Efficient Mutation Testing via Pre-Trained Language Models
Ahmed Khanfir , Renzo Degiovanni , Mike Papadakis and Yves Le Traon
SnT, University of Luxembourg, Luxembourg
引用
Khanfir A, Degiovanni R, Papadakis M, et al. Efficient mutation testing via pre-trained language models[J]. arXiv preprint arXiv:2301.03543, 2023.
论文:https://arxiv.org/pdf/2301.03543
摘要
突变测试是一种成熟的基于故障的测试技术,应该产生既“自然”又“强大”(有很高的机会揭示错误)的错误。为了实现这一点,本文使用预先训练的生成语言模型(即CodeBERT),生成类似于开发人员的代码,从而提供执行突变测试的机会。本文通过实现µBERT来实现这个想法。本文的研究结果表明,µBERT的故障揭示能力高于最先进的突变测试(PiTest),产生的测试比PiTest的故障检测潜力高出17%。此外,µBERT可以补充PiTest,能够检测到PiTest遗漏的47个错误,而PiTest可以发现µBERT遗漏的13个错误。
1 引言
突变测试旨在使用简单的语法转换来播种错误。这些转换,也称为突变操作符,通常是基于目标编程语言的语法构建的语法规则,即用另一个算术操作符替换算术操作符,如a + by a -。不幸的是,这样的技术产生突变(种子错误),其中许多是“不自然的”,也就是说,不符合开发人员的编码方式,因此被开发人员认为是不现实的。同时,基于语法的故障播种无法捕获它们所应用的代码片段的语义,从而导致大量琐碎或低效用错误。
为了解决上述问题,本文提出利用大码形成自然突变。因此,本文的目标是通过利用预训练语言模型的能力来捕获代码的底层分布及其编写,从而引入遵循程序员所遵循的隐含规则、规范和编码惯例的修改,正如在大型代码的预训练过程中学习到的那样。
本文引入了µBERT,这是一种突变测试方法,它使用预训练的语言模型(CodeBERT)通过屏蔽和替换token来生成突变,目的是形成自然突变。μ BERT遍历程序语句并修改它们的令牌。特别是,µBERT的操作如下:(1)一次选择并掩码一个令牌;(2)用掩码序列馈送CodeBERT,得到预测结果;(3)用预测代币替换掩码代币生成突变体;(4)丢弃不可编译的、重复的和等效的突变体(语法上等于原始代码的突变体)。
本文还研究了基于条件种子的突变对µBERT故障检测能力的影响。设计用于杀死两种µBERT突变体的测试套件:1)直接CodeBERT预测和2)条件播种与CodeBERT预测的组合引起,比设计用于杀死直接CodeBERT预测突变体的测试套件平均发现9%以上的bug。
总的来说,本文的主要贡献是:
本文引入了µBERT,这是第一个使用预训练语言模型的突变测试方法。它利用在大型代码语料库上进行预训练期间捕获的模型代码知识,以及捕获程序上下文的能力,以产生“自然的”突变。本文提出了新的加性突变,其操作方式是在目标代码的现有条件表达式中播种新的条件,然后用模型预测掩盖和替换它们的令牌。本文提供的经验证据表明,μ BERT突变体可以引导测试获得更高的故障检测能力,在有效性和成本效益方面优于SOA技术(即PiTest)。在本文的实证研究中,本文还验证了采用新的加性突变模式的优势,即提高了编写具有更高故障揭示能力的测试套件的有效性和成本效率。
2 方法技术
