Identify and Update Test Cases When Production Code Changes: A Transformer-Based Approach
Xing Hu; Zhuang Liu; Xin Xia; Zhongxin Liu; Tongtong Xu; Xiaohu Yang
引用
Hu X, Liu Z, Xia X, et al. Identify and Update Test Cases When Production Code Changes: A Transformer-Based Approach[C]//2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2023: 1111-1122.
论文:https://ieeexplore.ieee.org/abstract/document/10298577/authors#authors
摘要
CEPROT是一种基于Transformer的自动化方法,用于检测和更新随生产代码变化而变得过时的测试用例。该方法通过两个阶段操作:首先是识别哪些测试用例因代码变更而变得不再适用,然后自动将这些测试用例更新至最新版本。实验结果显示,CEPROT在识别过时测试用例方面表现出高精确度和召回率,并且能够显著提高测试用例的质量与代码覆盖率,从而促进测试与代码的同步演化。主要分为引言、方法、实验设计及结果、动态及人工评估这四部分。
1 引言
软件测试对于确保软件系统的质量至关重要,它帮助开发人员识别潜在的缺陷。在软件的生命周期中,随着新需求的增加和问题的解决,源代码会不断变化,相应的测试用例也应当随之演化。但是,由于项目进度紧张和缺乏足够的知识来识别测试是否需要更新,测试用例往往无法与生产代码同步演化。这导致了过时的测试用例可能无法正确测试代码变更,甚至可能隐藏生产代码中的错误。
文章通过项目Conekta的例子说明了过时测试用例的影响,其中API版本在生产代码中的更新与测试用例中的更新之间存在两年多的时间差。尽管生产代码通过了测试并未报告失败,但新版本的API在这段时间内从未被测试,这可能导致无法发现生产代码中的潜在问题。此外,许多技术已被提出来挖掘和分析生产代码与测试代码的共同演化规则和模式,例如,通过关联规则挖掘技术来生成共同演化模式,以及使用机器学习技术来促进生产和测试代码的共同演化。
然而,现有方法在预测现有测试代码是否需要随生产代码变更而更新方面表现不佳。因此,本文提出了CEPROT,一种新颖的两阶段方法,用于自动化地识别过时的测试用例并根据生产代码的变化自动更新它们。与以往只识别过时测试用例的研究不同,本文进一步提出了更新这些过时测试用例的方法,旨在减少维护成本,避免引入新的错误,并促进生产代码和测试代码的共同演化。
2 方法
2.1 概述
CEPROT旨在自动化生产代码与测试代码的共同演化任务,其整体框架由三个阶段组成:输入构建、模型训练和在线生产-测试共同演化应用。在输入构建阶段,将输入令牌转换为嵌入向量,然后输入到神经网络中。模型训练阶段进一步分为两个子阶段:过时测试识别和过时测试更新。在过时测试识别阶段,训练一个神经网络分类器来识别需要更新的过时测试;而在过时测试更新阶段,训练更新器模型生成新的测试用例。与识别阶段不同,更新阶段仅使用正面样本进行训练,并将新测试用例视为生成的基准真值。在线应用阶段中,给定代码变更(包括两个版本的生产代码和编辑序列)及其关联的旧测试,CEPROT首先利用训练好的识别器预测旧测试用例是否需要更新。如果需要,训练好的更新器将被用来生成一个新的测试用例来替换旧的测试用例。如图1所示,整个框架展示了CEPROT自动化生产-测试共同演化任务的流程。

