Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning
Chunqiu Steven Xia, Lingming Zhang
引用
Xia C S, Zhang L. Less training, more repairing please: revisiting automated program repair via zero-shot learning[C]//Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2022: 959-971.
论文:https://dl.acm.org/doi/abs/10.1145/3540250.3549101
摘要
在本文中,我们旨在重新审视基于学习的自动程序修复(APR)问题,并提出AlphaRepair,这是第一个以填空方式进行APR的方法,直接利用大型预训练代码模型进行APR,无需对历史bug修复进行微调/重新训练。AlphaRepair在广泛使用的Defects4J基准测试中的评估首次显示,无需历史bug修复的基于学习的APR可以大幅优于现有技术的APR。
1 引言
软件系统在日常生活中无所不在,从监控金融交易、控制交通系统到辅助医疗工具。这些系统中的软件错误可能影响全球人民并造成数十亿美元的财务损失。为了修复这些错误,开发人员通常需要投入大量人工工作。为了减少手动调试工作量,已经提出了自动程序修复(APR)技术,用于自动生成修复错误的补丁。
传统技术中,基于模板的APR技术利用预定义的修复模式将有问题的代码片段转换为正确的代码片段,被广泛认可为最先进技术。为了增加编辑的表达能力,研究人员最近开始利用机器学习(ML)或深度学习(DL)技术进行补丁生成。基于学习的APR技术通常利用深度学习的最新进展训练神经网络,将原始有问题程序转换为修复版本。然而,这些技术面临训练数据质量、数量和上下文表示等问题。
我们提出了AlphaRepair - 第一个以zero-shot学习设置下直接利用大型预训练代码模型生成补丁的填空式APR方法。与所有现有基于学习的APR技术不同,我们的主要见解是,与其建模修复编辑应该是什么样子,我们可以直接模拟/预测基于上下文信息的正确代码(类似于填空任务)。通过这种方式,我们的填空式APR可以避免所有现有技术的上述限制:1) 完全摆脱历史bug修复,2) 可以简单地在所有可能的开源项目中进行大规模训练,3) 直接预训练以基于周围上下文建模补丁,因此可以有效地编码补丁与其上下文之间的复杂关系。此外,虽然调整先前的APR技术以适应新语言并不容易(因为需要进行大量的代码/数据工程工作来准备历史bug修复),在我们的填空式APR下,将APR扩展到新语言可能就像在新语言中挖掘新的代码语料库一样简单!
虽然我们的填空式APR可以应用于各种预训练模型,但在本文中,我们使用最近的一个预训练代码模型CodeBERT[23]来实现AlphaRepair。与当前基于学习的APR工具使用有限数量的bug修复作为训练数据不同,CodeBERT直接使用来自开源项目的数百万代码片段进行预训练,从而能够提供各种编辑类型以修复不同的错误。我们直接利用了CodeBERT的初始训练目标,即使用特定的掩码行输入进行程序修复。我们准备了模型输入,其中每个可能有问题的行都被替换为一个掩码行。然后,我们查询CodeBERT,将掩码行填充为替换标记,以生成有问题程序输入的候选补丁。这使我们能够直接进行零-shot学习(无需微调),因为我们使用与MLM中定义的相同任务 - 而不是预测随机掩码标记,我们通过只掩盖有问题代码片段来生成预测。请注意,为了改善补丁搜索空间,掩码行被设计为系统地重用有问题行的部分。此外,CodeBERT(和MLM)的双向性质还使我们能够自然地捕获有问题位置前后的上下文,以有效生成补丁。
本文的贡献包括:
AlphaRepair开创了填空式APR新维度,通过zero-shot学习直接利用预训练代码模型生成修复补丁,无需历史bug修复数据,提高了修复效率和准确性。该方法不受训练数据质量和数量限制,可适用于多种编程语言,避免了现有基于学习的APR技术的局限性。在广泛的实验中,AlphaRepair在Defects4J和QuixBugs数据集上表现优异,修复了多个错误并展示了多语言修复能力,为自动程序修复领域带来重要突破。2 技术介绍
在这一部分中,我们介绍了填空式自动程序修复(APR),这是学习型APR的一个新方向,直接从大量现有的代码片段中学习,以生成补丁。与所有先前的基于学习的APR技术不同,我们不把APR视为将有错误的代码片段转换为修复的代码片段的任务,而是直接学习给定其周围上下文的正确代码应该是什么样子。我们将问题视为一个填空任务,在这个任务中,我们用空白/掩码替换有错误的代码片段,并查询预训练模型来填充这些空白,得到正确的代码片段。这个问题设置不需要访问包含有错误和修复代码版本对的任何数据集,我们的方法可以直接利用现有的大型预训练模型来自动生成代码修复。
尽管我们的方法是通用的,但在这项工作中,我们重新运用最近的CodeBERT模型进行程序修复。CodeBERT的训练目标使用了掩码语言模型(MLM),在这个模型中,给定一个由标记组成的输入序列 X = {x1, x2, ...xn },将 X 中的一组随机标记替换为掩码标记,生成一个新的掩码序列 Xmasked。训练目标是输出在 Xmasked中已被掩码的原始标记,即恢复 X 给定Xmasked 。给定预测器 P 输出标记的概率,掩码语言模型(MLM)损失函数可以被表述为:

掩码语言模型(MLM)的训练目标使我们能够直接使用CodeBERT进行程序修复,其中我们不是随机掩码标记,而是掩码掉所有属于有错误的代码片段的标记。然后,我们在zero-shot学习设置下使用CodeBERT进行程序修复,从而恢复掩码有错误标记的正确标记。因此,AlphaRepair 不需要在错误修复数据集上进行任何额外的重新训练或微调阶段,因为MLM训练是CodeBERT 预训练任务的一部分。虽然我们的基本思想适用于不同级别的APR,但在这项工作中,我们专注于单行修补,遵循最先进的基于学习的APR工具,我们关注单行修补。图1提供了我们方法的概述:
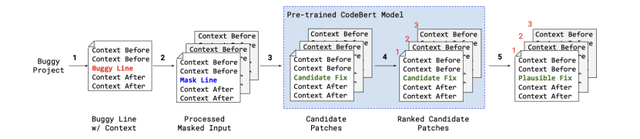
图 1:AlphaRepair概览
2.1 输入处理

图 2:输入示例
首先我们从有错误的项目中提取有错误的行和周围上下文。我们使用CodeBERT分词器,该分词器使用基于字节级别字节对编码(BBPE)构建 - 这是一种通过将不常见的长单词拆分为语料库中常见的子词来减小词汇量的技术。BBPE已经被用在各种模型中,并显示可以缓解词汇外问题。
图2提供了一个有错误程序的示例输入。我们首先定义我们的标记化结构,一个标记列表作为CodeBERT的输入。我们对之前和之后的上下文进行标记化,并在它们之间夹入掩码行(用于CodeBERT预测的占位符)。对于程序修复,有错误的行本身也很重要以生成补丁。但是,将其作为上下文的一部分并没有意义,因为我们的目标是生成用于替换它的代码。
为了捕获有错误的行的编码,我们利用了CodeBERT的双模态特性,它可以接受编程语言和自然语言(注释)。我们通过用块注释字符(/* 注释 */)包围原始有错误的行来将其转换为注释。回想一下描述基本MLM损失函数的方程式1,其中 Xmasked 是一个掩码序列。在CodeBERT中,Xmasked连接自然语言和代码标记,使得 Xmasked= Wmasked, Cmasked ,其中 Wmasked和 Cmasked 分别是自然语言和代码标记序列的掩码序列。原始的MLM损失函数现在是:
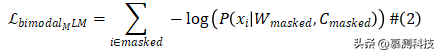
