
引用
Liu, Z., Chen, C., Wang, J., Che, X., Huang, Y., Hu, J., & Wang, Q. (2023, May). Fill in the blank: Context-aware automated text input generation for mobile gui testing. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) (pp. 1355-1367). IEEE.
论文地址:https://ieeexplore.ieee.org/document/10172490
摘要
自动化GUI测试被广泛用于确保移动应用程序的质量。然而,许多GUI需要适当的文本输入才能进入下一页,这仍然是测试覆盖率的一个突出障碍。考虑到有效输入的多样性和语义需求(如航班出发、电影名称),文本输入的自动化是一个挑战。受预训练的LLM在文本生成方面取得突出进展的启发,我们提出了一种利用LLM,基于GUI上下文智能生成语义输入文本的QTypist方法。为了提高LLM在移动测试场景中的性能,我们开发了一种基于prompt的数据构建和调优方法,该方法可以自动提取prompt和answer进行模型调优。我们在Google Play的106个应用上对QTypist进行了测试,结果显示QTypist的通过率为87%,比最好的baseline高出93%。
我们还将QTypist与自动化GUI测试工具集成在一起,与原始工具相比,它多覆盖了42%以上的应用activity和52%以上的页面,并帮助多发现了122%以上的bug。
引言
由于手机的便携性和方便性,移动应用程序现在已经成为我们日常生活中访问世界不可或缺的工具。然而,保证应用质量是很有挑战性的,特别是考虑到移动应用与复杂的环境(例如,用户、设备和其他应用)交互。由于GUI提供了软件应用程序和终端用户交互的桥梁,因此GUI测试被广泛用于测试应用程序是否正常运行。尽管在实践中经常使用手动GUI测试,但自动化GUI测试正变得越来越流行,以节省人力并扩展到不同设备上的不同应用程序。
目前有很多自动化的移动GUI测试方法,包括基于模型的、基于概率的和基于深度学习的等,通过对当前页面代码结构的分析,通过执行滚动、点击等不同动作来动态探索移动应用,验证UI功能。然而,它们大多侧重于探索算法的改进,而很少涉及文本输入生成等与应用程序的复杂交互。根据我们在Section II的观察,大多数应用程序都有一些页面需要特定的文本输入才能转到下一页。如图1所示,如果没有正确的航班搜索信息,搜索显示、航班信息、旅游新闻、航空公司信息、座位图等连续页面将无法访问。这种较低的Activity覆盖率将对自动化GUI测试工具的测试充分性产生负面影响。

图1:安卓app中文本输入的例子
文本输入生成对于自动化GUI测试来说是一项具有挑战性的任务,即使对人类来说也是如此。首先,它需要不同类型的特定输入值,例如用于识别设置的权重,地图应用程序的街道地址,健康应用程序的血压,媒体应用程序的电影名称,编码应用程序的源代码(更多细节见Section II-A2)。其次,同一UI页面内的一些文本输入可能相互关联,例如航班搜索中出发和到达的位置不同,以及产品搜索过滤器中最小价格应该小于最大价格。如果没有有效的输入,自动化测试工具就无法进入下一个UI页面,从而导致测试充分性低,并遗漏潜在的错误。
目前大多数方法通过分析源代码并提取约束关系,要么生成如“hello world”等带有固定/随机字符串或单词的文本输入,要么利用有限的启发式规则进行生成。对于生成带有语义的输入,Liu等提出了一种结合Word2Vec的基于RNN的方法。但它需要大量手工标注的数据,无法推广到不同的应用,也没有考虑到上面提到的上下文信息。
新兴的LLM在超大规模语料库上训练,有可能理解输入prompt并产生合理的输出。例如,OpenAI的GPT-3在数十亿个token上训练了1750亿个参数,可以智能地生成文章、回答问题、编写源代码。受LLM强大功能的启发,我们将LLM作为知识库,将文本输入生成问题制定为封闭式填空答题任务。一旦通过了需要文本输入的UI页面,就可以使用更自动化的测试技术来检测bug。
