摘要
在量化投资领域,因子筛选和合成是构建有效选股组合的核心步骤。传统线性模型在处理因子非线性预测能力时存在局限,因此我们考虑是否可以借用机器学习模型(例如树模型、神经网络模型等)来挖掘因子非线性的预测能力。本报告重点探讨了使用树模型来提升多因子选股指数增强模型的效果。通过对比回归和分类模型、分析特征筛选的必要性、特征间的相关性,以及特征重要性指标,我们验证了XGBoost算法在因子筛选和合成中的应用潜力,并且在沪深300、中证500和中证1000指数增强中进行了不同参数和不同模型的较为全面的测试。
树模型用于因子合成与筛选的五问五答:
回归or分类?在量化因子选股的场景中,尽管股票收益率是连续变量,但考虑到收益率绝对值预测难度高等问题,我们常倾向于将问题转换为预测高收益和低收益股票的分类问题。测试结果也表明,XGBoost分类模型在沪深300成分股上的多头收益表现优于回归模型,分类树模型在量化因子选股场景中存在一定优势。
特征是否需要提前筛选?我们探讨了特征筛选在机器学习任务中的作用,包括提高模型性能、降低计算复杂度和增强模型可解释性。尽管特征筛选在高维数据处理中至关重要,但我们的测试发现XGBoost算法能够有效处理高维特征和特征间的相关性,减少了特征预筛选的必要性。
如何处理特征之间的相关性?特征(因子)之间的高相关性可能带来的问题包括:模型不稳定、难以解释、信息冗余。我们讨论了特征选择、降维、正则化和集成方法等策略来应对这一问题。由于XGBoost算法本身已经是集成模型,可以一定程度缓解高相关性的问题,因此在本文的测试场景下特征相关性的处理对模型的影响相对较小。
选择哪种特征重要性?XGBoost提供了'weight'、'gain'和'cover'三种评估特征重要性的指标。不同计算方法下的特征重要性排名存在差异,'weight'类型的特征重要性排名靠前的因子中基本面类型因子的占比较高,而‘gain’、‘cover’给出的重要性排名较为接近,价量类型的因子占比显著更高。
是否需在成分股内训练?对于沪深300、中证500和中证1000这三个宽基指数,我们预期树模型等机器学习模型的应用也需要对不同的指数进行差异化的训练范围选择。测试结果支持了我们的观点,即在沪深300指数增强中,成分股内训练的模型表现优于全市场训练的模型。
宽基指数增强中的应用:
我们提出了两种策略:模型信赖型策略和模型微调型策略,用于在不同宽基指数上进行指数增强。模型信赖型策略依赖于XGBoost分类模型给出的因子特征重要性排序来决定使用的因子和权重,而模型微调型策略则依赖于原指增模型确定的因子和权重,使用XGBoost分类模型的特征重要性进行微调。
1)沪深300指数模型微调型增强策略2015年以来年化超额收益8.4%,相比原组合提高了1.3个百分点,信息比由2.07提升至2.19;2)中证500指数模型微调型增强策略2015年以来年化超额收益17.0%,相比原组合提高了1.1个百分点,信息比由2.71提升至2.87;3)中证1000指数模型信赖型增强策略2018年以来年化超额收益22.3%,相比原组合提高了0.98个百分点,信息比略微下降,但近3年的表现有明显提升。
风险提示:本篇报告对于各类因子表现结论以及指数增强模型均基于历史数据,历史回测表现不代表未来,并不构成投资意见。
正文
树模型用于因子合成与筛选的五问五答
因子筛选和合成作为因子挖掘研究中十分关键的步骤,最传统和常见的方案是基于线性模型的方法,通常会由分析师根据经济逻辑和回测表现来选择。例如在成长、盈利、估值、动量&反转、波动等等大类因子中,筛选各个大类中历史因子IC表现较好的因子作为入选因子,并进一步根据因子的过去一段时间的表现(滚动IC、滚动ICIR或者线性回归的Beta)来确定因子复合加权的权重。我们前期的指增模型《量化多因子系列(9):宽基指数增强2.0体系》中使用的也是线性的加权方法(滚动最优化ICIR)。
但正如我们在报告《量化多因子系列(2):非线性假设下的情景分析因子模型》中所提到的,量化因子研究中因子在不同特征的股票上会存在非线性的预测能力。因此我们很自然的想到,是否可以借用机器学习模型(例如树模型、神经网络模型等)来挖掘这些非线性的预测能力。
图表1:机器学习模型进行因子筛选和合成的优劣势