本文提出了µBERT,一种基于生成语言模型的突变测试方法,如图1所示。给定输入源代码,µBERT利用CodeBERT的代码知识及其捕获程序上下文的能力来产生“自然”突变,即类似于最终的开发人员错误。为此,µBERT分以下六个步骤进行:
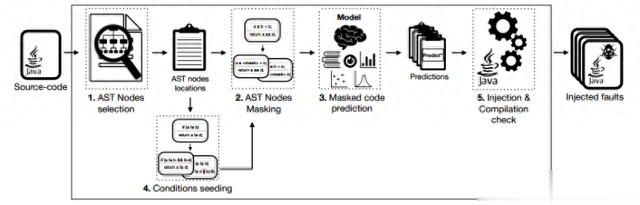
图1: µBERT工作流
1)首先,它提取要突变的相关位置(AST 2节点)
2)其次,它屏蔽已识别的节点令牌,为每个选定的令牌创建一个屏蔽版本。
3)然后,它调用CodeBERT来预测这些掩码令牌的替换。
4)除了步骤(3)中产生的突变,µBERT还实现了一些修改多个令牌的条件播种加性突变。准确地说,它修改控制流中的条件表达式(通常出现在if、do、while和return语句中),将原始条件扩展为一个新条件,并结合逻辑操作符&&或||。然后,通过执行相同的步骤(2)和(3)来改变新的条件表达式——屏蔽和用CodeBERT预测替换被屏蔽的令牌。
5)最后,该方法将重复的预测或与原始代码相似的预测或不编译的预测丢弃,并从目标代码的不同位置将剩余的预测作为突变体输出。更准确地说,它以随机顺序遍历语句,并在每次迭代中每行输出一个突变体,直到达到所需的突变体数量或输出所有突变体。
2.1 AST节点选择
µBERT解析输入源代码的AST,并选择更有可能携带程序规范实现的行,排除import语句和声明语句,例如声明类,方法,属性等的语句。通过这种方式,该方法将突变集中在程序的业务逻辑部分,并排除可能对程序行为影响较小的行。然后,它继续从这些语句中选择要改变的相关节点,即操作符、操作数、方法调用和变量等,并排除特定于语言的节点,如分隔符和流控制,即分号、括号、if、else等。表1总结了µBERT对目标AST节点的类型,以及相应的示例表达和诱导突变体。本文将这些称为由µBERT提供的常规突变,在评估中用µBERTconv表示。
表1:µBERT常规突变的示例

2.2 Token屏蔽
在这一步中,本文一个接一个地屏蔽所选节点,为每个感兴趣的节点从原始源代码生成一个屏蔽版本。这意味着每个屏蔽版本都包含一个缺失节点的原始代码,由占位符<mask>代替。通过这种方式,µBERT可以在同一个程序位置生成多个突变体。例如,对于像res = a + b这样的赋值表达式,µBERT将从以下掩码序列中创建(可能有25个)突变:
<mask> = a + bres <mask>= a + bes = <mask> + bres = a <mask> bres = a + <mask>2.3 CodeBERT-MLM预测
µBERT调用CodeBERT来预测被屏蔽节点的替换。为此,它将每个屏蔽版本标记为一个标记向量,然后将其裁剪为一个子集,该子集符合模型允许的最大大小(512),并将屏蔽标记与周围的代码标记一起计数。接下来,本文的方法将这些向量提供给CodeBERT MLM,以预测掩码令牌最可能的替换。本文的直觉是,伴随掩码占位符的代码部分越大,CodeBERT捕获代码上下文的能力就越好,因此,它的预测就越有意义。此步骤以每个掩码令牌生成五个预测结束。
2.4 条件播种
µBERT通过结合条件播种和CodeBERT预测能力来生成二阶突变体。为此,本文的方法修改了控制流中的条件和返回语句,包括if、do、while和返回条件表达式。对于这些语句中的每一个,它首先用一个新条件扩展原始条件,用逻辑操作符&&或jj分隔,顺序有两种(原始条件优先或相反),有或没有否定(!)。
接下来,将所有替代条件一个接一个地放在原始代码中,形成多个条件种子代码版本,本文将其作为输入传递给步骤(2),其中它们的令牌被屏蔽,然后(3)将每个条件种子代码版本传递给CodeBERT,以预测其对应的被屏蔽令牌的最佳替代品。