受LLM在新闻生成、电子邮件回复、摘要提取等方面取得突出进展的启发,我们提出了一种方法QTypist,通过预训练的LLM对文本输入信息建模,自动生成输入文本。给定一个带有文本输入的GUI页面及其相应的View层次文件,我们首先提取文本输入的上下文信息,并设计语言模式来生成输入到LLM中的prompt。为了提高LLM在移动输入场景下的性能,我们开发了一种基于prompt的数据构建和调优方法,该方法可以自动构建模型调优的prompt和answer。
为了评估QTypist的有效性,我们在Google Play中对106个流行的Android应用程序中的168个文本输入框(即EditText)进行了实验。与11种常用和最先进的基准相比,QTypist可以实现93%以上的通过率提升,达到87%的通过率。由于QTypist还可以生成具有实际意义的文本,我们进行了用户研究,以检验其多样性和重要性,结果表明,QTypist的文本生成性能平均得分为4.3分(满分5分)。除了QTypist的准确性外,我们还通过将QTypist与3种常用的、最先进的自动化GUI测试工具集成来评估QTypist的有用性。结果显示,集成QTypist的Ape、DroidBot和Monkey的Activity覆盖范围分别增加42%、33%和28%,UI页面覆盖量分别增加52%、41%和30%。与单独使用Ape相比,带有QTypist的Ape检测到的bug多了122%,这要归功于自动输入生成覆盖了更多的UI页面。我们希望我们的结果可以让社区认识到文本输入等复杂操作的重要性,而不是继续过分关注探索算法。
本文贡献如下:
第一个工作是将文本输入生成问题表述为一个封闭型填空语言任务,以帮助现有的GUI测试工具实现更高的测试覆盖率。文本输入的实证调查和分类。这有助于理解文本输入生成任务,并为后续研究提供了一个公开可用的多样化移动应用文本输入数据集。一种基于LLM的“预训练、prompt和预测”范式,通过理解局部和全局上下文自动推断语义文本输入的新方法QTypist。1 方法
本文提出了一种感知上下文的自动文本输入生成方法QTypist,以增强移动GUI测试。我们使用预训练的LLM智能生成带语义的输入文本,如图4所示。具体来说,给定一个带有文本输入框的GUI页面及其相应的View层次文件,我们首先提取文本输入框的上下文信息,并设计语言模式来生成prompt作为LLM的输入。为了提高LLM在移动GUI中文本输入的性能,我们开发了一种基于prompt的数据构建和调优方法,自动提取prompt和answer进行模型调优。

图2:QTypist框架图
A. 感知上下文的prompt生成
LLM在海量的、多样化的语料库上进行了训练,在各种任务上都有出色的表现。以往的研究也表明,它的性能会受到输入质量的显著影响,即输入是否能准确地描述要问的问题。与此同时,我们观察到,在使用应用程序时,人们倾向于浏览整个GUI页面来确定输入内容,而不是专注于某个文本输入框。为此,我们开发了一种上下文感知的prompt生成方法来构建LLM的输入prompt,以便准确描述输入框信息,方便LLM输出期望的answer。我们首先为输入框组件提取上下文信息,并为prompt的生成设计语言模式。
1) 上下文提取:如图2所示,对于输入组件及其GUI页面,我们从View层次文件中提取上下文信息,这些信息很容易通过自动化GUI测试工具获得。我们具体提取了以下三类信息:
输入组件信息是描述输入组件内在含义的最重要来源。候选信息包括输入小部件的“hint-text”字段、“resourceid”字段、“text”字段,我们按顺序选择第一个非空字段。
本地上下文信息表示输入组件附近的信息,这些信息有助于理解上下文语义。候选信息源包括父节点组件、叶节点组件、具有相同水平轴的组件和当前GUI页面的Fragment。对于每个信息源,我们提取“text”或“resource-id”字段(按顺序第一个非空字段),并将这些信息用分隔符组合在一起。
全局上下文信息表示与输入组件的高级语义相关的信息,它可以进一步帮助改进对输入组件的理解。候选信息源包括当前Activity名称、应用程序名称和GUI页面上的许多输入组件。
