编辑:alan
【新智元导读】近日,Nous Research宣布了一项重大突破,通过使用与架构和网络无关的分布式优化器,研究人员成功将训练LLM时GPU间的通信量降低了1000到10000倍!如果可以使用世界上所有的算力来训练AI模型,会怎么样?

近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。
通过使用与架构和网络无关的分布式优化器,研究人员成功将训练LLM时GPU间的通信量降低了1000到10000倍!

初步技术报告:https://github.com/NousResearch/DisTrO/
在如此夸张的改进之下,大模型训练的重要成本和瓶颈——带宽,也就不再是问题。
使用DisTrO的方法,你可以将训练负载分布到互联网上,而整个网络世界也就成为了一个巨大的异构的AI服务器集群。
——任何有相关算力的设备都可以参与到训练过程之中。

实验证明,本文的方法基本不会导致模型性能下降,同时DisTrO-AdamW在收敛速度方面,也与标准的AdamW+All-Reduce相当。
分布式互联网训练
一般来说,训练大规模神经网络涉及到大量的通信开销。
比如做数据并行的时候,不同的训练数据在不同的硬件(显卡等)上进行前向和反向计算,之后,同一批数据计算出的梯度需要在显卡之间先完成同步,才能进入下一个epoch。

如果是模型并行,那么中间数据就需要通过All-Reduce进行拼接或者累加。
这些数据通信开销如果不能overlap掉,就会成为模型训练的瓶颈。
而恰好,老黄的显存和带宽又很贵,甚至组多卡时候需要的硬件也很贵。

为了解决这个问题,研究人员开发了DisTrO,在不依赖摊销分析的情况下,将GPU间通信要求降低了四到五个数量级,从而能够在慢速网络上对大型神经网络进行低延迟训练。
DisTrO是通用、可扩展,并且时钟同步的(与SGD、Adam等类似,每个训练步骤使用相同的算术运算并花费相同的时间)。
另外,与之前的ad-hoc低通信优化器相比,DisTrO对电信网络的拓扑和神经网络架构不敏感,能够以最小的开销原生支持分布式数据并行训练(DDP)。
LLM预训练研究人员使用Nanotron作为预训练框架,且仅在DDP策略下运行(每个GPU都将整个模型加载到VRAM中)。
LLM选择1.2B大小的Llama 2,模型和训练所用的超参数如下:

训练数据使用Dolma v1.7数据集,随机选出的10%代表性样本(前 105B个token)。
优化器采用AdamW,β1=0.9、β2=0.95,峰值学习率为4×10e-4,使用余弦衰减方案,权重衰减设置为0.1。
作为对比的另一组实验,将AdamW替换为DisTrO-AdamW,但不更改超参数,并禁用Nanotron中的All-Reduce操作。

与以前的分布式训练方法不同,DisTrO不同步优化器状态(甚至可以无状态)。
下图是两组实验的训练损失曲线,使用105B数据训练25000步。可以看出,DisTrO的收敛能力与All-Reduce持平。
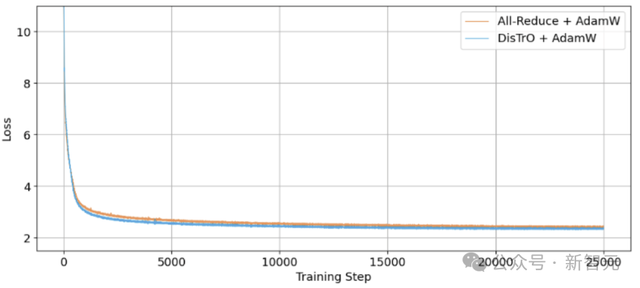
重要的是,在不影响训练效果的情况下,DisTrO将通信量从74.4GB直接减到了86.8MB!相当于带宽压力减少了857倍。