这样,CodeBERT学习函数表示的两种模态(自然语言和函数代码)。AlphaRepair利用这种额外的理解,将有错误的行转换为注释。注释有错误的行、之前的上下文、掩码行和之后的上下文一起被标记化作为CodeBERT的输入。为了最大化我们可以编码的上下文,我们从有错误的行开始,并增加上下文大小(远离有错误代码的行)直到达到最大的CodeBERT输入标记大小为512。
2.2 掩码生成
为了生成补丁,我们将有错误的行替换为一个掩码行。掩码行被定义为包含一个或多个掩码标记 - <mask> 的行。我们使用CodeBERT来用替换代码标记填充每个掩码标记,填充后的掩码行成为生成的补丁行。图3展示了我们用来生成掩码行的三种策略:完整、部分和模板掩码。

图 3:生成掩码行的不同策略
完整掩码。最简单的策略是用只包含掩码标记的行替换整个有错误的行。我们还生成添加掩码标记在有错误行之前/之后的掩码行。这些代表了在有错误位置之前/之后插入新行的错误修复。
部分掩码。另一种策略是通过重复使用有错误行的部分代码。我们首先将有错误的行分解为其各个标记,然后保留最后/第一个标记,并用掩码标记替换之前/之后的所有其他标记。然后我们重复这个过程,从原始有错误的行中附加更多标记以生成所有可能的部分掩码行版本。
模板掩码。我们实现了几种基于模板的掩码行生成策略,针对条件和方法调用语句,因为它们是两种最常见的bug模式之一。与前两种策略不同,模板掩码只能针对特定的有错误行生成。第一组模板旨在针对有错误的方法调用。方法替换将用掩码标记替换方法调用名称。这表示要求CodeBERT使用与以前相同的参数生成替换方法调用。我们还使用了几种基于参数的更改:用掩码标记替换所有输入、用掩码标记替换一个参数,以及添加额外的参数(可以添加多个参数)。
我们还为布尔表达式形式的条件语句设计了模板掩码行。我们生成替换整个布尔表达式或通过附加掩码标记添加额外的and/or表达式的掩码行。此外,我们还识别常见的运算符(<, >, >=, ==, &&, ||等)并直接用掩码标记替换它们在有错误行中。
这些基于模板的掩码行生成受到许多bug的常见修复和先前利用预设模板修复bug的APR工具的启发。这些简单生成的模板在提供更多起始代码方面类似于部分掩码。对于只需要修改有错误代码的一小部分的修复,CodeBERT只需使用模板掩码中的掩码行生成少量标记。通过包含更大部分的有错误代码,我们减少了CodeBERT需要考虑的搜索空间。
对于每个生成的掩码行,我们将生成的标记数从1逐渐增加,直到该行中的总标记数变为(L + 10),其中L是原始有错误行中的标记数。
2.3 补丁生成
为了生成一个替换原始错误代码的补丁,我们使用CodeBERT为我们输入中的每个掩码标记生成代码标记。为此,我们利用了CodeBERT中用于掩码替换的原始训练目标。CodeBERT通过预测在给定周围上下文的情况下,已被掩码标记替换的正确标记值来进行训练。对于每个掩码标记,CodeBERT输出其词汇表中每个标记替换掩码标记的概率。通常,在训练过程中,会将一小部分标记掩码化(<15%),模型将尝试预测实际被替换的标记。

图 4:补丁生成和重新排名示例
我们的任务类似于CodeBERT的原始训练目标,我们也对输入进行了预处理,使一小组标记被掩码化。然而,我们输入数据和掩码训练数据之间的一个关键区别是我们的掩码标记是分组在一起的。CodeBERT和BERT系列模型的一个显著特点是双向性质,其中每个标记表示不仅取决于之前的上下文,还取决于之后的上下文。为了为掩码标记生成替换标记,CodeBERT查看掩码位置之前和之后的标记。这对于训练目标很有效,因为掩码标记是分散的,每个标记都有足够的前后标记来提供上下文。然而,对于我们的输入数据,掩码标记是在一起的。为了促进分组掩码标记的标记生成,我们通过将掩码标记逐步替换为先前生成的标记来迭代地输出标记。图4a展示了这个过程是如何进行的。我们从初始输入的掩码行if (endIndex <0 || <mask><mask><mask>) {开始,并使用CodeBERT确定第一个掩码标记的前N个最有可能的替换标记。