2.5 突变体筛选
在这一步中,本文的方法首先抛弃准确和重复的预测;冗余的预测和与原始代码完全相同的预测。然后,它遍历语句并在每次迭代中逐行选择一个可编译的预测,同时丢弃不可编译的预测。一旦选择了所有一阶突变体(由单个令牌替换发出),本文的方法继续以相同的迭代方式选择二阶突变体(由条件播种和一个令牌替换的组合发出)。µBERT继续迭代,直到达到所需的突变体数量或输出所有突变体。
3 实验与结果
3.1 数据集和基准
为了评估µBERT的故障检测,本文使用了软件工程研究领域中一个流行的数据集——Defects4J v2.0.0中的真实错误。在这个基准测试中,每个主题bug都提供了源代码的一个有bug的版本及其对应的固定版本,并配备了一个测试套件,该测试套件通过了固定版本,而在有bug的版本上至少有一个测试失败。数据集包括超过800个错误,本文从中排除了那些呈现问题的错误。
在报告时,版本id错误,未编译或存在执行问题,或对固定版本进行了失败的测试。接下来,本文从剩余bug的固定版本中对受bug影响的相应类运行µBERT和PiTest,并排除那些没有工具生成任何突变的类,最终µBERT覆盖了689个bug, PitTest覆盖了457个bug。由于本文感兴趣的是比较方法而不是工具的实现,并且为了排除与环境相关的最终威胁(即每种技术支持的java和联合版本等)或数据集的局限性和不足,本文在数据集上建立了每个比较研究,只计算所有考虑的方法所涵盖的错误。
3.2 实验过程
为了评估基于条件种子的突变的故障揭示方面的互补和附加价值,本文在有和没有这些额外突变的情况下运行本文的方法-本文分别命名为µBERT和µBERTconv-,因此,在本文的数据集程序的固定版本上生成所有可能的突变。接下来,本文比较了生成的测试套件的平均有效性,以杀死每个集的突变体µBERT和µBERTconv诱导。
一旦所提出的基于条件种子的突变的附加价值得到验证,本文将其性能与soa突变测试进行比较。本文使用PiTest,一个稳定和成熟的Java突变测试工具,因为它比其他工具更有效地发现错误,并且它是研究人员和从业者最常用的工具之一。该工具提出了不同的配置,通过排除或包括突变,使产生的突变及其一般成本适应目标用户。
为了比较不同的方法,本文评估了它们在实现突变测试的主要目的之一方面的有效性和成本效率,即指导测试向更高的故障检测能力发展。出于这个原因,本文模拟了一个突变测试用例场景,其中开发人员/测试人员选择突变并编写测试来杀死它们。
本文在Defects4J提供的固定版本和测试套件上运行每种方法,然后收集突变项及其测试执行结果;是否终止突变(中断测试套件的至少一个测试),如果是,通过哪些测试。接下来,本文假设未被杀死的突变体是等价的或不相关的,这解释了为什么开发人员没有编写测试来杀死它们。然后,本文模拟开发人员测试固定版本的场景,处于以下状态:1)它没有任何测试;2)因此所有突变体都没有终止测试;3)开发人员不知道哪些突变体是等效的或不等效的。
本文根据分析的突变来表示测试成本,因此,本文认为找到一个bug所需的工作量是分析的突变的数量,直到编写第一个bug揭示测试。考虑到产生的突变体的数量不同,为了在方法之间建立一个共同的比较基础,本文运行模拟直到达到相同的最大努力(要分析的突变体的最大数量),本文将其设置为通过一种比较方法杀死所有突变体所需的最小成本。在本文的评估研究中,本文对所有比较方法使用相同的突变选择策略,以随机顺序迭代,每次迭代每行选择1个任意突变。最后,本文将在所有目标错误上计算的这些平均值汇总起来,并将它们标准化为通过花费的努力实现的故障检测的全局百分比。
