InferFix: End-to-End Program Repair with LLMs
Matthew Jin, Syed Shahriar, Michele Tufano, Xin Shi, Shuai Lu, Neel Sundaresan,Alexey Svyatkovskiy
引用
Matthew Jin, Syed Shahriar, Michele Tufano, Xin Shi, Shuai Lu, Neel Sundaresan, and Alexey Svyatkovskiy. 2023. InferFix: End-to-End Program Repair with LLMs. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023). Association for Computing Machinery, New York, NY, USA, 1646–1656. https://doi.org/10.1145/3611643.3613892
论文:https://arxiv.org/pdf/2303.07263
摘要
通过少量演示学习和指令提示,大型语言模型已经适应了程序修复任务,并将其视为一项填充任务。然而,这些模型只专注于学习从公共存储库中挖掘的未分类错误的一般错误修复模式。在本文中,我们提出了InferFix:一个基于变压器的程序修复框架,与最先进的静态分析器配对,以修复关键的安全和性能错误。评估表明,InferFix优于强大的LLM基线技术,在C#中生成修复的准确率为65.6%,在Java中为76.8%。我们讨论了 InferFix 与 Microsoft Infer的部署,后者提供了用于错误检测、分类和本地化以及候选补丁修复和验证的端到端解决方案,集成在持续集成管道中以实现软件开发工作流程自动化。
1 引言
最近提出的许多错误预测、检测和修复方法都依赖于机器学习算法——众所周知,机器学习算法需要大量高质量的数据来进行有效的训练。大型语言模型通过少量演示学习和指令提示,成功适应了程序修复任务,将其视为填充任务。然而,当专注于解决具体的研究问题时,他们未能提供可产品化的可靠的端到端程序修复解决方案。
像Infer这样的静态分析工具可以用来识别关键的安全和性能问题。这可能会占用软件开发周期的大部分时间,包括创建详细单元测试的过程,对于代码被分解为许多模块或跨许多文件的大型复杂项目来说,这可能非常耗时且困难。它们还可以识别错误,并以一种机器可读的方式生成错误报告,并且有利于与补丁生成模型一起使用。
在这项工作中,我们重点关注Infer报告的三种类型的错误:空指针解引用(NPD),资源泄漏(RL)和线程安全违反(TSV)。我们之所以关注这些问题,是因为它们会带来关键的性能、可靠性和安全问题,并且比其他类型的问题更难以修复,而其他类型的问题也更容易被检测和研究。
在本文中,我们介绍了一个程序修复框架,它结合了一个通过对比学习预训练的变压器编码器模型,作为历史错误和修复数据库的检索器,以及一个大型语言模型(120亿参数Codex Cushman模型,code-cushman-001),该模型配备了利用外部数据库检索信息的工具。鉴于基线Codex模型已被证明偶尔会预测不安全或有缺陷的代码,我们优先在一个无缺陷的有监督的错误和修复数据集上对其进行微调,该数据集通过外部非参数存储器的相关程序修复模式丰富了上下文。本文的贡献如下:(i)我们提出了一个程序修复框架,该框架利用静态分析进行错误检测、定位和分类,并与一个大型语言模型相匹配,该模型在增强提示数据集上对程序修复任务进行了微调,(ii)我们策划了InferredBugs:使用Infer静态分析器提取的Java和C#编程语言的错误和修复的元数据丰富的数据集,(iii)我们为程序修复任务引入了专用的提示增强技术,该技术利用从外部数据库的历史错误和修复,错误类型注释和语法层次结构的密集检索,以及受错误影响的整个源代码文件,(iv)我们在InferredBugs数据集上评估我们的模型。在Java中实现了76%的顶级补丁生成准确率,在C#中实现了65%以上的准确率,跨越了空指针解引用、资源泄漏和线程安全违反错误类型,最后(v)我们将InferFix部署为GitHub操作,并将其作为微软内部Azure DevOps持续集成管道的一部分,并记录了部署的各个方面。