资料来源:Wind,中金公司研究部
本文中我们将主要验证树模型(以XGBoost为例)能否帮助提升传统的多因子选股指数增强模型的效果,以及怎样选择模型的类型和相关参数如何设置。
回归还是分类
回归和分类模型层面的差异和对比
在使用类似XGBoost等树模型来进行个股收益的预测时,我们常首先遇到的一个选择是,使用回归模型还是分类模型?首先我们简单的回顾一下树模型中回归模型和分类模型的差异。
1、目标函数:在回归问题中,通常使用均方误差(MSE)或均方根误差(RMSE)作为损失函数;在分类问题中,可以使用多种损失函数,如逻辑回归损失(适用于二分类问题)或多项式逻辑回归损失(适用于多分类问题)。
2、输出:回归模型的输出是连续的数值,预测结果通常是实数;分类模型的输出是离散的类别标签,预测结果是一个类别或类别的概率分布。
3、树的构建:回归树可能会更关注最小化误差的累积;分类树可能会更关注类别的区分度。
量化选股领域的模型选择:分类或许更合适
在我们的量化选股领域研究中,我们通常预测的目标是未来一段时间的股票收益,股票收益率通常是连续的变量。不过在研究中其实我们是有一定的倾向将预测变量从连续变量转为离散变量的:也就是说相比直接去预测股票收益,更倾向于将问题转换为预测收益较高的股票与收益较低的股票。例如,我们可以将收益率前30%的股票分类为‘1’,将后30%的股票分类为‘-1’,其余的股票分类为‘0’。
使用分类模型的优势可能包括以下几点:
► 准确预测股票未来收益率的具体数值是难度较高的,同时模型还可能会过拟合,无法对样本外的收益进行有效预测。分类模型往往稳健性更高,过拟合的程度相对更低。
► 部分投资者更关心胜率而不是平均收益。基本面投资者一般会更倾向于使用胜率更高的模型,因此分类模型可能更符合这类需求。
► 基于分类的模型与量化因子模型中常用的线性回归框架存在差异,因此可以提供一定的低相关的增益信息。
模型结果表现对比
我们使用沪深300成分股来做一个对于XGBoost分类模型与回归模型的效果对比,计算两种方法下的多头股票组合收益。分类模型时我们取每个截面收益率排名前30%的个股分类为‘1’,排名后30%的个股分类为‘-1’,其余个股分类为‘0’。具体的分类模型和回归模型的测试流程和参数如下:
特征(因子)集:中金量化策略团队开发的132个常见价量因子,以及88个基本面因子共220个因子。
调仓频率:月度
训练方法:滚动训练,避免单次训练带来的不稳定因素。具体来说,我们每次使用过去5年的数据作为训练集和验证集,验证集取总训练集数据的最后20%的样本数据,对未来6个月的目标作为样本外进行预测。我们将多期样本外数据拼合作为模型滚动样本外表现。滚动训练的方法详见报告《机器学习系列(3):如何结合树模型与深度学习的优势》。
持仓股票:分类模型时取每一期预测分类为1的股票,回归模型时取每一期预测排名前30%的股票。
模型参数:使用Optuna调参。详见报告《机器学习系列(3):如何结合树模型与深度学习的优势》。
图表2:沪深300内XGBoost分类模型与回归模型的多头收益对比
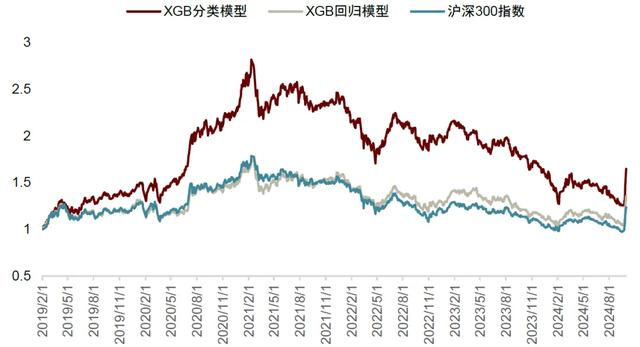
注:截至2024-09-30资料来源:Wind,中金公司研究部
从上述测试结果可见,XGBoost分类模型下预测得到的分类为‘1’的股票组合累计收益明显高于XGBoost回归模型下预测收益率排名前30%的股票。分类模型的持仓组合尽管超额并不稳定,但仍可获得年化6.7%的超额收益。回归模型的组合与基准指数沪深300指数的收益几乎没有差异,年化超额仅为0.9%。因此,我们认为测试的结果与前文的分析结论是比较吻合的,也就是说,XGBoost为代表的树模型在面对股票收益预测这一应用场景,采用分类模型比回归模型往往具有更好的预测效果。
特征是否需提前筛选
从学术界和业界的经验总结来看,特征筛选在树模型等机器学习任务中扮演着至关重要的角色,其重要性体现在下图所示的五个方面。
图表3:特征筛选在机器学习任务中的作用