作者还表示,这857倍只是初期测试,后面调调超参数,减少个1000倍到3000倍也不是问题。
如果是后训练和微调,甚至可以实现高达10000倍的通信优化,且基本不影响训练效果。
最后,为了验证训练效果,作者在训练后的模型上执行了GPT4All零样本基准测试,并与在相同数量的token上训练的TinyLlama(checkpoint)进行了比较。

结果如上表所示,TinyLlama的架构和训练过程与本文的实验非常相似,可以作为对结果进行健全性检查的衡量标准。
未来应用
数据流
在本实验的场景中,32个节点使用最简单的All-Reduce(全连接),每个节点平均传输86.8MB(2.8MB×31),并接收相同数量的数据。

如果使用专用服务器进行数据聚合,则每个节点只需上传2.8MB数据(接收数据不变),通信量进一步减少。
另外,不对称性是有优点的,因为大多数消费互联网的带宽严重偏向于更高的下载速度。
假设稳定的网速为100Mbps下载和10Mbps上传,则最坏情况下的延迟仅为下载6.94秒,上传2.24秒,overlap一下则每步延迟为6.94秒。
ps:以上的数据传输都是原始的向量,如果用上压缩技术还能更快。
带宽
作者表示,目前的实验和研究还比较有限,无法断定随着模型变大,带宽减少的比率是会增加、减少还是保持不变。
不过目前的1.2B似乎是DisTrO能够良好工作的最小尺寸(再小就不收敛了),所以可以假设随着模型大小的增长,需要的通信会相对越来越少。
不过也可能通信量与模型大小没有关系,这时可以在不增加通信带宽的情况下增加模型大小,观察更大的模型是否会改善训练和学习的效果。
如果后一种情况属实,那么未来GPU设计和制造的范式将会被改变(更大VRAM和更窄带宽)。
恰好我们也更喜欢计算密集型负载(而不是I/O密集型),毕竟现在的带宽要比计算贵得多。
联邦学习
除了训练LLM,DisTrO还能用来做什么?
在互联网上做分布式训练,让人一下就想到了联邦学习。
在允许模型协作训练的同时,保持每个参与者的数据的私密性和去中心化,这在LLM被大公司掌握的当下,显得越来越重要。

到目前为止,联邦学习一直缺乏在有限的互联网带宽上训练大型模型的有效方法。
而DisTrO对如何处理数据,或将数据分配给各个GPU节点没有任何要求,并且可以无状态(类似于联邦平均),因此适用于联邦学习的未来。
虚拟异构GPU集群
此外,DisTrO可以创建一个完全去中心化且无需许可的网络来协作和共享资源。
实验表明,DisTrO对于训练期间少量降级或丢弃的节点具有显著的弹性,并且可以轻松地适应新节点的加入。
在这种能力加持之下,一方面可以保障整个系统的安全性,降低不可信节点使用对抗性攻击破坏运行的风险。
另一方面,也可以鼓励机构和个人灵活贡献自己的计算资源,释放潜在的算力。
甚至一些内存或者算力不太够的老卡,也能加入进来赚点外快,采用FSDP、SWARM Parallelism等策略与DisTrO协同工作。
能源
DisTrO的进一步大规模应用,可能会缓解建设大型数据中心所带来的能源消耗、基础设施成本和土地使用等相关问题。
Llama 3.1项目需要构建两个大型整体超级集群,每个集群包含 24,000个H100 GPU,仅训练过程就产生了相当于11,000吨的二氧化碳排放。

当今的LLM,除了模型参数大小的增长,训练数据量也在不断增大,导致AI相关的数据中心已经摸到了现代电网的极限。
DisTrO可用于自适应平衡多个使用过剩容量的小型模块化数据中心,通过动态平衡训练技术利用现有基础设施,减轻训练对环境的负面影响。
目前,DisTrO背后的理论还需要进一步探究,更严谨、更详细的学术论文以及完整的代码将在未来发布。
参考资料:
https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