最后,本文从结果中选择示例突变,这些突变使µBERT能够专门发现错误(没有被任何一个est版本发现)。然后通过分析突变体与固定版本的行为差异以及与bug版本的相似度来讨论µBERT突变的附加价值。
本文实现了所描述的µBERT方法:使用Spoon和Jdt库来解析和提取与AST节点相关的业务逻辑,并应用条件播种突变子。为了预测掩码令牌,本文使用CodeBERT掩码语言建模(MLM)功能。
RQ1 µBERT 累加突变
本文比较了为杀死由µBERT产生的突变体而编写的测试套件的故障检测效率,这些突变体分别被标记为µBERT和µBERTconv。图2描述了通过添加性突变扩展μ BERT突变时的故障检测改进。事实上,与µBERTconv相比,µBERT的故障检测平均提高了9%以上,平均达到84.64%。本文还可以看到,除了异常值之外,大多数bug在100%的时间内被发现。此外,当单独检查错误时,本文发现µBERT比µBERTconv(故障检测> 0%)多发现20个错误,当考虑故障检测百分比大于90%时发现的错误时,多发现70个错误。这证实了加性模式诱导了相关的突变,确保总是或在大多数情况下检测到某些错误,以及代表更好的新类型的故障,否则无法检测到。
为了检验加性模式带来的故障检测优势的显著性,本文对图2a的数据进行了统计检验(Wilcoxon配对检验),验证了“µBERT产生的故障检测大于µBERTconv产生的故障检测”的假设。得到的p值非常小,为5.92e-21,表明差异显著,表明这种故障检测改进偶然发生的可能性很低。差异大小也证实了同样的优势,A^12值为0.5827,表明µBERT在大多数情况下诱导出具有更高故障检测能力的测试套件。
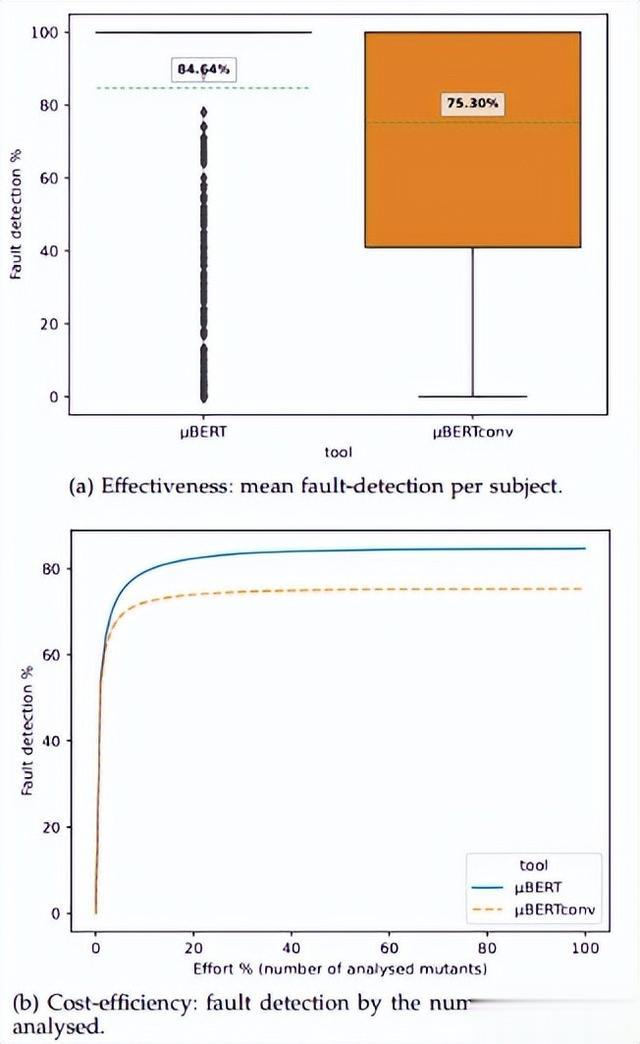
图2: 使用附加模式时故障检测性能的改进
接下来,本文比较了µBERT和µBERTconv在分析相同数量的突变体时的故障检测性能,并在图3中说明了它们的平均故障在分析突变体方面的检测有效性和成本效率。图3a的箱形图显示,即使在花费与µBERTconv相同的努力时,µBERT保持了相似的优势,平均高出6.05%的故障检测,达到了81.35%的最大值。从子图3b的线形图中,本文可以看到,两种方法在(≤≈40%)的最大成本下实现了相当的故障检测(≈70%)。在成本较高的情况下,µBERT的曲线增长缓慢,直到在≈60%的努力时达到平台,而µBERT的曲线即使在达到固定最大努力(≈100%)时,也会继续向更高的故障检测率增长。

图3: µBERT和µBERTconv之间的故障检测比较
为了验证这些发现,本文对图3a的数据重新进行了相同的统计测试,发现µBERT的性能明显优于µBERTconv,p值为1.15e-19,可以忽略,A^ 12值为0.5711。
RQ2 与PiTest的故障检测比较
为了回答这个研究问题,本文将数据集减少到µBERT和PitTest方法的3个考虑版本所涵盖的错误:“Pit-default”包含PiTest的默认突变算子,“Pit-all”包含所有PiTest算子,包括默认算子和“Pit-rv-all”包含实验算子除了“Pitall”之外。然后,本文根据编写的用于杀死其生成的突变的测试套件的故障检测能力,比较所考虑的方法的有效性和成本效率。为了有一个公平的比较基础,本文比较了在分析突变体时相同努力下的方法,这等于杀死其中一种方法的所有突变体所需的最小平均努力(在大多数情况下是Pit-default)。
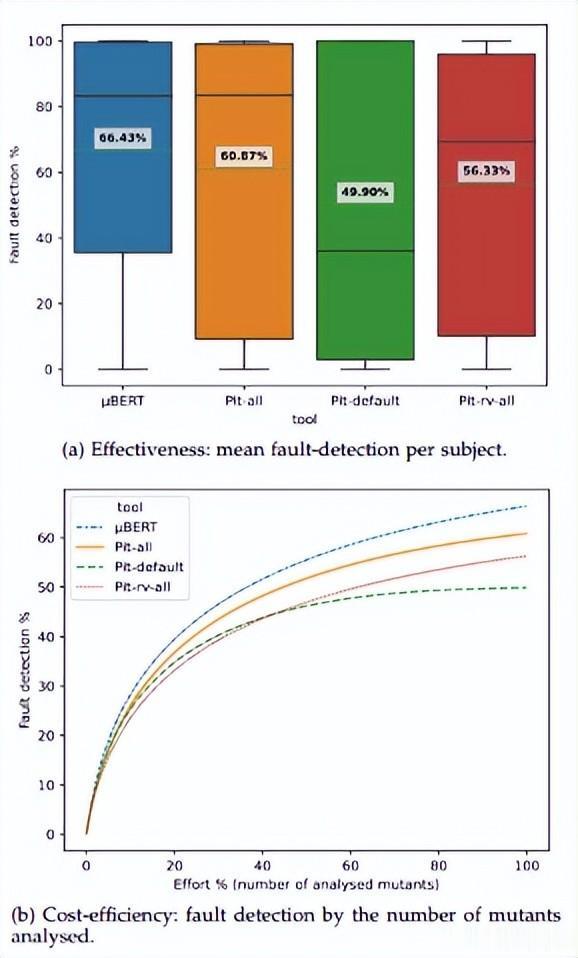
图4: µBERT和PiTest之间的故障检测比较