资料来源:Wind,中金公司研究部
特征筛选在处理高维数据时也很重要。通过有效的特征筛选,可以大幅降低数据的维度,有效提升模型在高维空间的泛化性和优化效率。随着机器学习算法的不断迭代,也出现了一些能够较好处理高维特征和处理特征共线性的算法。例如本文中主要使用的XGBoost算法,是在梯度提升算法方面的改进。GBDT利用前向分布算法,迭代前一轮的弱学习器减少本轮误差。XGBoost可以并行处理,相比GBDT精度更高,但复杂度过高可能会消耗更多的内存。
为了检验提前对特征进行筛选是否会影响模型表现,我们做了一个比较简单的测试,对比在沪深300内使用纯基本面因子和使用基本面+价量因子进行XGBoost分类模型的表现。
图表4:沪深300内纯基本面因子和使用基本面+价量因子多头收益对比

注:截至2024-09-30资料来源:Wind,中金公司研究部
单纯使用基本面因子的XGBoost分类模型多头30%选股的效果略微优于使用基本面+价量因子的模型,且其优势主要体现在基本面因子较为强势的19-20年,在价量因子表现更好的22-23年则是基本面+价量因子的模型。由于沪深300成分内基本面因子的有效性整体强于价量因子,从结果来看使用纯基本面因子时表现较好,而加上价量因子后对模型有一定的拖累但影响有限,这一结果说明XGBoost是可以较好的识别有效因子以及处理因子之间的相关性的。
因此总体上来看我们认为使用XGBoost时,特征的预筛选或者预处理的必要性相对没有那么强,可以考虑将较为全量的数据给模型自主进行学习。
如何处理特征之间的相关性
在选股领域,因子之间的高相关性确实可能带来一系列问题,影响机器学习模型的性能和可靠性。这些问题主要包括:1)模型不稳定:高度相关的因子可能导致模型参数估计不稳定。小的数据变化可能导致模型系数大幅波动,使得模型在不同时期的表现差异很大。2)难以解释:当多个高度相关的因子同时存在时,很难确定哪个因子真正对股价预测起关键作用,降低了模型的可解释性。3)信息冗余:高度相关的因子可能提供重复的信息,增加了计算复杂度但并未带来额外的预测能力。
通常我们为了应对这些问题,可以采用下面的几种处理方法:
√ 特征选择:使用如LASSO、弹性网络等方法选择最相关的因子子集。或者基于专业知识选择最相关的特征,舍弃冗余特征,这种方法在金融领域尤其是重视基本面逻辑的投资者中接受程度更高。
√ 降维:如PCA,可以在保留大部分信息的同时减少因子数量。
√ 正则化:在模型中引入L1或L2正则化,减少过拟合风险。
√ 集成方法:如随机森林,XGBoost等,可以在一定程度上缓解高相关性带来的问题。
综上我们认为在股价预测中,高度相关的因子既可能导致拟合不足,也可能导致过拟合。关键是要根据具体情况采取适当的处理方法,平衡模型的复杂度和预测能力。
在后续的模型构建中我们也将尝试通过特征选择和特征复合等方式,来检验特征相关性对模型预测能力的影响。不过由于XGBoost算法本身已经是集成模型,可以一定程度缓解高相关性的问题,因此在本文的测试场景下特征相关性的处理对模型的影响相对较小。
选择哪种特征重要性
前面我们分析发现在沪深300内测试的场景下,基于分类模型的预测效果显著优于回归模型。因此我们很自然的进一步需要思考,怎样将分类模型的训练结果用于指数增强的因子合成中呢?本文中我们主要考虑的方法是,使用分类模型训练得到的特征重要性作为因子加权的参考指标。
那么具体到我们本文使用的模型,XGBoost包含'weight'、'gain'和'cover'这三种用于评估特征重要性的指标,它们各自有不同的计算方法和侧重点:
图表5:XGBoost模型中的三种特征重要性含义

