An Analysis of the Automatic Bug Fixing Performance of ChatGPT
Dominik Sobania, Martin Briesch, Carol Hanna, Justyna Petke
引用
D. Sobania, M. Briesch, C. Hanna and J. Petke, "An Analysis of the Automatic Bug Fixing Performance of ChatGPT," 2023 IEEE/ACM International Workshop on Automated Program Repair (APR), Melbourne, Australia, 2023, pp. 23-30, doi: 10.1109/APR59189.2023.00012.
论文:https://ieeexplore.ieee.org/abstract/document/10189263/authors#authors
摘要
在本文中,我们在标准错误修复基准集 QuixBugs 上评估 ChatGPT,并将其性能与文献中报告的其他几种方法的结果进行比较。我们发现 ChatGPT 的错误修复性能与常见的深度学习方法 CoCoNut 和 Codex 相比具有竞争力,并且明显优于标准程序修复方法报告的结果。与以前的方法相比,ChatGPT 提供了一个对话系统,通过该系统可以输入更多信息,例如特定输入的预期输出或观察到的错误消息。通过向 ChatGPT 提供此类提示,可以进一步提高其成功率,修复了40个错误中的31个,超越了最先进的技术。
1 引言
复杂的软件通常在其源代码中包含未被发现的错误。这些发现越晚,产生的影响就越深远。软件中未经纠正的错误可能会导致重要系统故障,从而导致高昂的经济成本。
为了支持程序员查找和修复软件错误,引入了自动程序修复 (APR) 系统,该系统会自动建议软件补丁来纠正检测到的错误。例如,Haraldsson 等人。提出了一种基于遗传改良(GI)的方法,该方法在工作日跟踪新出现的错误,并在夜间寻找潜在的修复方法。第二天早上,程序员会收到一份建议列表,这些建议应该有助于修复检测到的错误。
自动化程序修复的标准方法可以分为两类:生成和验证方法通过搜索策略引导软件变异,而语义驱动(或基于综合)的方法使用约束求解器来综合修复。生成和验证技术首先得到了工业应用。标准 APR 方法的主要缺点之一是其运行成本。生成和验证通常依赖测试套件来验证程序的正确性,而基于综合的则依赖于调用约束求解器。这两种验证策略的成本都很高,导致典型的 APR 工具需要运行数小时才能向开发人员提供可行的补丁。
最近,引入了基于深度学习(DL)方法的程序修复工具。它们从现有数据库中学习错误修复模式,并将自动程序修复问题视为神经机器翻译任务,产生有时数百个补丁的排名。与标准方法不同,此类生成的补丁通常不会根据测试套件或其他自动验证策略进行评估,因此甚至可能无法编译。尽管如此,基于深度学习的程序修复已显示出与标准方法相比具有竞争力的结果。
近年来,出现了几种基于Transformer架构的大规模语言模型,例如CodeBERT、PyMT5和Codex,它们也可以处理和扩展源代码并实现与各种编码任务的标准方法的结果相当。最近备受关注的基于Transformer 架构的大规模语言模型是ChatGPT。利用 ChatGPT 不仅可以扩展文本输入,甚至可以与语言模型进行对话,并考虑到之前的聊天记录用于生成答案。除了非常一般或特定主题的主题之外,ChatGPT 还可以用于讨论源代码,例如,寻求修复不正确代码的建议。然而,这些建议的质量仍不清楚。
因此,在这项工作中,我们评估和分析了 ChatGPT 的自动错误修复性能。此外,我们还与使用最先进APR方法和 Codex 获得的文献中报告的结果进行了比较。我们为我们的研究选择了 QuixBugs基准集,因为它包含针对当前 APR 方式的小型但具有挑战性的程序我们考虑 QuixBugs 中的所有 Python 问题,即总共40个。