2) Prompt生成:对提取的信息进行预处理,设计语言模式生成Prompt,输入到LLM中。
预处理:考虑到应用程序开发中的命名约定,我们首先使用下划线和驼峰命名对提取的信息进行标记,并去除停止词以降低噪声。然后,我们对信息进行词性标注,以便突出显示关键字。具体来说,我们使用了斯坦福NLP解析器,并且在设计语言模式时特别注意名词、动词、介词。
如第二节所示,应用程序的输入内容是多样化的,这会影响LLM理解应该输出什么,因此在设计语言模式时,我们会考虑输入类别。
我们采用直接的关键字匹配方法来得到输入类别。基于我们试点研究中标记的所有2600个应用程序,我们总结了5个词汇表(例如,位置,搜索等,详细信息在我们的GitHub2中)对应于5个输入类别。然后,我们利用Activity名称和应用程序名称中的信息,并按照第II-A2节中的类别顺序,检查是否有一个词汇表匹配。
Prompt的语言模式:在设计模式时,四位作者为输入组件编写Prompt句子,输入到LLM中生成输入内容,并检查该内容是否可以使应用程序跳转到新的Activity。每个作者都可以访问从试点研究中随机选择的500个应用程序,他/她可以获得与输入组件、本地上下文和全局上下文相关的预处理信息。经过5个小时的试验,要求他/她提供最好的和最多样化的30个Prompt,作为设计模式的种子。然后,四位作者利用Prompt句子进行卡片分类和讨论,得出下面展示的语言模式。
表1:Prompt的语言模式和Prompt生成规则的例子

该过程得出了14种语言模式,分别与输入组件、局部上下文和全局上下文相关;表1显示了其中的8个,由于空间限制,其余的在我们的GitHub网站上。输入组件的模式显式地指定了应该输入到组件中的内容,我们使用名词(widget[n])、动词(widget[v])和介词(widget[prep])等关键字来设计模式。我们设计了两种表达形式,即continuation(例如,“游戏名称是:”)和mask(例如,“你的体重是[mask] kg”),以准确地描述输入组件的特征。关于本地和全局上下文的模式从整个GUI页面和整个应用程序的角度增强Prompt。例如,全局模式对应用程序名称、Activity名称和输入类别等信息进行编码。
Prompt生成规则:由于所设计的模式是从不同的角度描述信息的,因此我们将不同角度的模式组合在一起,生成如表1所示的Prompt规则。对于两种典型情况,即具有一个输入组件的GUI页面和具有多个输入组件的GUI页面,分别有两条规则。对于前一种情况,我们简单地将来自三个信息源的模式组合在一起,如表1中的规则1所示。对于后一种情况,由于GUI页面中的所有输入组件共享相同的全局上下文,因此我们首先使用关于全局上下文的模式,然后使用具有本地上下文和每个文本输入组件的模式,如表1中的规则2所示。由于LLM的健壮性,生成的Prompt句子不需要完全按照语法。我们还在图3中提供了一些示例来说明规则是如何工作的。

图3:输入prompt生成的例子
B. 基于Prompt的数据构建和调优
一般的预训练模型很难很好地完成特定领域的任务(如app文本输入生成),一种常见的做法是对模型进行Prompt-tune,使其理解和识别输入Prompt语法。然而,到目前为止,还没有这种类型的带有输入Prompt和相应Answer的开放数据集。人工收集数据非常费时费力,而且人为的偏见和缺乏多样性可能会进一步降低数据质量。同时,我们注意到一些组件类似于输入组件,并且具有候选或预输入内容(如Answer),这自然符合我们的目的。因此,我们开发了一种从View层次文件自动构建基于Prompt的数据集的方法,以对预训练模型进行Prompt-tune。
具体来说,我们找到了3个可以用于数据构建的案例,如图4所示。(1)一些输入部件包含候选输入内容的关联列表,这些候选输入内容可以被视为已经有了输入。(2)弹出菜单是输入组件的另一种变体,它具有可用于数据构建的候选输入内容。(3)一些具有View层次文件的开放数据集是由众包工作者收集的(Rico是众包收集的最大的移动应用ui存储库),因此一些输入组件包含预填充的内容。我们将这些具有候选输入内容的输入组件视为显式输入组件,并描述如何利用这些组件进行数据构建。

图4:数据构建的3个例子