资料来源:Why do tree-based models still outperform deep learning on tabular data? Léo Grinsztajn et al., 2022,中金公司研究部
在实际应用中,选择哪种特征重要性计算方法取决于具体的需求和场景。如果关心特征对模型性能的实际影响,'gain'通常是首选。如果想要了解特征在模型中的使用频率,可以选择'weight'。而'cover'则适用于那些关心特征覆盖范围的场景,在处理一些分类特征时更为有效。
图表6:中证500指数内使用不同特征重要性指标的增强组合收益对比

注:截至2024-09-30资料来源:Wind,中金公司研究部
对比在中证500指数上增强的效果,从回测期来看,使用‘weight’重要性指标的增强组合收益相比其他两类有比较明显的优势。因此,反映特征在模型中的使用频率的重要性指标‘weight’一定程度上可以较好的体现不同因子在股票收益上的预测能力。后文中我们也将更多的使用‘weight’作为增强模型测试中反映因子重要性的指标。
是否需在成分股内训练
对于沪深300、中证500和中证1000这三个宽基指数,是否在成分股内训练的选择上是存在差异的。正如我们在报告《量化多因子系列(9):宽基指数增强2.0体系》中所提到的,沪深300指数的成分股的分布特征与中证500、中证1000存在较大的差异。很多因子(例如估值、动量等)在沪深300内与在其他选股域内的预测能力也存在很大的差异。因此我们预期机器学习模型的应用也需要对不同的指数进行差异化的训练范围选择,例如在进行沪深300指数增强时需要更聚焦于成分股内训练,而在中证1000指数增强时则可以选择在全市场训练。
我们仍然以沪深300为例,对比全市场训练和成分股内训练的XGBoost分类模型在沪深300内的增强选股效果,来验证我们的假设。
特征(因子)集:中金量化策略团队开发的132个常见价量因子,以及88个基本面因子共220个因子。
训练方法:每6个月滚动训练超参,每月更新因子权重并调仓。
模型及参数:XGBoost分类模型,使用Optuna调参。
因子权重设置:使用特征重要性(weight)排名前30的因子,经过标准化、调整极性后,基于特征重要性加权。
组合优化参数:行业偏离度30%,市值偏离度30%,成分股占比不低于80%。
图表7:沪深300内全市场和成分股训练的增强选股效果对比

注:截至2024-09-30资料来源:Wind,中金公司研究部
我们发现全市场训练的XGBoost分类模型在沪深300指增中的表现略逊于成分股内训练的模型,这个结果也基本符合我们的判断。由于沪深300指数的成分股在行业分布、个股权重偏离度、基本面特征、参与投资者类型上与全市场的其他个股差异较显著,因此全市场训练的模型可能可以比较好的捕捉全市场股票受因子的影响模式,但并不一定可能很好的捕捉沪深300成分股受因子影响的模式。
因此,成分股内训练在类似模型应用于沪深300增强的场景上还是有必要的,后面我们也将进一步的测试其他指数上成分股内训练和全市场训练的效果,并从中进行优选。
三大宽基指数增强的应用方法
训练流程及参数
这一章节我们将主要在沪深300、中证500和中证1000上做指数增强相关的模型和参数测试和验证,考虑到不同宽基指数的特点差异导致模型参数和模型细节的最优选择往往也存在差异,以及测试时树模型对特征的筛选和排序的训练结果可能存在过拟合或者经济含义较弱稳定性不足的问题,我们将在指增模型中对两种类型的策略做对比测试:模型信赖型策略、模型微调型策略。
(1)模型信赖型策略:主要依赖于XGBoost分类模型在每一期测试集中给出的因子特征重要性排序来决定使用哪些因子,且决定这些因子的权重。具体的,在确定了排名前30的因子后,我们会根据因子在训练集内的平均IC方向确定因子方向,再根据因子的特征重要性进行方向调整后的加权。
(2)模型微调型策略:主要依赖于原指增模型确定的因子和因子权重,XGBoost分类模型在每一期测试集中给出的因子特征重要性是用来对因子权重进行微调。具体的,在确定了模型的因子和每一期的因子权重(通常是ICIR最大化加权)后,我们会根据这些因子的特征重要性对原模型因子权重做上调或下调。
模型微调型策略的主要优势是:可解释性和透明度。基于树模型给出的特征重要性,我们可以更直观的了解树模型目前所青睐的特征有哪些,从而参考这些结果来调整我们已有的模型(因子权重等)。因此微调型策略在可解释性和透明度上都更有优势,更易于被看重基本面逻辑的投资者所接受。
图表8:模型信赖型策略和模型微调型策略具体参数

