Large Language Models for Fuzzing Parsers
Joshua Ackerman1, George Cybenko1
1Dartmouth College
引用
Joshua Ackerman and George Cybenko. 2023. Large Language Models for Fuzzing Parsers (Registered Report). In Proceedings of the 2nd InternationalFuzzing Workshop (FUZZING ’23)
论文:https://dl.acm.org/doi/10.1145/3605157.3605173
摘要
格式规范的不明确性是软件安全漏洞的一大成因。本文提出了一种基于自然语言处理的方法,该方法巧妙地利用了格式规范的不确定性来生成用于模糊测试的格式实例。作者使用大语言模型递归地分析自然语言格式规范,生成规范的实例,并把这些实例作为变异模糊测试的高效种子输入。初步实验表明,作者的方法不仅超越了基本的变异模糊测试,而且能够针对新出现的自定义格式创造出测试用例。
1 引言
输入解析的精确性对于保障软件安全具有重要作用。众多程序的准确性依赖于一个基本假定,即输入数据必须符合特定的标准格式。当这一假定被违背时,程序可能会表现出意料之外的行为,从而危害到程序的安全性。解析器(Parser)中的缺陷相当普遍,并且经常被诸如Heartbleed、Psychic Paper以及FORCEDENTRY等著名安全漏洞利用。
尽管输入解析对于确保软件安全具有重要作用,但开发一个完全正确的解析器却是一项艰巨的挑战。这种挑战源自于格式规范本身就存在着固有的不明确性。这些规范往往采用自然语言进行描述,这很容易导致规范中出现歧义。在消除这些规范歧义的过程中,开发者难免会受到自身认知偏见的左右。已有研究显示,开发者因认知偏见而更倾向于编写存在安全风险的代码。开发者倾向于采用不精确的心理启发式(Mental Heuristics)方法,并容易受到认知偏见的干扰,这可能会限制他们全面地理解和预估不同决策(如对规范中某一组成部分的特定消歧义)可能带来的影响。因此,开发者可能会轻易地做出不准确的假设,进而导致有缺陷的解析器实现,无法妥善处理所有潜在输入的情况。
鉴于之前提到的规范中的不明确性与潜在错误之间的固有联系,作者提出了一种新的方法,该方法利用自然语言格式的规范对解析器进行模糊测试。正如多项先前研究所讨论的,大型语言模型(Large Language Models, LLMs)存在偏见和不准确的问题。它们如同开发者一样,可能会编写不安全的代码,并且在处理模糊性任务时可能无法有效进行推理。作者推测,这些缺陷将导致对格式规范的错误解读,当这些解读与传统模糊测试算法结合时,将能够在解析器覆盖率上超越其他类似的黑盒模糊测试器。
作者的方法通过结合使用大语言模型与嵌入模型(Embedding Model)递归地审视自然语言格式的规范,进而使语言模型能够生成与规范在质量上相匹配的实例。由于多数格式规范过大,无法容纳于大语言模型的上下文窗口内,作者利用辅助嵌入模型检索文件规范的相关部分,以便大语言模型能够对规范中的特定构造进行推理。在本文的基本方法中,作者向大语言模型提出如下问题:“What is the structure of a well-formed object?”和“Generate an example of an object.”。作者向大语言模型提出这些问题,并递归地询问有关其回答的问题,直至达到预定的深度,此时模型必须生成所请求对象的示例。这一生成过程会重复多次,以获得每个对象的多个不同示例,然后由大语言模型递归地组合这些示例,以期望生成格式良好的实例。作者还会进一步查询大语言模型,对之前生成的实例进行变异操作,从而引发格式规范中提到的错误。
在这份初步报告中,作者展示了基于大语言模型的方法能够生成高效的种子输入,这些种子在与变异模糊器结合使用时,对于简单目标的表现超越了使用真实世界示例的传统变异模糊器。文章最后,作者讨论了第二阶段进行更严格评估和设定更优基准的计划。
2 本文方法
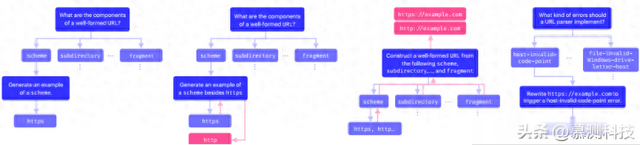
图1:本文的提示方法:四个步骤
作者假定有一个自然语言格式的规范D,它详细描述了目标解析器 P 所需实现的格式。同时,作者还使用一个自然语言嵌入模型 Embed(·) 和一个具有 M大小上下文窗口的大语言模型 LLM(·)。作者的方法包含三个主要步骤:预处理、种子生成和模糊测试。在预处理阶段,作者将规范 D 划分为若干片段 {D1, D2, …, Dn},确保每个片段的长度不超过 M,然后通过 Embed(·) 将每个片段转换为嵌入向量 Ei = Embed(Di),最终形成一个嵌入对集合 F := {(E1, D1), (E2, D2), …, (En, Dn)}。