1) 组件提取:构造prompt和answer的挑战是找到显式输入组件,并将其候选输入内容映射到组件上。
从搜索列表中提取:对于这种情况,通常有一个输入组件(EditText)和它的关联列表(ListView)。我们首先检查是否有一个ListView直接在EditText下面,如果这样,我们把EditText当作显式输入组件。对于候选输入内容,如果ListView中的所有项都是TextView(例如,如图4 (a)所示的单词或短语),则直接将文本视为候选输入内容。否则,如果包含标题和正文(例如,包含标题和发布时间的新闻列表),我们只通过检查每个条目中具有最小纵坐标值的TextView来提取标题作为候选输入内容。
从弹出式菜单中提取:当单击Spinner时触发弹出式菜单,并包含一个TextView列表。如图4 (b)所示,我们首先找到一个Spinner组件,并按顺序检索横坐标小于Spinner最小横坐标或纵坐标小于Spinner最小纵坐标的TextView。然后,我们将TextView作为显式输入组件,并将Spinner的“hint-text”字段作为候选输入内容。
从填充内容中提取:众包工作者填充的内容显示在EditText的“hint-text”属性中,我们对开发者预设内容的案例进行过滤,保留人工填充的案例。这是通过过滤“hint-text”包含“search, add, input, enter, etc”等预设信息的 EditText 来完成的,这些信息有很高的概率是预设的。然后,我们将EditText视为显式输入组件,并使用“hint-text”字段作为数据构造的输入内容。
2) Prompt和answer生成:在获得三种类型的显式输入部件及其候选输入内容后,我们生成用于模型调优的prompt和answer对。具体来说,我们使用Scetion III-A中的方法获取显式输入组件的输入prompt,即输入显式输入组件及其上下文信息,得到输入的prompt句子。我们将候选输入内容作为answer。
然后我们微调模型,将prompt作为输入,将answer作为输出(与预训练模型相同的学习目标)。这种prompt-tune刺激预训练模型识别微调数据的输入prompt句法和使用模式。因此,在训练模型理解问题方面,它可以比一般的微调更有效。
C. 文本输入生成模型
QTypist的核心部分是预训练的LLM,它已被证明在许多下游任务中是有效的,例如问答,文章生成等。多个LLM已被提出并应用于各个领域,如GPT-3, BERT, RoBERTa, T5。本文选择GPT-3 (Generative Pre-trained Transformer-3),它是OpenAI最先进的LLM,在数十亿个令牌上训练了1750亿个参数,可以智能地生成语义文本。我们使用Section III-A中得到的输入Prompt作为模型的输入,并将其输入到GPT-3模型中。模型输出用作输入内容,以增强自动化测试。模型细节见Section II-B。
D. 实现
我们基于OpenAI网站上发布的预训练GPT-3模型实现了我们的文本输入生成模型。GPT-3的基础模型是极其强大且擅长回答问题的Curie模型,OpenAI CLI版本为0.9.4,batch size为64,epoch为100,learning rate multiplier为0.01。我们构建了包含Rico和FrontMatter的7000对prompt和answer的调优数据集,用于提示调优GPT-3模型,prompt-tune的时间约为12小时。QTypist通过UIAutomator获取当前UI页面的View层次文件,分析提取文本输入组件信息。QTypist可以通过替换自动GUI测试工具的文本输入生成模块来集成,该模块自动获取View层次文件中的输入组件,并生成相应的文本,以提高Activity覆盖率。
2 实验 - 有效性评估
为了验证QTypist的文本生成性能,我们通过判断生成的文本输入是否可以通过需要文本输入的UI页面来进行评估。在下一节中,我们将通过将QTypist与自动化GUI测试工具集成,进一步评估QTypist在实际实践中的有效性。
•RQ1:我们建议的QTypist在通过需要文本输入的UI页面时效果如何?
