国产大模型赛道的选手有很多,不管是大厂还是小厂,只要与AI沾边,都在探索自己的盈利和发展模式。
特别是在OpenAI说要严格限制接口调用之后,大家又兴奋了起来,纷纷推出各种优惠政策和推出新技术模型等等。
最近看了一圈国内的大模型,发现阿里云的通义千问已经跑到开源赛道第一名去了,Qwen2-72B 在世界开源模型排行榜上荣登榜首!


这是Hugging Face联合创始人兼首席执行 Clem Delangue 发的测试数据,他说本次新的榜单测试用了300张H100显卡,进行了多维度的重新评测。

大家对AI比较熟悉的话,应该见过这个Logo,在Hugging Face上经常能免费体验到各种模型功能。

这也是在新版v2规则测试下的结果,原版的测试太简单导致无法区分模型强度,而且有的模型开始了“刷题模式”,所以它们改进了一下测试规则,大致的基准内容如下。

对于最后的测试结果,自然是有人欢喜有人愁。去原推文下面看了一下,有表示欢迎新的测试方法的,也有开发者意识无法接受说新的方式测试集数据小,无法发挥其他模型实力的。

除了在开源领域,其他很多地方也有通义千问的影子,今天就来好好给大家盘盘,被大家吹爆的通义千问强在哪里。
截至2024年7月3日,通义千问官方最强的公开模型是它们自己在用的v2.5版本,开源最新的为Qwen2系列。


开源版本是榜首就很强了,而闭源的v2.5在5月份发布的时候,就说在权威基准OpenCompass上,性能全面赶超GPT-4了。

相信大家听到各家的模型超越OpenAI的GPT4,就和听到手机厂商的“吊打苹果”环节一样。
其实这个问题还真不好说,因为目前市场上的主流模型发挥都不稳定,面对千奇百怪的问题都有可能翻车。

而超过GPT4的话,从OpenAI的知名代表人物的话里可以看出,这个模型现阶段并不是符合他们预期的,他已经开始在预热GPT5了。

从这个角度看,现阶段各家说的超越也就可以理解了,这并不是说技术到了顶点而无法超越,而是大家都在摸索,比拼的是进度推进得如何。

而普通用户面对大模型,大家都学会了鸡蛋不能放在一个篮子里,都会选几家备用,挑选最好的回答。

所以光是问答还不行,还需要全面,什么写代码绘图做视频等等都要整上,而在这方面通义千问的模型也是“有备而来”。
根据能查到信息来看,在视觉比拼上,Qwen-VL在MME、Seed-Bench和TouchStone三个多模态大语言模型评测中登顶,成为业界SOTA 模型。

代码方面,专门用于编程的CodeQwen1.5也拿到了 Bigcode 模型排行榜第一的位置。
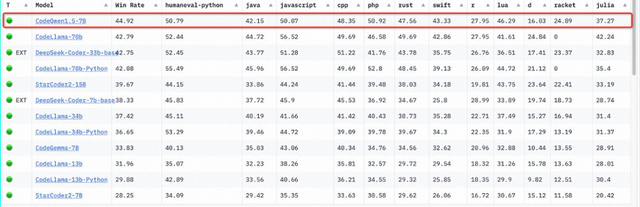
多语言方面还拿了个阿拉伯语的第一。

听起来挺厉害,光是这样说,其实大家也会想,找一些模型优势项目去比就可以了,不会的直接不宣传。对于普通用户来说,来自产品“同行”的评价可能更有参考价值。
像是360的创始人周鸿祎和猎豹移动的CEO,一个发视频表示祝贺,一个表示通义千问的开源模型都比很多闭源模型强了。



这样的国内评价网上有很多,而在国外评价上,通义千问的口碑也挺好,开发者们表示在训练以后,就算不是中文内容,表现也不错。

相较于其他的模型,阿里通义模型其实是属于主动积极那种,之前搞各种智能体,还有用来娱乐的照片跳舞,国内首位AI程序员入职,以及带头给大模型API大幅降价等等。


在模型官网上还有各种专业用途的“子版本”,用于法律的,教育辅助的等等,对比个人用的智能体来说进阶了不少,像是大家更为熟悉的微博、小米、VIVO等厂商也接入了通义千问,个人和企业用户都挺广。

从长远来看,通义千问的模型是在放长线钓大鱼,开源社区、国内外开发者、企业用户、个人用户、机构单位等都有它的身影,这个生态如果变成完全体,再搭配上阿里系原本的云服务体系,在AI相关的比拼中能取得很大的优势。
在其他AI工具还在单独完善某个领域功能的时候,通义千问在悄悄布局全球市场了,官方的博客里说之后的模型也会继续开源。

你可能又想起了那句话,国内的产品从0到1很难,但是从1到100速度是飞快的,在这件事上其实就能看出来一些。

现在来看,通义千问是有产生质变的能力的,希望以后能有颠覆性的功能出现,有了这些铺垫,那时候就能给全球用户整个更大的震撼!




国内资本开始收割了。用下来发现,牛逼吹的比较大。
真是open ai一出,原来没人听说过的阿猫阿狗就全都冒出来了