2 技术示例
在典型的连续软件开发工作流中,软件工程师对特性分支进行原子的、迭代的更改,周期性地合并到主要的生产分支中,然后将其连续地、自动地部署到最终用户中。考虑一个大型软件项目,其模块化代码库分布在多个源代码文件中。就开发人员的时间和精力而言,在将错误合并到main之前手动检测、本地化和修复错误是非常低效的。此外,它需要创建一个广泛的单元测试套件,以确保一个特性或变更可以跨软件的所有可能版本工作,并且没有引入回归。

图1:使用InferFix自动化的软件开发工作流。
图1说明了Microsoft Developer Division在使用InferFix时的典型软件开发工作流程。当提出代码变更的拉取请求被创建时,持续集成管道(CI)触发单元测试、构建和推断静态分析步骤。如果检测到错误,将调用InferFixpatch生成模块来提出修复。然后,建议的bug修复被验证,并随后作为bug修复pull请求提供给功能分支,允许开发人员在将代码合并到生产分支之前捕获bug。
我们的方法结合了一个静态分析器来检测、定位和分类错误,以及一个强大的LLM(经过微调的120亿个参数的Codex模型)来生成修复。
图2基于acs-aem-common存储库中的一个真实错误示例提供了有关InferFix工作流的详细信息,该存储库是用于内容管理的统一代码集合,用于优化用Java编写的内容和数字媒体的创作和交付。Infer静态分析器检测到空指针解引用错误,这是由于getResourceResolver(this, adaptive)调用返回的代码中的一个对象,该对象可能为空,并在第168行解引用。上下文预处理模块利用这些信息由分析器提供以提取有bug的方法,并保留与修复bug最相关的周围上下文- import语句,类签名,在buggy行调用的getResourceResolver方法的主体。然后,检索增强引擎在历史数据库中搜索语义上相似的错误代码片段,并在提示符之前添加类似的错误修复。最后,将增强后的提示发送给调整后的Codex模型进行推理。然后通过执行Infer静态分析器和单元测试(作为持续集成管道的一部分)来验证预测的补丁,以确保错误确实被修复,并且没有在代码库中引入回归。

图2:InferFix工作流。
3 实验评估
3.1 数据集
我们收集了用Infer(Infer静态分析器)检测到的bug的监督数据集,该数据集通过分离逻辑执行语义分析。我们对GitHub上托管的大约6.2万个Java和C#开源存储库(2.9万个Java, 3.3万个C#)的变更历史执行了Infer和intersharp,分析了超过100万次提交。虽然一些bug数据集已经可用,如Defects4j, QuixBugs, ManySStuBs4J, UnifiedBugDataset等,但我们引入的数据集是通过静态分析提供的关于每个bug的信息的数量和质量来区分的。具体来说,数据集中的每个bug都与几段元数据相关联。
使用Infer收集数据
给定当前提交时数和前一次提交时数作为输入,我们首先计算git diff,以识别开发人员在提交时数中执行的更改所涉及的文件。接下来,我们分析提交前的文件状态。具体来说,我们在提交之前检出系统的快照,并使用特定于项目的构建工具构建系统。在构建过程中,infer capture命令拦截对编译器读取源文件的调用,并将其转换为允许infer分析这些文件的中间表示。接下来,我们调用infer analyze命令,指定要分析的文件(即提交中涉及的文件)。该分析生成报告reportPrev,详细说明在指定文件中识别的错误。
随后,我们移动到当前提交当前,并执行与之前提交相同的步骤,即:检出提交,在捕获源文件的同时构建系统,并分析diff文件以检测错误。
最后,使用infer reportdiff命令,我们计算两个infer报告reportPrev和reportCurr之间的差异。输出错误包含三类问题:introduced,在curr中发现的问题,而不是在prev中发现的问题;fixed,以前发现的问题,但没有在当前;preexisting,在prev和current中都发现的问题。
数据集的统计数据