图1 整体方法概览
2.2 输入构建
模型的输入包括原始生产方法x,更新后的生产方法,以及原始测试t。如图1所示,对于每个代码段,我们首先将其标记化为一系列标记,即,,和,其中m、n和l分别表示原始方法、更新方法和原始测试的长度。我们利用Roberta标记器来获取这些标记。不同于通过根据空白字符分割源代码来构建标记的方法,它利用字节对编码(Byte-Pair Encoding,BPE)来缓解词汇外(OoV)问题。此外,我们还为代码更改构建编辑序列e。对于编辑,我们将这三部分连接起来表示编辑。通过比较位置i上的标记和得到。输入x、、e、t然后被连接成一个输入I,用于预测目标中的概率分布。在识别任务中,目标l=0,1表示测试不需要更新或需要更新,分别对应0和1。对于更新任务,目标是正样本的更新测试用例。模型旨在尽可能准确地生成新的测试用例。在本工作中,我们将不同的输入连接成一个输入,而不是使用多编码器分别编码每个输入。与多编码器相比,一个输入有利于使用CodeT5中的自注意机制捕捉不同输入之间的关系。
2.3 过时测试识别
在此阶段,我们提出一个过时测试识别器,以确定测试用例是否需要更新。它包括一个编码器和一个分类器。
1) 编码器:编码器负责获取输入序列的上下文代表嵌入。在本文中,我们利用预训练的CodeT5编码器来初始化输入I。CodeT5在代码理解和生成方面展示了有希望的结果,因为它能够强有力地捕捉开发者分配标识符所传达的代码语义。CodeT5是基于Transformer的预训练模型。Transformer的编码器将输入I转换为上下文向量表示R。
对于每个输入标记,Transformer为其生成三个嵌入,即查询向量,键向量和值向量。Transformer编码器利用点积通过使用每个输入中的查询向量和键向量来计算的注意力分数,公式如下:

其中d是和的维度。注意力分数表示在编码第i个输入时,我们对第j个输入的关注程度。然后,CEPROT通过softmax函数获得归一化分数:
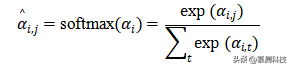
为了学习相关/不相关的标记,使用softmax来乘以每个值向量,并将这些向量相加:

我们使用最后的隐藏状态作为输入I的上下文向量表示R。
2) 分类器:这一步旨在根据学习到的表示R进行二元分类。为了更好地捕捉这四个输入信息()之间的关系,我们使用一个配备有非线性函数的密集层来学习它们之间的潜在交互。然后,密集层的输出用于预测最终标签的可能性。更具体地说,分类器定义如下:

W和b分别表示权重矩阵和偏置向量。tanh是密集层感知器的激活函数。Softmax函数将输出标签l在0和1之间的最终概率。对于概率得分,如果原始测试需要更新,我们希望这个得分高;如果测试不需要更新,我们希望这个得分低。
2.4 过时测试更新
在此阶段,我们提出一个过时测试更新器,以更新需要更新的过时测试用例。它也包括两个部分,一个编码器和一个解码器。
1) 编码器:我们利用与过时测试识别器相同的编码器来作为过时测试更新器的编码器。更新器的输入也包括四个部分,即。由于输入的不同部分对要生成的测试的不同部分有贡献,我们应学习输入I的每个标记与目标更新测试之间的相关性。因此,与识别任务不同,我们使用注意力分数来代替最后的隐藏状态作为解码器的输入。
2) 解码器:不同于识别任务,过时测试更新应根据输入生成新的测试用例。解码器学习根据输入和迄今为止生成的所有前置标记一个一个地生成相应的新测试。数学上,测试更新任务定义为找到,使得:

其中为:

可以看作是给定输入I的预测新测试的条件对数似然。该模型可以通过最小化预测测试用例和基准真值之间的负对数似然来训练。
具体来说,解码器的架构由两个部分组成,即自注意层和编码器-解码器注意层。自注意层的计算与编码器相似,只是它只处理迄今为止生成的标记。编码器-解码器注意层学习输出序列与输入序列之间的相关性。当计算编码器和解码器之间的注意力分数时,关键向量K来自编码器的输出。目标词和源代码标记之间的注意力分布为:
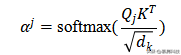
具体来说,识别器和更新器由CodeT5初始化,并分别在两个任务上进行微调。
2.5 在线生产-测试共同演化
在线生产-测试共同演化阶段是CEPROT框架的应用实施,它允许开发者在对生产代码进行更改时,利用CEPROT来识别测试用例是否需要更新。如果检测到测试用例已经过时,CEPROT将自动生成一个新的测试用例,以确保新生产的代码得到正确测试。这一阶段结合了前面训练好的模型,确保了生产代码和测试代码能够同步演化,从而维持软件质量并减少因代码变更引入的错误。
3 实验设计及结果
3.1 实验设置
在本研究中,我们旨在识别并更新方法级别生产代码的过时测试用例。为此,我们构建了两个数据集,分别用于训练和评估CEPROT在两个阶段的性能。这些数据集是从包含大量高质量单元测试的Java项目中构建的。为了构建这样的数据集,我们需要收集带有@Test注解的共演化Java方法及其对应的测试用例,即原始方法、更新方法、原始测试和更新测试的四元组。
我们首先从Liu等人收集的大规模高质量数据集中提取共演化的方法级生产-测试样本。该数据集包含了来自Wen等人提供的前1500个流行Java项目的6106K个方法级变化。我们请求他们提供数据集,并使用它来构建我们的数据集。
在构建共演化生产-测试样本时,我们认为在同一次提交中发生变化的方法和其对应的测试被视为共演化的生产-测试对。对于每个非测试方法(没有@Test注解),我们检查是否在同一次提交中存在相应的单元测试变化。根据Wang等人和Tufano等人的研究,测试名称通常与相应的生产方法相似,可以根据命名约定进行匹配。我们遵循他们定义的启发式规则,通过名称匹配提取方法的单元测试。
对于识别任务,我们需要构建包含正面样本和负面样本的数据集。如果测试用例需要随着其对应生产代码的变化而更新,我们将其标记为正面样本。否则,我们将其标记为负面样本。对于测试更新任务,我们仅使用识别任务中需要更新的正面样本来构建数据集。正面样本构建和负面样本构建以及测试更新数据集的详细信息如下:
正面样本构建包括从收集到的方法级代码变化中提取带有@Test注解的变更测试用例(即t和t'),使用Tree-Sitter提取测试用例名称,并通过名称匹配找到生产代码。如果在同一个项目中生产代码也在同一次提交中发生了变化,我们将其视为正面样本。最终,我们获得了9985个正面样本,每个样本包括四个部分,即原始方法、更新方法、原始测试和更新测试。
负面样本构建需要提取不需要更新的变更方法的测试用例。首先,我们排除正面样本中的方法,并为剩余的变更方法提取测试用例。对于每个候选变更方法,我们通过路径匹配和名称匹配搜索其测试用例。然后,我们排除测试用例有变化的样本,最终获得52565个负面样本,每个样本包括三个部分,即原始方法、更新方法和原始测试。
在数据过滤、分割和处理方面,为了避免重复样本对深度学习模型性能的影响,我们从收集到的数据集中移除了重复的生产方法样本。最终,我们分别获得了5196个正面样本和18329个负面样本。然后,我们为两个任务构建了训练数据和测试集。对于过时测试识别任务,我们随机选择了90%的正面样本和负面样本来训练模型,其余样本用于测试CEPROT的有效性。每个样本包括四个部分,即原始方法、更新方法、原始测试和标签。对于过时测试更新任务,我们仅使用正面样本,每个样本由原始方法、更新方法、原始测试和更新测试组成。我们的数据集详细信息如表1所示。
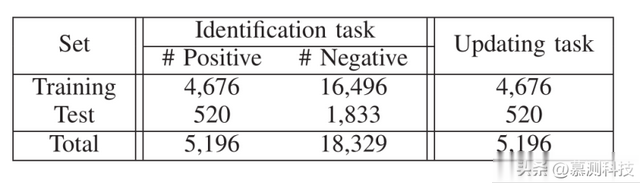
表1 数据集统计信息
此外,我们还进行了动态评估和人工评估,以进一步衡量CEPROT更新测试用例的质量和与生产代码变更的共演化性。我们选择了五个流行的Java项目,并为这些项目手动构建了不同版本。这些项目共有52个版本,每个版本对应一个代码变更。除了两个项目外,我们成功构建了所有其他项目的版本。在总共37个成功构建的版本中,有50个测试用例需要更新。然后,我们对这50个案例进行了动态评估和人工评估。
在评估CEPROT识别过时测试用例的有效性方面,我们将其与几种基线方法进行了比较,包括SITAR、K-最近邻(KNN)算法和长短期记忆网络(LSTM)。
SITAR是一种最先进的方法,旨在自动识别过时的单元测试。根据Wang等人的研究,随机森林分类器在测试更新预测方面表现优于其他分类器,因此我们在收集的数据集上复制了SITAR。
KNN是一种基于信息检索(IR)的方法,它通过比较测试集中的每个案例与训练集中的每个样本来识别过时的测试用例,并使用余弦相似性度量原始测试与返回的最相似样本之间的相似性。
LSTM是一种广泛使用的循环神经网络,我们用它来对输入进行编码,类似于CEPROT。然后,采用点积注意力机制融合输入信息,并使用softmax预测每个标签的概率。
对于更新过时测试用例的任务,由于据我们所知,之前没有关于自动化过时测试用例更新的工作,我们也使用了两种不同类型的基线方法进行评估,即KNN和神经机器翻译(NMT)模型。KNN方法将返回与训练样本最相似的更新测试作为KNN的最终生成结果。NMT模型基于LSTM,用于生成新的测试用例,并采用注意力机制以更好地学习解码器和编码器之间的相关性。
此外,由于CEPROT是一个两阶段方法,我们将识别阶段和更新阶段的基线方法结合起来,即KNN和NMT,以评估CEPROT在两阶段设置中的性能。
在评估指标方面,本文采用了准确度、召回率、F1分数以及CodeBLEU和准确率等指标。对于识别阶段,由于其可被视为二分类任务,因此采用了准确度、召回率和F1分数这些广为熟知的二分类性能评估指标。而在更新阶段,由于涉及到代码合成任务,使用了CodeBLEU来评估生成代码的质量,同时采用准确率来衡量生成测试用例与参考测试用例完全一致的能力。
在实验设置方面,本文使用了PyTorch框架来实现CEPROT,并使用了AdamW优化器和CodeT5基础模型进行训练。训练过程中,我们设置了学习率为1e-5,批量大小为2,并进行了15个周期的训练。所有实验都在安装有NVIDIA GeForce RTX 2080 Ti GPU的Ubuntu 20.04.3 LTS 64位系统上进行。
3.2 研究问题
RQ1: CEPROT在过时测试识别方面的有效性如何?
RQ2: CEPROT在过时测试更新方面的有效性如何?
RQ3: 给定代码变更时,CEPROT能否通过两个阶段有效实现生产测试代码的共同演化?
RQ4: CEPROT的效率如何?
RQ1 CEPROT在过时测试识别方面的有效性如何?
实验设计:为了评估CEPROT在识别过时测试用例方面的有效性,我们将其与几种基线方法进行了比较,包括SITAR、K-最近邻(KNN)算法和长短期记忆网络(LSTM)。比较的指标包括精确度、召回率和F1分数。
实验结果:CEPROT在过时测试识别任务上取得了98.3%的精确度、90.0%的召回率和94.0%的F1分数,显著优于所有基线方法。特别是,与KNN、SITAR和LSTM相比,CEPROT的F1分数分别提高了21.3%、80.8%和1.5%。这些结果表明CEPROT能够有效地识别出需要更新的过时测试用例。此外,表2展示了不同方法在过时测试识别任务上的表现,CEPROT在所有评估指标上均表现最佳。