对于RQ1,我们比较了QTypist与11种常用和最先进的方法的通过率(详情见Section IV-B)。
•RQ2: QTypist生成的输入文本质量如何?
对于RQ2,我们要求20个测试人员手动检查其生成的输入文本的质量。
A. 实验设置
对于RQ1,我们从Google Play中抓取了每个类别中最受欢迎的100款应用,并只保留了2022年3月之后至少更新过一次的最新应用,结果是12个应用类别中有637款应用。然后,我们使用DroidBot自动运行这些应用程序,通过分析运行时View层次文件来探索应用程序,以定位需要文本输入的GUI。请注意,我们通过以下条件过滤掉了一些应用:(1)UIAutomator无法获取View层次文件;(2)不断地在模拟器上崩溃;(3)一条或多条baseline不能在其上运行;(4)它们没有需要文本输入的页面。最后,106个应用程序和168个文本输入仍有待进一步试验。应用程序的详细信息如表2所示。我们采用通过率(通过需要文本输入的UI页面),这是一个广泛用于评估GUI测试的指标。具体来说,我们从每个应用中随机选择一个带有文本输入的UI页面,并通过UIAutomator获取View层次文件,输入由QTypist生成的文本,并检查它是否能通过需要文本输入的UI页面。为了进一步评估QTypist的优势,我们还将其与11个常用和最先进的baseline进行了比较(详细信息请参见第IV-B节)。我们为每个baseline设计了脚本,以确保它可以覆盖文本输入页面,并且每个工具在相同的实验环境(Android x64模拟器)中重复三次,以减轻潜在的偏差;只要有一次通过,我们就把它当作成功通过。
表2:有效性评估的数据

对于RQ2,我们进行用户研究以验证QTypist生成的输入文本的质量。我们在线招聘了20名软件测试人员,他们都是计算机专业的,有3年以上的软件测试经验。它们中的每一个都显示了应用程序的UI页面、从QTypist生成的输入文本和RQ1中的baseline。他们需要独立评估输入的文本生成结果,并使用5-Likert量表回答他们是否同意每个生成结果的问题,即强烈同意、同意、中立、不同意、强烈不同意。我们采用Kendall 's W (Kendall 's coefficient of concordance)来评估不同从业者之间结果的一致性。测试结果越接近1,评分者的评价结果之间的一致性越高。评估结果应在8小时内返回,以确保本研究的可信度。
B. Baseline
为了展示QTypist的优势,我们将其与11个常用的和最先进的baseline进行比较。为了便于理解,我们将它们大致分为基于随机/规则的方法、基于约束的方法和基于学习的方法。8种随机/基于规则的方法来自自动化GUI测试工具,另外3种方法是专门为应用程序输入生成而设计的。
对于基于随机/规则的方法,我们使用了Stoat、Droidbot、Ape、Fastbot、ComboDroid、timemmachine、Humanoid、Q-testing。对于基于约束的方法,我们使用Mobolic和TextExerciser。Mobolic通过结合在线测试技术和输入约束生成输入文本。TextExerciser的关键思想是,Android应用程序经常为格式错误的输入提供反馈,称为hint,因此该方法利用这种hint来改进输入生成。对于基于学习的方法,Liu等人利用RNN模型和Word2Vec来预测给定输入部件的文本输入值(为简单起见将其表示为RNNInput),我们也使用我们模型数据集的所有标记数据来训练RNNInput。
C. 结果