图4b显示,在很小的努力(≤≈5%)下,所有方法都产生了相当的故障检测分数(≈10%)。然而,当花费更多的精力时,差异变得更加明显,µBERT优于所有版本的PiTest;比Pit-default平均高16.53%,比Pit-rvall平均高10.10%,比Pit-all平均高5.56%(见图4a)。
本文还从图4b中注意到,Pit-default在大约60%的工作量下达到了平台期,而其他工具则在不断增加,这表明它们能够以更高的成本实现更高的故障检测能力。当本文将图4的子图(a)和(b)与图2进行比较时,这一点非常明显,其中µBERT的平均故障检测率远低于它在RQ1中达到的水平——大约66%而不是84%。这是Pit默认比其他方法产生更少突变的直接结果,在大多数情况下,这极大地限制了突变活动的最大努力,从而限制了故障检测比率。事实上,如图5所示,当花费更多的精力时,所有方法的故障检测百分比都更高,Pit-all的平均达到≈65%,Pit-rv-all的平均达到≈66%,µBERT的平均达到≈83%。与RQ1相比,µBERT实现的平均故障检测减少了1.72% (RQ2为82.92%,而RQ1为84.64%),本文解释了每个RQ所考虑的数据集的差异。

图5: µBERT和PiTest相对于编写测试套件错误检测的比较
接下来,本文将方向转向了一组特定的错误,当花费相同的努力时,每种方法都可以或不能揭示这些错误。因此,本文根据图4a的模拟结果,用它的揭示工具映射每个bug,并在图6中说明它们对应的维恩图。

图6:相同的工作量时为杀死µBERT和PiTest生成突变而编写的测试套件发现错误数量
从子图6a中的不一致的集合中,本文注意到使用µBERT比考虑的SOA基线有明显的优势,因为在花费相同的精力时,除了只发现47个错误之外,它还发现了他们发现的大多数错误。更准确地说,µBERT比Pit-all、Pit-default和Pit-rv-all分别多发现52、77和52个bug,而它们分别发现了µBERT遗漏的13、10和13个bug。
RQ3 µBERT突变体的定性分析
本文研究了µBERT生成的突变,它诱导的测试套件能够发现其他方法无法检测到的错误,即通过考虑的SOA方法(见图6)。这意味着突变会破坏与目标真实错误版本相似的测试。
作为一个简单的bug示例(只需要一次修改就可以修复它),本文考虑了来自Defects4J的Lang-49,本文研究了由µBERT生成的突变,并帮助生成了揭示它的测试。这个bug会影响来自类org.apache.commons.lang.math.Fraction的方法reduce()的结果,如果可能的话,它会返回一个新的缩减后的分数实例,否则会返回相同的实例。该错误是由于没有实现特定的极端情况而引起的,这种情况包括在分子为0的分数实例上调用该方法。在表2中,本文举例说明了由µBERT生成的有助于揭示此错误的示例突变。每个突变都用µBERT表示固定版本和突变版本之间的差异。
表2:由µBERT生成的突变体示例

µBERT可以生成可以通过应用传统的基于模式的突变来诱导的突变,即突变体1用另一个(>)替换关系操作符(==),突变体2用另一个(1)替换整数操作数(0)。
为了进一步研究模型捕获的代码上下文对生成的突变体的影响,本文在数据集中的5个主题上重新运行了µBERT,周围标记的最大数量等于10(而不是512)。然后,在相同的位置,本文将人工诱导的突变体与默认设置生成的突变体进行比较。从本文的结果中,可编译预测的数量明显减少,这表明当模型缺乏关于代码上下文的信息时,它的总体性能会下降。
在表3中,本文展示了一些示例突变,它们帮助找到了所研究的每个主题(打破了与原始错误相同的测试),当周围令牌的最大数量限制为10时,µBERT无法生成这些突变。
表3:µBERT生成的一个突变的例子

转述:朱云峰