表2过时测试识别和更新评估
RQ2 CEPROT在过时测试更新方面的有效性如何?
实验设计:为了评估CEPROT在更新过时测试用例方面的有效性,我们将其与KNN和NMT两种基线方法进行了比较。评估指标包括CodeBLEU和准确率,以衡量生成的测试用例的质量。
实验结果:CEPROT在更新过时测试用例任务上表现出色,其CodeBLEU分数为63.1%,准确率为12.3%,大幅度领先于KNN和NMT基线方法。具体来说,CEPROT在CodeBLEU上比KNN和NMT分别提高了65.9%和96.6%,在准确率上分别提高了215.4%和146.0%。这些结果证明了CEPROT在生成语法正确、与人类编写的测试用例质量相近的测试用例方面具有很高的能力。如表2所示,CEPROT在更新任务上的所有评估指标上均优于基线方法。
RQ3 给定代码变更时,CEPROT能否通过两个阶段有效实现生产测试代码的共同演化?
实验设计:为了探究CEPROT在结合识别和更新过时测试用例的两阶段过程中的有效性,我们将其与基线方法在两阶段设置中的表现进行了比较。评估的指标包括#TPC/#TP(正确更新的真阳性样本数与真阳性样本总数之比)和#FPC/#FP(未更新的假阳性样本数与假阳性样本总数之比)。
实验结果:CEPROT在两阶段评估中表现卓越,显著优于KNN和NMT基线方法。具体来说,CEPROT在识别过时测试用例阶段展现出更高的精确度,并在更新阶段以更高的准确率更新了真阳性和假阳性样本。表3展示了不同方法在两阶段应用中的评估结果,CEPROT在所有比较指标上均优于基线方法。特别是,CEPROT在预测的真阳性样本上的准确率达到了13.2%(62/468),远高于KNN的5.3%(20/376)和NMT的2.4%(11/464)。此外,尽管CEPROT的性能并不完美,但其高精确度和召回率有助于开发者发现尽可能多的过时测试用例,并减少误报。同时,CEPROT尝试正确更新过时测试用例,并不更新假阳性测试,以减少冗余更新。