为了生成种子,作者采用了创新性的递归提示方法,该方法包括四个阶段:(i) 理解(understand);(ii) 扩展(expand);(iii) 形成(form);(iv) 变形(deform)。在每个阶段,作者都会从格式规范中添加 K个相关信息片段以增强提示。在理解阶段,作者通过向语言模型提出关于文件结构的问题来构建一个解析树草图。这个过程从提出一个形式为“What is the structure of a well-formed [format-name]?”的问题 q0 开始。然后,作者解析模型的回答以提取其答案的不同组成部分,这些组成部分理想情况下能够代表了问题中方括号内容的高层次部分。接着,这个过程会递归地进行,直到达到预先指定的递归最大深度 dmax。在这个点上,模型被要求“Generate an example of [object].””。理想情况下,[object] 将是一个终止符号(terminal symbol),例如,不由其他对象组成,这意味着语言模型能够创建它的一个特定实例。在扩展阶段,特定的实例被反馈到提示中,并让语言模型生成这些终止符号的新实例 ℓ 次,或者如果没有新的实例,则返回 None。在形成阶段,作者回溯解析树草图,并让语言模型组合生成的终止符号,产生一个良好结构化的实例。对于每 ℓ 个不同的终止符号,重复这个过程,得到 ℓ’ ≤ ℓ 个格式不同实例。在变形阶段,语言模型被要求了解 D 指定的 P 应该实现的错误。如果规范提到了这样的错误,大语言模型将被要求变异每个 ℓ’ 实例以触发这个错误。
接下来通过相关公式更加正式地介绍下作者的方法。作者方法中的一个基本操作是格式规范增强查询或增强查询。对于一个问题 q = Q(·),一个增强查询包括计算 q 的嵌入 Eq,并通过余弦相似度检索 F 中与 k 个最接近嵌入相关的文本块。具体来说,作者找到集合 {T ∗ i : i= 1, …, k},其中

之后作者贪婪地将每个Ti 添加到提示 p 中,确保它不超过 M个token。大语言模型的最终提示,LLM(·),由 p := T1 ⊕ · · ·Tk′ ⊕ q 给出,其中⊕表示字符串连接。作者将对大语言模型的一个增强查询表示为 LLM∗ (·),一个常规查询表示为 LLM(·)。
在理解步骤中,作者定义了一个问题模板函数 Q(·),该函数接受一个字符串 S并返回一个类似于“What is the structure of a well-formed s?”的问题。此外,作者定义了一个生成模板函数 G(·),该函数接受一个字符串 s 和一个列表 L 并返回一个类似于“Generate an example of s ∉ L”的命令。理解步骤开始时,作者使用模板 Q([format-name]) 向模型提出一个增强查询。模型返回一个响应 r0,作者将其解析为多个部分 ,并基于这些部分生成新的问题。这个过程会递归地进行 dmax 次,直到达到预设的递归深度。此时,大语言模型会接收增强查询以生成示例,并产生具体的示例。最终结果是一个树 T,它代表了对示例的解析。在本文的实现中,作者维护这些响应作为一个多叉树,其中每个节点包含一个描述性标题和一组可能的示例。
在扩展步骤中,作者针对每个生成一系列不同的示例。

作者通过维护一个生成的响应列表,将它们反馈给大语言模型,并通过一系列 ℓ ′ ≤ ℓ 的增强生成查询来提示大语言模型生成不同的示例。接下来,对于形成步骤,作者定义了一个组合模板函数C(·),该函数接受一个具有标题 的父节点和一个子节点集合,并输出一个形式为“Generate a well-formed instance of given a , o1,…, and a , on”的字符串。作者回溯树,对大语言模型使用增强提示来组合每个父节点的子节点,最终得到一组(理想上)良好的结构实例 S = {s1, …, sℓ ′ }。最后,在变形步骤中,作者向模型提出一个一般性问题,其形式为“What errors should a [format-name] parser” implement?”。然后作者遍历响应 r = e (0) e (1) …e (m) 中的错误,并发送增强查询到大语言模型重写 S 中的每个字符串以触发每个错误。最终的种子集合是这个变异集合 S ′和 S 的并集。
3 初步评估结果
作者的初步评估围绕以下研究问题展开:
RQ1:相较于其他模糊测试方法,作者的方法是否能获得更高的程序覆盖率?RQ2:作者的方法在处理新格式时表现如何?RQ3:作者的方法是否能在程序中引发特定的错误?RQ4:作者的方法能否从文件规范中生成多样且结构良好的实例?RQ5:作者的方法对所选大语言模型及其参数选择的关联如何?在作者的第一阶段评估中,作者展示了RQ1和RQ2在简单任务上的初步结果,以证明本方法的有效性。在初步实验中,作者旨在验证两个关键点:(i)作者的方法能够生成语义上相关的输出;(ii)作者的方法不仅仅依赖于GPT-4的训练数据中的知识。这些是作者方法成功的关键要素,无论基准的相对简单性如何。因此,作者的第二阶段评估将集中在提高目标的真实性和采用最先进的模糊测试技术上。RQ3、RQ4和RQ5与作者的方法作为模糊测试工具的性能关系不大,而是围绕使用大语言模型可能带来的独特机会或挑战。因此,作者将这些问题的全面评估推迟到后续阶段。

图2:三种模糊测试工具的实验表现
针对RQ1,作者进行了一项简单的实验,对一些受限制Python URL解析器进行了模糊测试。作者使用了OpenAI的GPT-4作为大语言模型,temperature设置为0.1,同时选取OpenAI的text-embeddingada-002作为嵌入模型。作者将URL文件规范分割为子部分,并在贪婪的k-NN提示增强策略中使用了k = 4。最大递归深度dmax设置为1。最后,作者将本方法生成的示例作为种子输入到变异模糊器中。然后,作者将本方法与随机模糊测试工具和以良好结构化的URL为种子的变异模糊测试工具在分支覆盖率和覆盖率上进行了比较。这个实验在5次试验中的平均结果可以在图2中看到。在URLS上,作者的方法在覆盖率方面优于两种模糊测试工具,并且在分支覆盖率方面略优于变异模糊测试工具。此外,作者的方法比变异模糊测试工具和随机模糊测试工具更快地达到了更高的覆盖率。

表1:用于评估RQ2的语法描述
由于GPT-4是在大量网络数据上训练的,任何真实且广泛部署的格式规范都可能出现在其训练数据中。因此,为了测试RQ2,作者手动编写了一些合成“格式规范”,即由符号和自然语言混合描述的形式语言。目标是展示GPT-4能够独立地从描述中合成满足形式约束的示例。为了测试GPT-4的合成能力,作者向它提出一个描述形式语法的简短段落,并请求它生成100个示例。然后,作者检查这些示例的有效性,并报告准确度。每个文件格式、其形式语法以及GPT-4从它合成示例的准确度可以在表1中看到。前七种语言是Tomita语法的修改版本,这些语法通常作为正规语言归纳的基准。不寻常的匹配括号语言是对著名的Dyck语言的一个修改版本,其中修改之处在于匹配的括号在感知意义上并不“匹配”,例如‘[’可以与‘}’或‘>’匹配。最后,带有长度字段的元音是一个自然语言约束与常用结构配对的明显例子。除了Tomita-6语法外,GPT4在示例合成方面表现良好,并且大多数时间都能生成正确的字符串。尽管从语法学习或理解的角度看,60%到75%的不完美分数似乎较弱,但值得注意的是,对于模糊测试来说,这样的错误实际上可能是有益的。例如,GPT-4为带有长度字段的元音语法生成的错误字符串中约有11%,其形式为w = s⊕|s|+1,|s|+1<=9。换句话说,在这些字符串上,GPT-4将长度字段视为增加字符串长度的因素,结果错误地多计数了一个(因为|s| + 1 ≤ 9)。这可以被视为提示中模糊性的直接后果,或者简单地看作是一个溢出错误。无论如何,这样的错误在模糊测试中很可能是有用的,或者至少不会有害。
4 第二阶段展望
在第二阶段,作者计划通过扩展基准(benchmark)来扩展这项工作。首先,作者打算进行消融实验(ablation study),确定作者方法中每个组件的影响。例如,作者将评估本文的提示方法中“形成”步骤(RQ4)的性能,通过使用antlr生成一系列广泛的解析器,如http、mailto、fol、csv、icalendar、xml等,以确定生成的字符串中有多少是结构良好的。类似地,作者将研究“变形”步骤(RQ3)在诱导解析器中特定错误方面的有效性。最后,作者计划研究大语言模型的随机性对本文方法的影响(RQ5),通过研究其采样温度如何影响其在创建结构良好和结构不良的种子方面的性能。
另外,作者计划在第二阶段通过研究本方法是否能在真实代码中发现错误来扩展模糊目标的广度和真实性。为此,作者将利用Magma这样一个开源的模糊测试基准,该基准包含七个目标,这些目标由真实程序组成,这些程序在最新版本中已经手动引入了先前记录的错误。Magma工具记录了有用的基准测试信息,例如发现的错误数量以及达到和触发错误的时间。随着目标复杂性的增加,作者将需要将模糊化活动的长度远远超出当前的限制,并且在作者的方法和基准中使用更先进的开源变异模糊测试工具,例如AFL、FairFuzz、Hongfuzz或LibFuzzer。
转述:杨鼎