1) QTypist通过率(RQ1):表三为QTypist通过率及baseline。QTypist在106个UI页面中实现了0.87的通过率。这表明QTypist在通过大部分转换以促进覆盖更多页面的自动化GUI测试方面的有效性。
表3:通过率的结果(RQ1)

QTypist比最佳baseline(RNNInput)高出93%(0.87比0.45)。与RNNInput相比,我们提出的方法充分利用了文本输入周围的上下文信息,并利用预训练的大型语言模型的能力来更好地理解输入文本。而其baseline方法主要是随机生成文本或使用启发式规则生成文本,导致生成的文本受模板影响较大,鲁棒性较低。对于基于约束的方法,如TextExerciser,由于与反馈相关的组件只覆盖了所有情况的一小部分,例如大多数与地理相关的输入组件不涉及反馈,因此相关性能较差。我们还观察到,baseline在评论类别中有很高的通过率,主要是因为在该类别中输入的没有语义的文本可以通过。因此,我们需要通过RQ2进一步评估生成文本的质量。
图5通过举例说明了QTypist与baseline相比的优势。我们可以看到QTypist在更多的场景中表现得更好,例如,回答问题,编写代码等。QTypist还可以生成一些具有实际意义的文本,如图5 (a)中的“Blood pressure record”。我们进一步分析了QTypist未通过页面的案例,总结出以下两点原因。(1) GUI页面没有上下文组件和没有语义信息的文本输入。在这种情况下,将其他上下文信息合并为附近的UI页面可以增强对查询组件的理解。(2)应用需要特定且唯一的文本输入,如服务器地址、数据库连接等。

图5:QTypist输入文本的例子
我们还通过比较基于prompt的数据构建和调优方法的通过率来研究基于prompt的数据构建和调优方法的贡献。从表III中,我们可以看到,当使用调优数据对模型进行prompt-tune时,通过率提高了43% (0.61 vs 0.87),这表明自动生成的调优数据对有效生成输入文本的价值。
2) 输入文本生成质量(RQ2):图6提供了20个测试者对5-Likert量表的反应。总的来说,这些测试者的反应相当积极。从业者对QTypist输入内容生成结果的多样性和准确性表示强烈认同或赞同,即平均得分为4.4分。他们普遍认为用QTypist生成的输入内容容易理解,也更合理。平均Kendall 's W的结果为0.8,表明QTypist的输入内容生成性能具有高度的一致性,更详细的信息可以在我们的网站上找到。
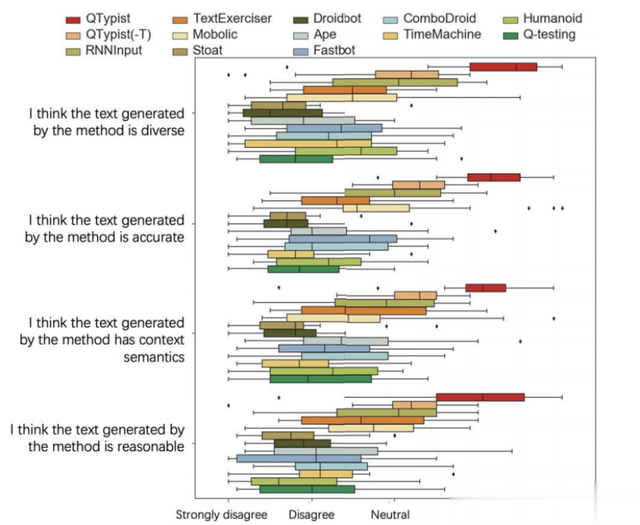
图6:生成输入的准确率结果
我们在没有微调的情况下进一步分析baseline和QTypist的响应。如图6所示,参与者对QTypist生成的输入文本有一定的识别程度,平均得分为4.2分。对于其他11个baseline方法,参与者认为RNNInput和TextExerciser生成的文本在许多情况下是不正确的。然而,参与者不同意或强烈不同意其他自动化GUI测试工具生成的文本。参与者认为,他们随机生成的文本,即使可以偶然传递,也没有语义和实际意义。如图5上半部分所示,虽然RNNInput和TextExerciser也可以通过测试,但是输入的文本并不符合实际的语义。QTypist生成带有语义的文本,这有助于发现更多潜在的问题,例如,由长输入文本引起的显示问题或兼容性问题。
3 实验 - 有用性评估
除了上一节中的有效性评估之外,我们还进一步评估了QTypist在增加自动化GUI测试方面的有用性。我们的目标是检查:(1)QTypist是否可以有效地帮助自动化GUI测试工具覆盖更多的UI页面?(2) QTypist是否可以帮助自动化GUI测试工具找到更多的bug(因为探索了更多的页面)?