表3两阶段应用中的评估结果
RQ4 CEPROT的效率如何?
实验设计:为了衡量CEPROT方法及其他基线方法的时间复杂度,我们记录了它们训练过程和测试过程的开始与结束时间。所有模型均在同一台配备NVIDIA GeForce RTX 2080 Ti GPU的机器上进行训练和评估,以保证比较的公平性。
实验结果:表4展示了不同方法在训练和每样本平均推理时间上的成本。结果显示,CEPROT在训练阶段需要1小时21分钟,在推理阶段需要0.062秒来识别过时测试,在2小时44分钟的训练后,需要0.975秒来更新测试用例。尽管训练时间因数据集大小而异,但一旦模型训练完成,CEPROT能够在微秒级时间内完成测试用例的识别和更新。这些实验结果表明,CEPROT在实际应用中是高效的。
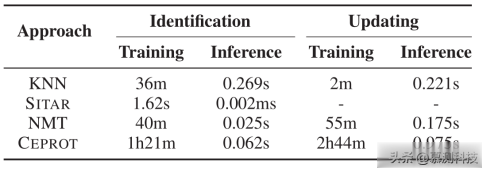
表4 CEPROT训练和推理时间
4 动态及人工评估
动态评估方面,选择了五个Java项目进行测试,这些项目随机选取且均拥有超过500星的评级。针对这些项目,手动构建了不同版本,并统计了成功构建的版本数以及需要更新的测试用例数。使用JaCoCo工具测量了CEPROT更新测试用例的编译能力和覆盖率。结果显示,CEPROT更新的测试用例中有48%能够成功编译,平均语句覆盖率达到了34.2%,相较于过时测试用例有显著提升。

表5 动态和人工评估结果
人工评估方面,邀请了三位拥有超过五年Java开发经验的高级工程师对通过编译的测试用例进行质量与共同演化性评估。质量评估依据测试实践标准,评分范围为1到5分。共同演化性评估则是判断更新的测试用例是否与生产代码变更保持一致。评估结果显示,CEPROT更新的测试用例平均质量得分为3.81,其中66%的测试用例与生产代码变更共同演化。尽管人工编写的过时测试用例的质量得分较高,但CEPROT更新的测试用例在共同演化性方面表现更佳。

图2 更新案例
为了深入理解测试用例与生产代码变更的共同演化,研究者手动检查了CEPROT的更新情况,并识别了几种主要的更新类型,包括API调用、标识符和修饰符的更新。这些更新表明CEPROT能够精确捕捉到代码变更的细节,并相应地调整测试用例。尽管CEPROT在所有评估指标上均优于基线方法,但在时间序列评估中,所有方法的性能都有所下降,尤其是在面对未来代码变更时。此外,研究者还探讨了CEPROT失败的原因,主要是生成的测试用例不完整,尤其是在处理长测试用例时。最后,研究者讨论了更新测试代码相对于从头开始生成的优势,并指出尽管存在一些有效性威胁,CEPROT在实际应用中仍具有潜力。
转述:田方源