我们首先要求 ChatGPT 修复所选基准的错误,并手动检查建议的解决方案是否正确。我们重复查询四次,以考虑 ChatGPT 的启发式本质。接下来,我们将其性能与 Codex 和专用APR方法进行比较。对于标准APR方法,我们采用最近一篇论文的结果,该论文检查了 QuixBugs 基准集上几种方法的性能。对于基于深度学习的专用 APR 方法,我们采用 CoCoNut的结果。对于大规模语言模型 Codex,我们采用中的结果。此外,我们对 ChatGPT 的答案进行研究和分类,以更深入地了解其行为。鉴于 ChatGPT 提供了与模型对话的独特机会,我们向模型提供了一个小提示(例如,失败的测试输入及其产生的错误),以查看它是否提高了 ChatGPT 的修复率。
我们发现 ChatGPT 的程序修复性能与 CoCoNut 和 Codex 所取得的结果具有竞争力(分别解决了 19 例、19 例和 21 例)。与标准程序修复方法相比,ChatGPT 取得了明显更好的结果。使用 ChatGPT,我们可以修复40个问题中的19个错误,而使用标准方法只能修复 7 个错误,即使我们只向 ChatGPT 提供不正确的代码片段,没有任何附加信息,也没有以对话方式使用聊天选项。如果聊天功能被积极使用,我们可以修复更多的实例。这显示了向程序修复系统提供手动提示的力量。我们所有的实验数据都可以在线获取。
2 技术介绍
2.1 BenchMark
为了评估 ChatGPT 的自动错误修复性能,我们使用 QuixBugs基准测试集。与许多其他用于自动程序修复的基准测试套件不同,QuixBugs 包含相对较小的问题(少量代码行)。因此,它们适合在对话系统中使用。对于QuixBugs中的40个基准问题中的每一个,我们都会获取错误的Python代码,删除所有包含的注释,并询问 ChatGPT 代码是否包含错误以及如何修复它。对于每个基准测试问题,我们向 ChatGPT 发出几个独立的请求,并手动检查给定的答案是否正确。我们通过对每个查询使用相同的格式来标准化我们的过程。我们问:“这个程序有错误吗?怎么解决呢?”接下来是一个空行和没有注释的有缺陷的代码。图 1 显示了针对该问题向 ChatGPT 发出的示例请求。第 1-2 行包含 ChatGPT 的问题,其中我们询问如何修复该错误,并从第 4 行开始提供错误的代码片段。对于此示例,我们期望从 ChatGPT 得到一个解决第 7 行中的错误的答案,其中 n ˆ= n - 1 应替换为 n &= n - 1,或者包含包含已修复错误的完整代码片段的响应(正确解决)或通过给出准确且正确的描述如何更改受影响的代码行。

图 1 向 ChatGPT 请求问题。
2.2 比较研究
我们针对 QuixBugs 数据集中的每个问题向 ChatGPT 运行了四个独立请求。为了将 ChatGPT 的结果与标准 APR 方法进行比较,我们从文献中获取了综合研究的结果,该研究报告了十种不同方法的性能(Arja、Cardumen、Dynamoth、JGenProg、JKali、JMutRepair、Nopol、NPEfix、RSRepair和 Tibra)关于 QuixBugs的问题。对于基于深度学习的专用 APR 方法,我们选择了 Lutellier 等人报告的最新结果。在表1中,仅当 Lutellier 等人提出的方法 CoCoNut 将正确的补丁排在第一位时,我们才会报告修复。对于大规模语言模型 Codex,我们采用了最近一篇论文的结果。我们在 2022年 12 月 15 日和 2023 年 1 月 9 日的 ChatGPT 版本上运行了此实验。
2.3 对话研究