资料来源:中金公司研究部
沪深300:成分股内训练的微调型策略
在报告《量化多因子系列(1):QQC综合质量因子与指数增强应用》中,我们搭建了基于QQC综合质量因子的沪深300指数增强模型。采用包括估值因子、动量因子、换手率因子、一致预期类因子在内的沪深300内较为有效的因子,与QQC因子一同作为模型底层因子,同时选股范围限制在沪深300内,在控制了行业和市值偏离以及个股权重偏离度后,构建了沪深300指数增强组合(下文简称为QQC沪深300增强)。
沪深300指数XGBoost模型微调型增强策略
经过一系列的测试,我们发现沪深300增强适合使用微调型策略来构建,也就是说,我们在原有的基于逻辑和线性模型筛选的因子基础上,再根据XGBoost模型给出的特征重要性对每一期的因子权重做微调。重要性排名前20%的因子权重上调幅度60%,重要性排名后20%的因子权重下调幅度50%。具体的模型细节总结如下表:
图表9:沪深300指数模型微调型增强策略具体参数

资料来源:中金公司研究部
图表10:沪深300指数模型微调型增强策略净值
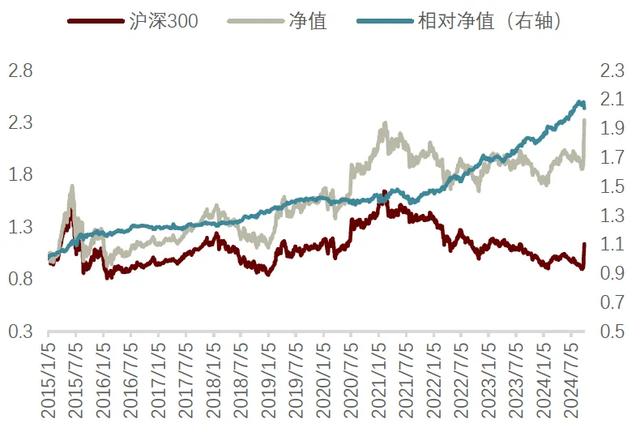
注:截至2024-09-30资料来源:Wind,中金公司研究部
图表11:沪深300指数模型微调型增强策略收益统计

注:截至2024-09-30资料来源:Wind,中金公司研究部
从测试结果来看,在沪深300指数成分股内训练XGBoost分类模型后再使用微调型策略的增强组合稳定性较好,2015年以来的年化超额收益为8.4%,相比原组合2015年以来的年化超额收益提高了1.3个百分点,信息比提高了0.12,由2.07提升至2.19。
尤其是2021年以来,组合在2022年和2023年均获得了不错的超额收益,2024年以来的年化超额也达到了14.7%,体现出XGBoost分类模型成分股内训练在近几年对沪深300组合因子权重的调整结果是比较成功的。
中证500:全市场训练的微调型策略
在报告《量化多因子系列(9):宽基指数增强2.0体系》中我们提到中证500与中证1000指数成分股的特征较为接近,无论是在行业分布,风格暴露还是个股权重分布上都更为接近,且这两个宽基指数成分股特征与沪深300指数都有比较明显的差距。因此我们预期,使用XGBoost进行因子合成时,中证500指增的最优训练域可能也与中证1000指数乃至全市场更为接近。
经过测试,我们发现中证500增强的确是使用在全市场训练的模型更为有效,且中证500与沪深300类似,也适合使用微调型策略来构建,也就是说,我们在原有的基于逻辑和线性模型筛选的因子基础上,再根据XGBoost模型给出的特征重要性对每一期的因子权重做微调。我们认为微调型策略更合适的原因可能为:近些年A股股票数量不断增加,中证500指数成分股已经不再是中小盘,从百分位上看中证500指数已经可以理解为中大盘指数,基本面类型因子在成分股内的有效性在逐渐提升。而如果使用模型信赖型策略,特征重要性排名靠前的因子往往由价量因子主导,导致稳定性下降。
中证500增强的具体模型细节总结如下表:
图表12:中证500指数模型微调型增强策略具体参数
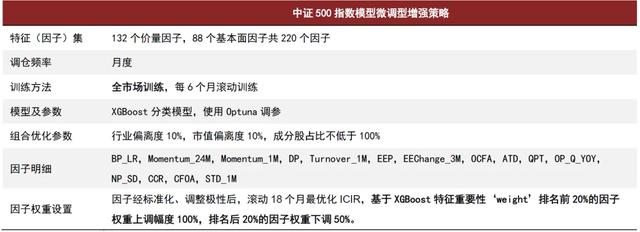
资料来源:中金公司研究部
图表13:中证500指数模型微调型增强策略净值