1)实验设置:我们从Google play中随机抽取30个未在第四节有效性评估中涉及的Android应用,3个自动化GUI测试工具可以正常运行这些应用。他们至少有一个文本输入,源代码和GitHub上的问题报告。为了进一步确保数据集不重叠,我们通过匹配App Name来删除已经出现在前几个阶段的App。对于一些需要实际帐户登录的应用程序,我们通过脚本跳过这个过程。我们使用被触发的活动和UI页面的数量,以及暴露的bug的数量作为我们的指标。注意,一个活动中可能有多个UI页面,因此我们也使用被触发的UI页面进行评估。UI页面的判断依据与前人的研究一致。我们将QTypist集成到3个流行和常用的自动化GUI测试工具中,Monkey, DroidBot和Ape,作为有用性评估的示例。所有实验均在运行Android 6.0的官方Android x64模拟器上进行,服务器采用Xeon E5-2650 v4处理器。每个模拟器都分配了4个专用CPU内核、4 GB RAM和4 GB内部存储空间。
2)结果: 结果如表4所示。平均而言,使用QTypist的自动化GUI测试工具触发的Activity和页面数量要高于没有使用QTypist的工具。特别是,与Monkey相比,带有QTypist的Monkey触发的Activity比Monkey多28%,页面比Monkey多30%;带有QTypist的DroidBot触发的Activity比DroidBot多33%,页面比DroidBot多41%;带有QTypist的Ape触发的Activity比Ape多42%,页面比Ape多52%。
表4:QTypist与自动化GUI测试工具的Activity和页面数量的对比结果

有了QTypist, Ape可以从30个应用程序中发现51个错误,比没有QTypist的Ape检测到的错误多122%(51比23),我们在网站上发布了漏洞详细信息。这些bug是开发者已经确认的崩溃bug。与没有QTypist的Monkey相比,带有QTypist的Monkey检测到的bug多109%(23比11),带有QTypist的DroidBot检测到的bug多106%(35比17)。进一步说明了QTypist的实用价值。
然后,我们进一步评估QTypist在促进检测新错误(未记录在问题存储库中)方面的能力,因为覆盖更多的UI页面可能有助于揭示更多的错误。我们根据下载量选择了排名前200的应用,并过滤掉了那些自2022年3月以来没有更新过的应用,以及那些无法在官方Android模拟器上正常运行的应用,共有113个应用程序被保留下来。我们运行与QTypist集成的Ape(因为考虑到表4中的结果,Ape表现最好),记录bug,并在应用程序的问题存储库中搜索以确认之前没有报告过。它从25个应用程序中检测到以前未检测到的28个错误,而没有QTypist的Ape则没有检测到这些错误。
请注意,这些错误不是由输入文本直接触发的,而是因为Ape with QTypist在输入正确的文本输入后成功地覆盖了更多的Activity,随后显示了这些错误。我们通过电子邮件或GitHub问题向开发人员提交这些错误报告(详细信息请参阅我们的网站),11个已确认,6个已修复,其余待定。这些修复或确认的错误进一步证明了使用QTypist的自动化GUI测试工具的有效性和实用性。
转述:陈宇琛