鉴于 ChatGPT 提供了与模型对话的独特机会,我们还进行了一项研究,根据 ChatGPT 的响应向 ChatGPT 提供提示。如果 ChatGPT 没有为第一个请求提供正确的答案(如前一段所述),我们会以标准化的方式告诉 ChatGPT 该功能未正常工作,并另外提供一个输入示例,表明该功能未正常工作。如果 ChatGPT 错误地声称程序是正确的,我们会回复:“该功能不起作用。
例如,对于输入 <input> 它应该返回 <output>。”或“该功能不起作用。
例如。对于输入 <input>,我收到以下错误消息:<output>”,具体取决于 QuixBugs 数据集中失败的测试用例是否返回错误答案或引发错误。如果是对于更复杂的输入,我们做出以下响应:“该功能不起作用。例如,给出以下调用: <code snippet> 以下应该是输出: <output>。”我们只提供一个这样的提示并报告结果。
本实验在2023年1月9日起的ChatGPT版本上运行。
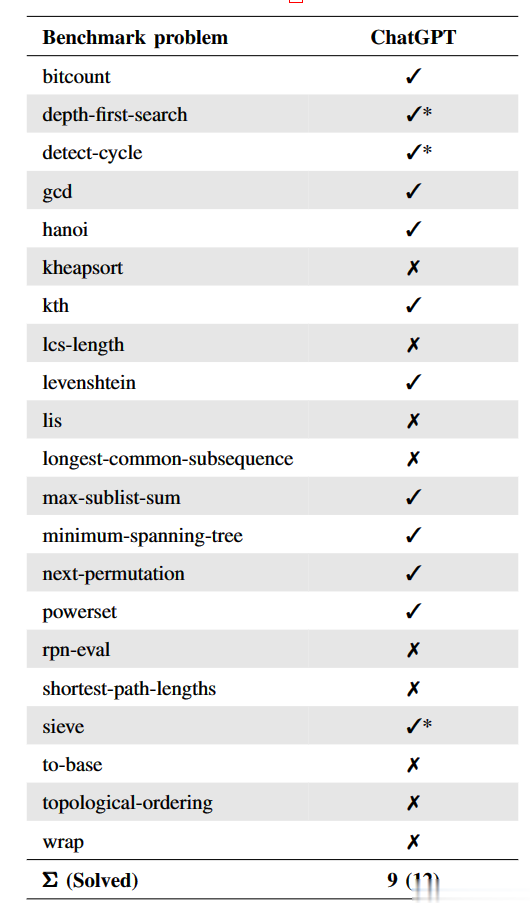
表 1 ChatGPT、Codex、CoCoNut 和标准 APR 方法针对 QuixBugs 基准集问题所取得的结果。对于 ChatGPT,我们还在括号中报告成功运行的次数。

3 实验评估
ChatGPT、Codex、CoCoNut 和标准 APR 方法的比较结果。我们对 ChatGPT 的答案进行分类,并报告与模型的简短讨论。此外,我们还描述了我们在使用 ChatGPT 时注意到的情况。
3.1 结果分析
A.自动错误修复性能
表 1 显示了 ChatGPT、Codex、CoCoNut 和专用 APR 方法在 QuixBugs 基准问题上所取得的结果。对于 ChatGPT 结果,复选标记 (3) 表示在基准问题的四次运行中至少有一次给出了正确答案。叉号 (7) 表示在任何一次运行中均未给出正确答案。在括号中,我们还报告了导致成功解决方案的运行次数。对于文献结果,复选标记表示报告了正确的错误修复。十字表示没有报告成功的错误修复。
我们看到 ChatGPT 取得的结果在性能上与 Codex 相似,并且优于标准 APR 方法。总体而言,我们发现 ChatGPT 的19个基准问题得到了修复,Codex 报告了21个,CoCoNut报告了19个,标准方法只有7个。
基于语言模型的方法和标准 APR 方法之间性能上的巨大差距可以解释为后者通常只使用一个小的测试套件来定义问题,很容易过度拟合。的作者也报告了这个问题。如果仅考虑测试套件进行评估,标准方法将总共解决16个基准问题。然而,由于在现实世界的应用中,只有能够处理看不见的输入的程序才可用,因此我们只采用了中的7个概括问题作为正确的问题。
如果我们仔细观察 ChatGPT 的结果,我们会发现基准测试问题通常只能在一两次运行中得到解决。仅针对问题,ChatGPT 在所有四次运行中都找到了错误修复。所以ChatGPT在修复bug时似乎有比较高的方差。然而,对于最终用户来说,这意味着多次执行请求会很有帮助。
此外,ChatGPT 解决与 Codex 相同数量的问题也就不足为奇了,因为 ChatGPT 和 Codex 来自同一语言模型系列。但是,我们仍然看到 ChatGPT 的改进潜力,因为给定的响应通常接近于正确的解决方案。尽管如此,我们的评估非常严格,只有在 QuixBugs 引入的错误确实得到识别和纠正的情况下才认为补丁是正确的。例如,对于某些问题,ChatGPT 建议完全重新实现,这样就不会出现错误。然而,这些可能不是真正的错误修复,因为引入的错误不是本地化的。我们假设 ChatGPT 只是重现了它在这里学到的东西。此外,如果 ChatGPT 建议的其他更改引入了阻止程序正常运行的新错误,我们不会将错误视为已修复。此外,在本次评估中仅发送一个请求,我们并没有充分利用对话系统的潜力。因此,当我们与系统进行更多交互时,我们会仔细研究 ChatGPT 的行为,并为其提供有关错误的更多信息。
