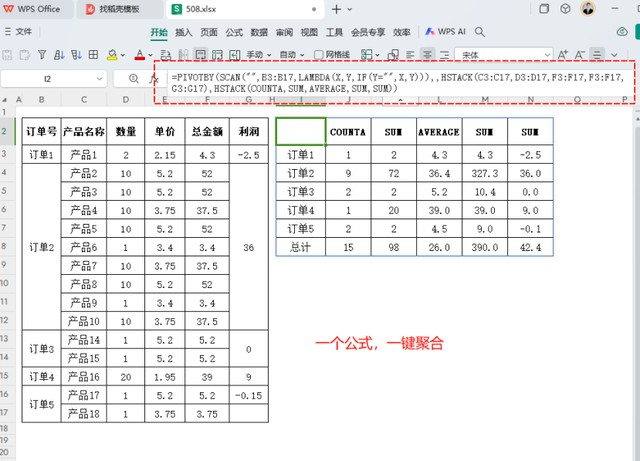
公式解释:
参数1:行字段 - SCAN("",B3:B17,LAMBDA(X,Y,IF(Y="",X,Y))),这指定了行标签,即要按照哪个列的值来分组。在这个例子中,代表着合并单元格取消后的订单明细
参数2:列字段 - 空,这指定了列标签,录入一个逗号占位,代表着不按列聚合。
参数3:值字段 - HSTACK(C3:C17,D3:D17,F3:F17,F3:F17,G3:G17),这部分定义了要聚合的数据。HSTACK 函数用于创建一个水平数组,将多个范围或值水平拼接在一起。
这里是将C3:C17, D3:D17, F3:F17(两次引用),G3:G17这五个范围水平拼接,作为数据透视表的数据源,分别代表“产品名称、数量、总金额、总金额、利润这几列数据。
参数4:汇总方式 - HSTACK(COUNTA,SUM,AVERAGE,SUM,SUM):同样使用 HSTACK 函数,这里创建了一个包含函数名称的数组:COUNTA, SUM, AVERAGE, SUM, SUM。这些函数将用于聚合函数的计算,分别代表统计产品数量、订单总数、订单均价、订单总额、订单利润;
参数选择上面的聚合函数PBY只需要基本的四个参数就能解决传统函数中需要借助辅助列并使用多个公式才能解决的订单需求统计问题,其优势显而易见。但对于新手来说,可能不太了解后面的一些参数,比如如何添加标题,如何去除总计等。下面将逐一分享这些问题的解决办法。
对于新手来说,如果不显示标题,手动输入是一个不错的选择。您可以将公式更改为:
=DROP(PIVOTBY(SCAN("",B3:B17,LAMBDA(X,Y,IF(Y="",X,Y))),,HSTACK(C3:C17,D3:D17,F3:F17,F3:F17,G3:G17),HSTACK(COUNTA,SUM,AVERAGE,SUM,SUM),,0),1)
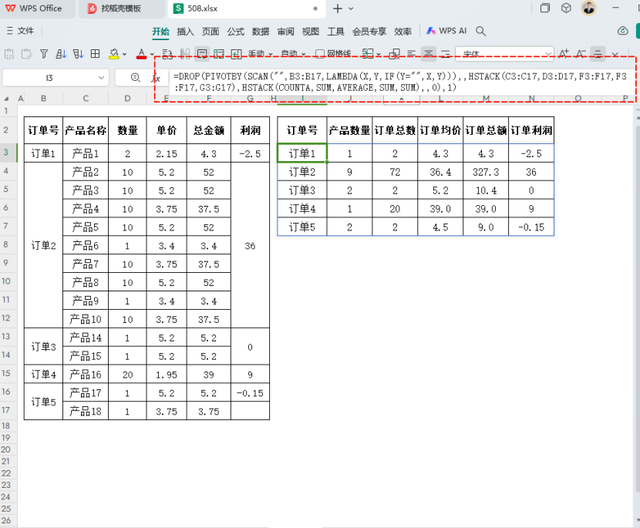
公式解释:
DROP 用于丢弃第一行,通过在 PIVOTBY 公式后加上 DROP(..., 1) 来实现。
参数0 在 PIVOTBY 的最后用来屏蔽总计行。
如果需要标题也能自动生成,可以更改为以下公式:
=DROP(PIVOTBY(VSTACK(B2,SCAN("",B3:B17,LAMBDA(X,Y,IF(Y="",X,Y)))),,HSTACK(C2:C17,D2:D17,F2:F17,F2:F17,G2:G17),HSTACK(COUNTA,SUM,AVERAGE,SUM,SUM),,0),1)
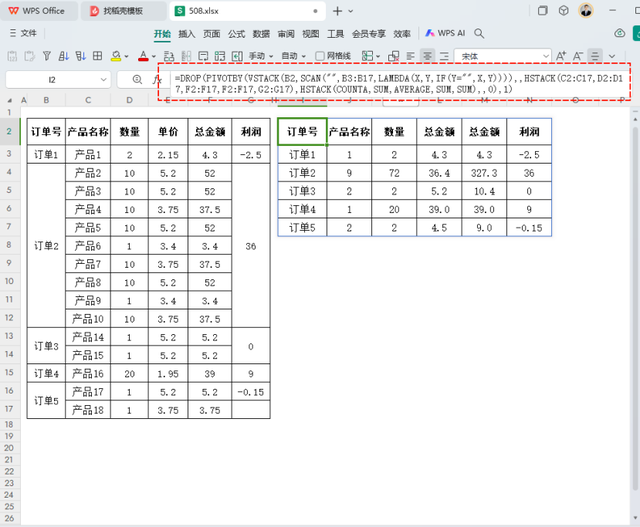
公式解释:
VSTACK 用于拼接 B2 单元格(“订单号”)和辅助列,从而形成带有标题的数据行作为聚合的源数据。
聚合值的数据范围全部调整为包含标题行。
配合DROP(..., 1) 丢弃第一行,即公式标题行COUNTA, SUM, AVERAGE, SUM, SUM。
今日总结今天,我们探讨了如何使用Excel中的聚合函数来简化工厂订单数据的统计分析工作。通过对比传统方法与使用PBY函数的方法,我们发现后者不仅能够提高工作效率,还能简化数据处理流程,尤其是在面对大量合并单元格的情况下。
在案例数据中,我们首先面临的是合并单元格带来的挑战,这使得传统的数据分析变得复杂。为了解决这个问题,我们引入了SCAN函数来处理合并单元格,并使用UNIQUE函数去除重复项,从而获得了一个干净的数据集作为统计的基础。
接着,我们展示了如何使用传统的条件统计函数(如COUNTIFS、SUMIFS、AVERAGEIFS等)来解答具体的业务问题,例如统计每个订单的产品数量、订单总额及订单利润等。这些函数虽然功能强大,但在处理大量数据时显得有些繁琐。
最后,我们介绍了PBY函数的强大之处。它通过简单的四个参数设置就能完成复杂的统计任务,无需额外的辅助列和多个公式。我们还分享了如何通过调整参数来实现添加标题行以及去除总计行等功能,使得数据分析更加直观和易于理解。
总之,通过今天的分享,我们看到了聚合函数在处理复杂数据时的优势,同时也提供了实用的技巧帮助新手更好地理解和应用这些先进的Excel功能。希望这些知识能帮助大家在日常工作中更加高效地完成数据分析任务。
如果你的WPS版本没有这两个函数,请点下方链接下载:
WPS 18166
https://kdocs.cn/l/cue3qXvWLB6W