这里的N是波束宽度,是我们方法中的一个可调参数。在这个示例中,N为3,意味着我们取前3个最有可能的标记以及其条件概率。在下一个迭代中,我们再次查询CodeBERT,通过用前3个替换标记(1.startIndex, 2.endIndex, 3.emptyRange)替换第一个掩码标记,找到具有最高联合条件概率的前3个标记对(1.startIndex <, 2.startIndex ==, 3.endIndex >=)。我们将这个联合条件概率值称为临时联合分数。给定n作为掩码标记长度,T = {t1,...tp,MASKp+1,...MASKn}为到目前为止生成的标记的掩码行T,让C∗(T,t)为生成t的CodeBERT条件概率,当所有在t之后包括t在内的标记都被掩码化时,临时联合分数定义为:

我们在这里注意到,临时联合分数不代表生成的标记一旦完成生成(所有掩码标记都被替换)的实际概率。这是因为CodeBERT在确定替换标记的可能性时同时使用了之前和之后的上下文,概率值并不考虑未来将要生成的掩码标记。当计算掩码行T中标记序列({t1,...tp−1,tp,MASKp+1,...MASKn})的临时联合分数时,CodeBERT看到了tp之前的标记值({t1, ...tp−1}),但之后的所有标记都被掩码化({MASKp+1, ...MASKn})。也就是说,临时联合分数是条件于尚未确定值的掩码标记的,条件概率不考虑这些掩码标记的未来具体值。因此,我们将这个概率值仅作为一个临时代理,并在之后重新分配概率以获得更精确的补丁排序。在每个迭代中,我们使用临时联合分数仅保留生成的标记序列中的前3个最高分数。我们重复这个过程,直到我们完成为输入中的所有掩码标记生成标记。
通过按顺序生成标记,我们确保在生成任何掩码标记时,CodeBERT至少有一个侧面的直接上下文。这有助于生成更符合语法的候选补丁,因为CodeBERT可以使用之前的直接上下文来确定最佳的下一个标记应该是什么。这个过程类似于常用于代码或自然语言生成任务的波束搜索。一个区别是,传统代码生成可以准确计算序列的概率,作为生成标记的对数条件概率的平均值。对于我们的方法,简单的平均值只是概率的一个近似值,因为掩码行开头的标记的概率输出不包括未来生成的标记。为了解决这个问题,我们通过重新查询CodeBERT重新排名每个候选补丁,以获得准确的概率值。
2.4 补丁重新排名
重新排名过程再次利用了CodeBERT模型。关键思想是在完全生成补丁后为每个补丁提供准确的分数(即可能性),以便更有效地对补丁进行排名。我们从包含所有生成标记的完整补丁开始。然后,我们屏蔽掉其中一个标记并查询CodeBERT以获取该标记的条件概率。我们对所有其他先前的掩码标记位置应用相同的过程,并计算联合分数,这是各个标记概率的平均值。给定序列中生成的 n 个标记:T = {t1, t2, ...tn },当屏蔽掉序列 T 中的仅一个标记 t 时,C (T , t ) 表示 CodeBERT 在屏蔽掉仅标记 t 时的条件概率,联合分数定义如下:

现在可以将联合分数理解为生成序列的条件概率(即在给定之前和之后的上下文时,根据CodeBERT生成的补丁的可能性是多少?)。这适用于所有通过所有掩码生成策略(完整、部分和模板掩码)生成的补丁。我们将其除以 n,以考虑标记长度的差异,因为不同的掩码行具有不同数量的掩码标记。
2.5 补丁验证
对于我们生成的每个候选补丁,我们将相应的更改应用于有缺陷的文件。我们对每个补丁进行编译,并筛选出无法编译的补丁。然后,我们对每个已编译的补丁运行测试套件,以找到通过所有测试的可信补丁。
3 实验评估
3.1 实验设置
研究问题:
RQ1:AlphaRepair与最先进的自动程序修复工具相比如何?
RQ2:不同配置如何影响AlphaRepair的性能?
RQ3:AlphaRepair在额外项目和多种编程语言中的泛化能力如何?