B.ChatGPT答案的分类
在使用 ChatGPT 时,我们注意到 ChatGPT 对我们的请求提供了不同类型的响应,特别是在无法找到错误时。因此,我们针对 QuixBugs 的基准问题识别了 ChatGPT 的不同类型答案,并分析了它们的频率。我们确定了以下几类 ChatGPT 答案:
需要更多信息:要求提供有关程序行为的更多信息以识别错误。未发现错误:未发现错误并表明程序运行正常。提供正确的修复:为正确的错误提供正确的修复。尝试修复其他问题:未找到预期的错误,并尝试修复其他并非真正错误的问题或提供建议,或针对边缘情况进行调整。提供修复但引入新的错误:为目标错误提供正确的修复,但在其他地方引入新的错误。替代实现:不修复错误,但提供可行的替代实现。图 2 显示了针对 QuixBugs 问题给出的已识别类别的 ChatGPT 答案的出现次数。
我们发现,对于我们的大多数请求,ChatGPT 都会要求提供有关问题和错误的更多信息。在给出的答案数量第二多的情况下,我们观察到 ChatGPT 声称给定的代码片段似乎没有错误。在这两种情况下,充分利用 ChatGPT 提供的对话系统的可能性可能会很有用,因为进一步的信息可能会导致正确的错误修复。
与请求更多信息相比,我们观察到 ChatGPT 修复了错误,但同时引入了新的错误,或者我们看到 ChatGPT 并未真正正确地解决了错误,但建议针对该问题提供全新的工作重新实现,这种情况很少见。
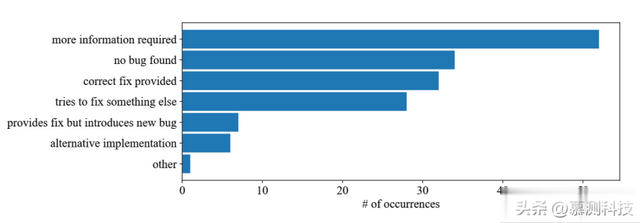
图 2 针对 QuixBugs 的问题给出的已识别类别的 ChatGPT 答案的出现次数。
C.与ChatGPT的讨论
为了能够以标准化的形式将 ChatGPT 与其他系统进行比较,我们到目前为止已经研究了 ChatGPT 如何对发出一个请求时的反应。然而,ChatGPT 的一个潜在强大优势是我们可以在对话中与系统交互以更详细地指定请求。这很有用,因为文本描述和测试套件给出的定义都可能不明确并且可能产生误导。
因此,我们研究了两个基准问题 ChatGPT 在对话中的行为方式,以及是否可以通过与系统讨论问题来找到可行的解决方案。我们选择 和 作为基准问题,因为在我们之前的实验中,无法正确修复这两个问题所包含的错误。此外,这些问题由相对较少的代码行组成,这使我们能够详细讨论这些问题。
图 3 显示了与 ChatGPT 讨论该问题的示例(第1-8行)。在第一个响应(第 10-15 行)中,ChatGPT 没有提供任何解决方案。它要求提供有关错误的更多信息(我们在许多其他问题中观察到这种行为,请参阅第 B 节)。由于给定的函数会导致许多可能的输入出现递归问题,因此我们为 ChatGPT 提供了一个精确的输入示例以及来自 Python 的结果错误消息(第 17-19 行)。通过提及递归问题,最终的响应朝着正确的方向发展,我们得到了一个正确工作的修补版本(第 30-34 行)。
在图 4 中,我们看到了与 ChatGPT 讨论该问题的示例(第 1-9 行)。 ChatGPT 再次要求提供有关问题的更多信息以及导致错误的输入(第 11-13 行)。作为后续请求,我们向 ChatGPT 提供该函数应执行的操作的描述(基于 QuixBugs 的代码注释),并忽略示例输入的请求以查看 ChatGPT 的反应(第 15 行和第 16 行)。我们可以在下面的答案(第 18-25 行)中看到,ChatGPT 的第一个和第二个答案之间存在明显的关系,因为现在我们得到了如何使用一些测试输入来测试该函数的解释。我们以测试输入的问题描述进行响应,并描述可能存在无限循环问题(第 27 行和第 28 行)。 ChatGPT 使用四个代码片段进行响应,其中前两个(第 34-48 行)没有解决无限循环的问题,最后两个(第 50-59 行)已完成,但可以重新实现,但不能直接解决包含错误。看起来,ChatGPT 只是在这里返回了一些与问题讨论内容相符的函数,尽管 ChatGPT 提到的测试用例表明前两个函数无法正常工作。此外,该错误并不是通过在给定函数中将 n ^= n - 1 替换为 n &= n - 1 来简单修复的,但正如已经提到的,ChatGPT 返回两个完整的重新实现。然而,对于基于语言模型的方法来说,这两个观察结果并不特别令人惊讶。尽管如此,给出的答案对于程序员来说还是有用的,因为它们有助于解决问题。