注:截至2024-09-30资料来源:Wind,中金公司研究部
图表14:中证500指数模型微调型增强策略收益统计

注:截至2024-09-30资料来源:Wind,中金公司研究部
从测试结果来看,在全市场训练XGBoost分类模型后再使用微调型策略的中证500增强组合稳定性较好,2015年以来的年化超额收益为17.0%,相比原组合2015年以来的年化超额收益提高了1.1个百分点,信息比提高了0.16,由2.71提升至2.87。
2021年以来组合均获得了不错的超额收益,2022年和2024年的年化超额均接近20%,仅2023年出现一定波动。相比指增2.0的组合可见,模型在近几年对因子权重的调整结果也是比较成功的。
中证1000:全市场训练的信赖型策略
在第一章中我们讨论了是否需要在成分股内训练,这个问题的答案其实也可以翻译为,目标基准的成分股特征是否与全市场相似。如我们前面的测试结果,沪深300指数为基准时,成分股内训练会得到更好的结果,而中证500增强的测试时我们发现全市场训练效果更优。中证1000指数中的测试结果也正如我们所预期的,全市场训练的效果的确更有优势。
另一个比较关键的选择是我们是否仍然采用微调型策略来构建中证1000增强。首先,从测试的结果上看,我们发现微调型策略相比原1000增强策略的改善有限。其次,我们发现使用模型信赖型策略(也就是完全参考XGBoost的特征重要性指标来选择和加权因子)时,样本外尤其是2022年以来中证1000增强具有更强的收益能力,2024年以来也可以获得年化16.6%的超收益,显著的优于原始模型。
中证1000增强具体的模型细节总结如下表:
图表15:中证1000指数模型信赖型增强策略具体参数

资料来源:中金公司研究部
图表16:中证1000指数模型信赖型增强策略净值
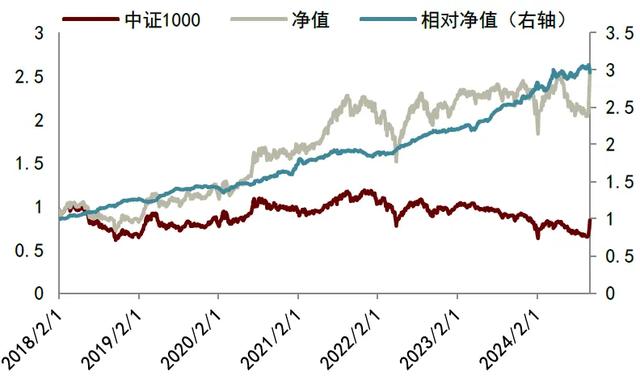
注:截至2024-09-30资料来源:Wind,中金公司研究部
图表17:中证1000指数模型信赖型增强收益统计

注:截至2024-09-30资料来源:Wind,中金公司研究部
我们选择了信赖型策略来搭建中证1000指数增强,且在全市场训练XGBoost分类模型。模型样本外(2018年)以来的年化超额收益为22.3%,相比原组合2018年以来的年化超额收益提高了0.98个百分点,信息比略微下降,但近3年的表现有明显的提升,2022年和2023年均可获得超过20个点的超额收益,2024年的年化超额也超过了15%。
风险提示:本篇报告对于各类因子表现结论以及指数增强模型均基于历史数据,历史回测表现不代表未来,并不构成投资意见。
文章来源
本文摘自:2024年10月25日已经发布的《量化多因子系列(14):XGBoost因子筛选与合成的指数增强应用》
分析员 周萧潇 SAC 执业证书编号:S0080521010006 SFC CE Ref:BRA090
分析员 郑文才 SAC 执业证书编号:S0080523110003 SFC CE Ref:BTF578
联系人 高思宇 SAC 执业证书编号:S0080124070007
分析员 陈宜筠 SAC 执业证书编号:S0080524080004 SFC CE Ref:BTZ190
分析员 刘均伟 SAC 执业证书编号:S0080520120002 SFC CE Ref:BQR365
法律声明

