趣谈前端专注于前端+AI前沿技术和场景应用落地。关注可视化,零代码,AI技术融合,职业发展研究和软件工程化实践。致力于打造一个开放自由的技术交流平台。
大家好啊,我是徐小夕。之前和大家分享了很多前端工程化,可视化,职业发展相关的干货,虽然这两年大环境不太好,但是我们还是要定期学习成长,才能让自己的未来把握职场主动权。
最近由于AI应用的高速发展,使得文档/知识库成为了AI的首选试炼场。比如用AI提取PDF的大纲和关键内容,用AI总结电子书的内容,AI对DOC文档进行润色,优化等,这些都离不开对文档的解析和处理。
那么前端能不能实现对文档的解析和处理呢?答案是肯定的,接下来我就和大家分享一下:
前端如何解析Word文件基于HTML,一键导出为Word文档当然口说无凭,我已经在Nocode/WEP文档知识引擎中把Doc文档功能实现了,大家感兴趣的可以亲自体验一下。
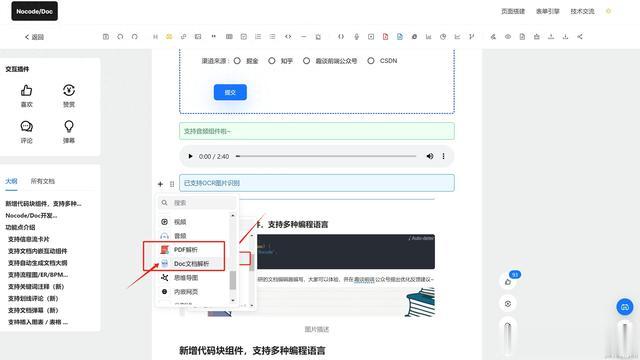
image.png
好啦,接下来开始我们的技术分享。
往期精彩Word文档的本质
image.png
Word 文档的本质是一种电子文档格式,它主要用于创建、编辑和保存文本内容,同时还可以包含图片、表格、图表等多种元素。它是一种方便的工具,用于记录、整理和交流信息。
doc 和 docx 是两种常见的 Word 文档格式,它们主要有以下区别:
版本:doc 是 Word 2003 及之前版本的默认文件格式,而 docx 是 Word 2007 及之后版本的默认文件格式。兼容性:doc 格式的兼容性较好,可以被大多数旧版本的 Word 软件打开。而 docx 格式在较新版本的 Word 中得到完全支持,但在一些旧版本的 Word 中可能需要安装兼容性插件才能正常打开。文件体积:由于 docx 格式采用了更高效的压缩技术,所以它的文件体积通常比 doc 格式小。安全性:docx 格式采用基于 XML 的格式,相对更安全一些,不容易受到宏病毒的攻击。功能支持:docx 格式支持更多的新特性和功能,如高级的图表和图形处理、更丰富的格式选项、多媒体嵌入等。而 doc 格式则不支持这些新功能。为了与时俱进,我们优先考虑最新标准格式 docx, 那么如何解析 docx 呢,这就要进一步分析一下 docx文件的本质了。
docx 的本质是什么docx 我们第一感觉是一个文件,其实确实是一个文件(压缩文件),我用解压工具提取文件之后,它的文件结构是这样的:

image.png
进入 word 文件夹,可以看到如下目录结构:
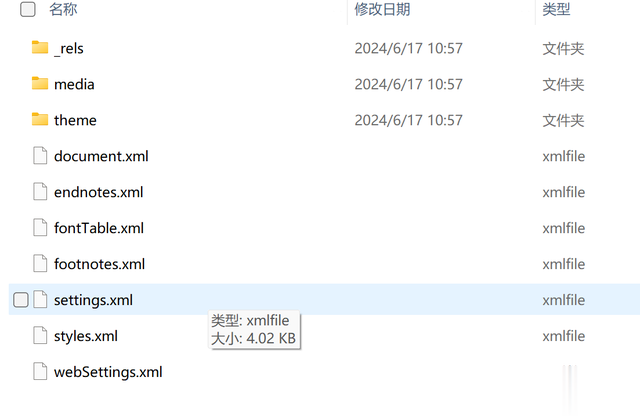
image.png
打开一个 xml 文件可以看到类似如下的内容:
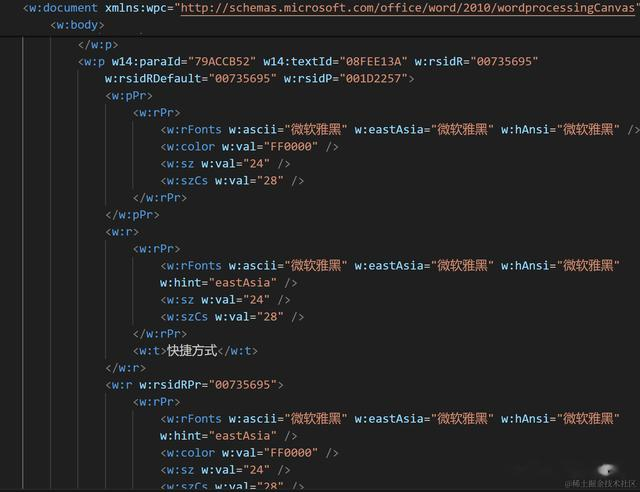
image.png
看到这熟悉前端的小伙伴应该就比较熟悉了,我们可以使用类似于 document 的方法解析处理不同的XML标签,从而实现对 docx 文件的解析。
如何实现Word文档的解析有了以上的分析结果,我们自己实现一个word文档解析器就非常容易了,但是考虑到docx的xml 文件的复杂性,我们自己实现需要考虑很多种情况,比如:
标题列表标题列表可定制的 docx 样式到 HTML 的映射表格:表格格式(如边框)脚注和尾注图片粗体、斜体、下划线、删除线、上标和下标。链接换行文本框:文本框的内容被视为一个单独的段落,出现在包含文本框的段落之后。注释如果是项目进度比较紧张的情况下,我们自己实现肯定是要被“批斗”的,所以我们可以考虑第三方成熟的解决方案。
第三方开源方案这里直接上我总结的几个开源方案:
Python 中的 python-docxDocX:一个基于.NET框架的库,用于操作Word 2007/2010/2013文件,具有简单易用的API,无需安装额外软件,支持非商业用途。OpenXml-PowerTools:一个基于Open XML文档编程接口开发的开源工具,扩展了Open XML SDK的功能,支持将docx、pptx文件拆分为多个文件、将多个docx、pptx文件合并为一个文件、使用XML数据模板生成docx文件、docx文档高保值转换为Html页面等功能Mammoth 一个专注于转换 .docx 文档的工具库,支持浏览器和服务器使用那作为前端的小伙伴,我们首选 Mammoth。
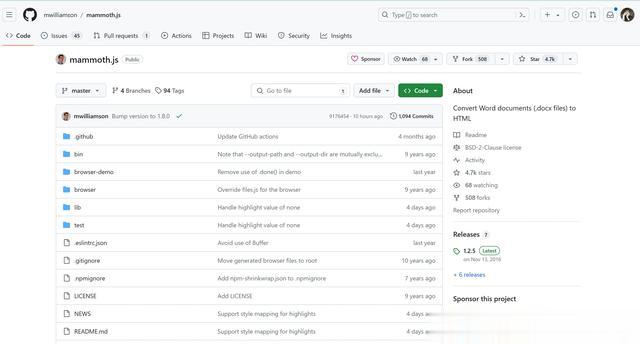
image.png
github地址:https://github.com/mwilliamson/mammoth.js
实战Word文档解析接下来和大家分享一下使用 Mammoth 来实现 docx 文档解析。
先来看一个简单的例子:
import mammoth from 'mammoth';mammoth.convertToHtml({path: "你的doc文件的路径/document.docx"}) .then(function(result){ var html = result.value; // 解析出的html结果 var messages = result.messages; // 错误或者额外的提示信息 }) .catch(function(error) { console.error(error); });以上代码是在node.js 环境下实现的简单例子,当然我们也可以在浏览器中直接使用,我在看完了它的文档之后,加上自己的研究,写了一个能自定义图片上传路径,并支持修改文档样式的demo,这里分享一下:
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title></head><body> <input type="file" onchange="handleFile(this.files[0])" /> <script src="https://unpkg.com/mammoth@latest/dist/mammoth.min.js"></script> <script> function handleFile(file) { const reader = new FileReader(); reader.onload = function (loadEvent) { const arrayBuffer = loadEvent.target.result; mammoth.convertToHtml({ arrayBuffer: arrayBuffer }, { // 设置自定义图片上传路径 imageReader: (image) => { return new Promise((resolve, reject) => { // 在这里实现图片上传逻辑,并将上传后的图片路径作为结果返回 resolve('your_uploaded_image_path'); }); }, // 设置文本样式 styleMap: [ // 标题样式 { name: 'Heading 1', element: 'h1', attributes: { 'tyle': 'font-size: 24px; color: #333;', }, }, // 正文样式 { name: 'Normal', element: 'p', attributes: { 'tyle': 'font-size: 16px; color: #666;', }, }, ], }) .then(result => { console.log(result.value); }) .catch(error => { console.error(error); }); }; reader.readAsArrayBuffer(file); } </script></body></html>Word文档导出实现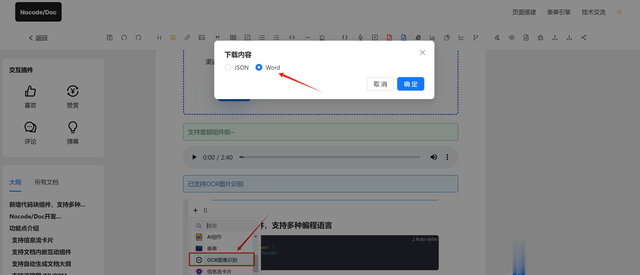
image.png
实现将html导出为word文档,方法其实也很简单,这里直接分享一下我的方案:
const html = docRef.current;const blob = new Blob([html.innerHTML], { type: 'application/msword' });// 创建一个下载链接const link = document.createElement('a');link.href = URL.createObjectURL(blob);link.download = 'wep.doc';// 模拟点击下载链接link.click();// 释放资源URL.revokeObjectURL(link.href);本质上就是我们将 html内容转化为blob,并设置类型为application/msword, 最后通过revokeObjectURL api来实现docx文档下载。
当然还有其他方案,这里也和大家分享一下:
import htmlDocx from 'html-docx-js/dist/html-docx';import FileSaver from 'file-saver';// 定义要导出的 HTML 内容const htmlContent = ` <h1>标题</h1> <p>这是一段文本。</p> <table border="1"> <tr> <th>姓名</th> <th>年龄</th> </tr> <tr> <td>张三</td> <td>25</td> </tr> </table>`;// 将 HTML 转换为 Word 文档const docx = htmlDocx.asBlob(htmlContent);// 保存 Word 文档FileSaver.saveAs(docx, 'example.docx');所有案例都在Nocode/WEP中实现,大家感兴趣可以参考一下.