图 3 与 ChatGPT 讨论 QuixBugs 的问题。我们以粗体插入请求和响应标记,以使聊天历史记录更易于阅读。

图 4 与 ChatGPT 关于 QuixBugs 问题的讨论。我们以粗体插入请求和响应标记,以使聊天历史记录更易于阅读。此外,我们在某些地方缩短了 ChatGPT 的响应,以使示例尽可能小。当我们遗漏大文本段落时,我们会在文本中进行标记。
D.ChatGPT的系统后续请求
接下来,我们进行了一项研究,系统地与 ChatGPT 进行讨论。对于 ChatGPT 未正确解决所包含错误的程序(参见表 I),我们向 ChatGPT 提供后续请求,给出提示,如第C 节中所述。我们在表二中报告了我们的结果。我们使用与之前相同的表示法,此外,带有星号 (3*) 的复选标记定义已找到解决方案,而在此运行中不需要后续请求。
对于 9 个基准测试问题,我们发现更详细的 bug 描述对 ChatGPT 很有帮助。对于 3 个基准测试问题,本次运行中不需要后续请求,因为在我们的第一个请求给出的响应中已正确解决了该错误。总体而言,向 ChatGPT 添加提示极大地提高了其性能,解决了40个问题中的 31 个。因此,ChatGPT 提供了一种令人兴奋的自动程序修复新方法。
表 2 ChatGPT 取得的结果以及针对未解决的基准问题的后续请求中提供的附加信息(参见表 1)
3.2 结论
值得注意的是,ChatGPT 目前正在积极开发中。在我们的研究过程中,它发生了重大更新,这可能会影响我们的结果。尽管我们观察到更新前后的可修复率相似。然而,未来的版本可能会产生不同的结果。此外,ChatGPT 允许与其用户进行对话。提出与本研究中提出的问题不同的问题可能会对结果产生不同的影响。为了减轻这种对有效性的威胁,我们进行了一项预研究,改变了提出的问题。我们注意到对结果没有重大影响。此外,结果可能会有所不同,具体取决于编程语言、基准测试的大小以及基准的大小 发出的查询数量。为了减轻这些威胁,我们选择了一个标准的基准测试集,并针对最流行的编程语言 Python。结果的分类是手动完成的,因此代表了作者的主观评估。为了验证我们的结果,我们在线提供了与 ChatGPT 的对话。
为了支持程序员发现和修复软件错误,已经提出了几种自动程序修复(APR)方法。最近推出的基于深度学习 (DL) 的对话系统 ChatGPT 还可以提出改进错误源代码的建议。然而,到目前为止,这些建议的质量尚不清楚。因此,我们在这项工作中将 ChatGPT 的自动错误修复性能与 Codex 和几种专用的 APR 方法进行了比较。
我们发现 ChatGPT 在标准基准集上具有与 Codex 和基于 DL 的专用 APR 相似的性能。它的性能远远优于标准 APR 方法(修复了40个错误中的19个错误和7个错误)。使用 ChatGPT 的对话选项并在后续请求中为系统提供有关错误的更多信息,可以进一步提高性能,总体成功率为 77.5%。这表明人工输入对自动化 APR 系统有很大帮助,而 ChatGPT 提供了这样做的方法。
尽管其性能出色,但问题是验证 ChatGPT 答案所需的心理成本是否超过了 ChatGPT 带来的优势。也许结合自动化方法来为 ChatGPT 提供提示以及自动验证其响应(例如通过自动化测试),将使 ChatGPT 成为一个可行的工具,帮助软件开发人员完成日常任务。
我们希望我们的结果和观察将对 ChatGPT 的未来工作有所帮助。
转述:王朝澜