评估数据集。我们首先使用Defects4J版本1.2来回答研究问题1和2。Defects4J 1.2包含了6个不同Java项目中的391个错误(删除了4个不推荐使用的错误)。为了回答研究问题3,我们使用了Defects4J 2.0,它在Defects4J 1.2的基础上增加了438个错误。由于AlphaRepair设计用于修复单行错误,我们仅在Defects4J 2.0中新错误中的82个单行错误上进行评估,这与先前的单行自动程序修复工具相似。我们还使用了QuixBugs,其中包含40个带有单行错误的小型经典算法,用于评估许多自动程序修复工具
对比方法。我们选择了6种最近发布的工具,这些工具是在Java或Python错误数据集上评估的:Recoder(Java),DeepDebug(Python),CURE(Java),CoCoNuT(Java和Python),DLFix(Java)和SequenceR(Java)。我们还与12种最先进的传统单块自动程序修复工具进行比较:TBar,PraPR,AVATAR,SimFix,FixMiner,CapGen,JAID,SketchFix,NOPOL,jGenProg,jMutRepair和jKali。
评估指标。为了评估我们的技术与最先进工具的比较,我们使用了标准指标,包括仅通过项目的整个测试套件的可信补丁以及在语法或语义上等价于开发者补丁的正确补丁。遵循自动程序修复的常规做法,通过手动检查每个可信补丁以确定语义等价性来确定正确补丁。
RQ1 与最先进技术比较
我们首先将AlphaRepair与首选的完美故障定位设置下的最先进基于学习和传统自动程序修复工具进行比较。我们还与没有完美故障定位的最先进工具进行比较。

结果 1:表1显示了AlphaRepair的性能以及其他使用完美故障定位的基准线的性能。AlphaRepair可以成功为74个错误生成正确的修复程序,这超过了所有先前的基准线,包括传统和基于学习的自动程序修复技术。
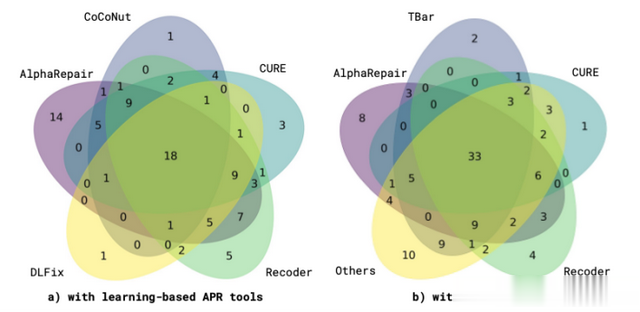
图 5:Defects4J 1.2的正确补丁Venn图
为了进一步展示AlphaRepair的有效性,我们评估了只有AlphaRepair能够修复的唯一错误数量。我们首先与基于学习的自动程序修复工具进行比较。图5a显示了AlphaRepair和其他基于学习的工具的唯一修复情况(我们排除了SequenceR,因为它没有唯一的错误修复)。我们观察到AlphaRepair能够修复最多数量的14个唯一错误。图5b显示了AlphaRepair、表现最佳的3个基准线以及所有其他自动程序修复工具的组合(图5b中的Others)的唯一修复情况。我们观察到AlphaRepair能够修复最多数量的8个唯一错误。这也表明AlphaRepair可以与其他技术结合使用,进一步增加可以生成的正确补丁数量。
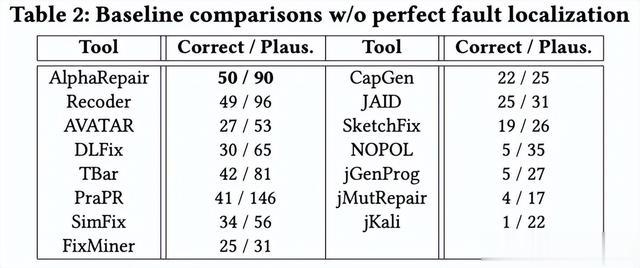
表2显示了在这种设置下AlphaRepair与其他技术的性能。AlphaRepair能够生成50个正确的补丁,超过了先前的最先进工具。此外,AlphaRepair能够正确修复7个唯一错误(在所有研究技术中最高),其他技术无法修复。在这个实验中,我们展示了即使每个可疑行生成的补丁数量减少,AlphaRepair仍然可以实现最先进的结果。
RQ2 消融研究
为了研究在AlphaRepair设计中添加不同组件的贡献,我们进行了消融研究。为了展示每种掩码生成策略如何提高修复的错误数量,我们从最基本的策略开始,逐步添加更复杂的掩码策略。
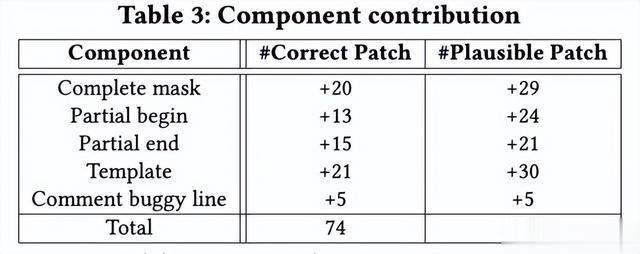
结果 2:表3包含了每一行代表一个组件,以及AlphaRepair可以生成的正确/合理补丁数量的增加结果。首先,我们只使用完整掩码,我们只能获得20个正确的补丁。随着我们开始使用更多的掩码生成策略,我们获得了生成的正确补丁数量的增加。性能提升最大的是使用模板掩码行,它额外增加了21个新的修复。与完整掩码相比,模板掩码只掩盖错误行的某些部分(参数、布尔表达式、函数调用)。这使得CodeBERT只需填充少量掩码标记,限制了搜索空间,使AlphaRepair能够快速找到正确的补丁。此外,当我们将错误行的注释版本的编码作为CodeBERT的输入时,我们还看到性能有所提升。错误行本身对于生成补丁很重要,因为它包含诸如使用的特定变量和行的类型等重要信息。这表明AlphaRepair能够利用错误行来帮助引导生成有效的修复。将AlphaRepair中的所有组件组合在一起,我们能够实现生成的最终正确补丁数量。

图 6:Defects4J 1.2的正确补丁Venn图
为了评估我们的补丁排名策略的有效性,我们比较了有和没有重新排名的正确补丁的顺序。图6显示了生成的所有正确补丁的补丁排名,有和没有重新排名(虚线代表每种策略的平均补丁排名)。我们观察到,平均而言,不使用重新排名策略时,正确的补丁排名为第612位。而使用重新排名时,正确的补丁平均排名为第418位(减少了31.7%)。此外,在重新排名之后,61个正确补丁中有61个排名更高。通过重新排名生成的补丁,我们确保联合得分是在没有任何掩码标记的情况下计算的,提供准确的可能性计算。这表明AlphaRepair中的补丁重新排名过程可以有效地对补丁进行排序,并优先考虑排名较高的补丁,以防只有生成的部分补丁可以验证。
RQ3 AlphaRepair的泛化能力
为了展示在额外项目和错误上的泛化能力,并确认AlphaRepair不仅仅是对Defects4J 1.2中的错误过拟合,我们在Defects4J 2.0数据集的82个单行错误上评估了AlphaRepair。另外,我们通过在QuixBugs数据集上评估AlphaRepair展示了其多语言修复能力,该数据集包含有缺陷程序的Java和Python版本。

结果 3:表4显示了与Defects4J 2.0上其他基线的结果进行比较。我们观察到AlphaRepair能够实现36个正确补丁的最高数量(比顶级基线高出3.3倍)。Defects4J 2.0包含了对于APR来说更难的一组项目,修复的种类也比Defects4J 1.2更多样化。我们观察到,虽然基于模板的工具如TBar能够为Defects4J 1.2生成大量正确补丁,但其在Defects4J 2.0上能够生成的正确补丁数量有限。基于学习的工具如Recoder也会因为转向更困难的评估数据集而受到影响,因为编辑是从训练数据集中学习的,这些数据可能在Defects4J 2.0中不存在。相比之下,AlphaRepair不使用特定错误数据集上的微调,这使其不太容易受到传统基于模板或基于学习的工具的泛化问题的影响。

表5显示了与最先进的Java和Python APR工具的结果。我们观察到AlphaRepair能够在Java和Python中都实现最高数量的正确补丁(分别为28和27)。我们还观察到,AlphaRepair是基线中唯一可以直接用于多语言修复的工具(CoCoNuT训练了2个单独的模型)。传统基于学习的工具需要访问仅在一种编程语言中的修复错误数据集,这限制了它们在多语言环境中的使用能力。与传统基于学习的APR工具不同,CodeBERT在Java、Python、Go、PHP、JavaScript和Ruby代码片段上进行联合训练,这使得AlphaRepair可以直接用于多语言修复任务,并且只需进行最小的修改。
转述:宗兆威