在2937个存储库上运行提取管道后,我们总共确定了8280个bug补丁。在这些bug中,259个是通过过滤过程的空引用补丁,462个是通过过滤过程的资源泄漏。我们注意到,过滤后的数据集包含的提交可能已经被传统方法检测到,这些方法涉及提取带有与期望的错误类型相关的某些关键字的提交。在259个空补丁中,有59个在相应的提交消息中包含“null”或“npe”,在462个资源泄漏补丁中,有15个包含“leak”关键字。从这里我们可以看到,我们能够提取许多额外的修复,而这些修复在使用幼稚的提交消息关键字匹配时是不会出现的。
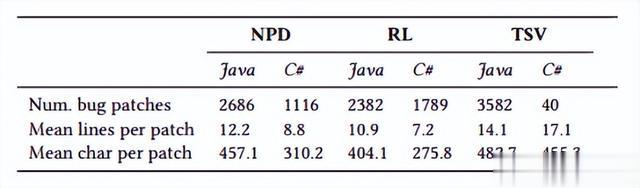
如表1所示,InferredBugs由多行错误组成,这代表了程序修复工具的一个具有挑战性的案例。
表1:根据文件数量和bug修复双向差异的大小InferredBugs数据集总结。
3.2 基准
我们收集了用Infer(Infer静态分析器)检测到的bug的监督数据集,该数据集通过分离逻辑执行语义分析。我们对GitHub上托管的大约6.2万个Java和C#开源存储库(2.9万个Java, 3.3万个C#)的变更历史执行了Infer和intersharp,分析了超过100万次提交。虽然一些bug数据集已经可用,如Defects4j, QuixBugs, ManySStuBs4J, UnifiedBugDataset等,但我们引入的数据集是通过静态分析提供的关于每个bug的信息的数量和质量来区分的。具体来说,数据集中的每个bug都与几段元数据相关联。
Infer是一个起源于分离逻辑的程序分析研究的开源静态分析工具。它最初是由初创公司Monoidics Ltd开发的,该公司于2013年被Facebook收购,并于2015年开源。它计算程序规范来检测与内存安全、并发性、安全性等相关的错误。它已在Meta、亚马逊和微软等公司进行了工业部署。虽然在本文中,我们将重点关注null解引用、资源泄漏和Infer检测到的线程安全违规,但它能够检测到更广泛的安全性和性能问题。例如,通过污染跟踪,它能够检测与数据流相关的问题,如SQL注入。
示范提示
演示学习是一种提示增强技术,在这种技术中,一些回答的提示被添加到上下文中,目的是演示语言模型应该如何处理下游任务。对于程序修复,我们引入了一个由两个已回答的提示组成的前缀as,后面是实际的错误代码片段,如图3所示。我们的几次示范学习实验是基于代码的强120亿个参数Codex语言模型。

图3: llm程序修复实验演示提示设计。
条件语言建模
我们的下一个基线是零射击条件语言生成(代码完成),其目的是利用下一个令牌预测来修复程序。具体来说,给定一个无bug的前缀,我们运行Codex模型推理来完成有bug的代码片段。在我们的实验中,我们采用top_p= 1和T= 0.7温度的核采样解码算法,生成了1024个令牌长度的前10个样本,前缀和完成的总长度为2048。我们的条件语言建模实验也是基于代码cushman-001。
3.3 INFERFIX框架
InferFix程序修复框架由以下三个关键模块组成:(i)一个检测、定位和分类bug的静态分析工具;(ii)检索模块——一个历史bug和修复的大型索引,配备了有效搜索和检索“提示”的功能——语义相似的源代码段——给定一个查询;(iii)生成器模块——一个大型语言模型,在一个提示数据集上进行微调,该数据集丰富了由静态分析器和检索器提供的信息,以生成修复。
Bug检测与分类模块
我们的错误检测、定位和分类模块由Infer提供支持,它通过分离逻辑执行程序分析。虽然Infer的Pulse框架最近才发布,但为了本文的目的,我们检查由Infer的双绑架框架产生的错误。用于Infer的编译器前端,如intersharp,将源代码转换为Infer可以理解的控制流图中间表示,称为Smallfoot中间语言。Infer在此图上执行自动程序分析,并生成组合方法摘要,以确定源代码中是否存在缺陷。
检索模块
我们的检索模块严格遵循ReACC公式。检索器在给定错误代码片段的情况下搜索语义等效的脆弱代码,并根据查询向量q与错误代码片段c之间的余弦相似度检索相应的修复候选代码。
采用对比学习目标对双向变压器编码器E进行预训练。对比学习是一种自监督学习技术,其中机器学习模型旨在从训练样本的共性中学习,同时也学习使样本不同的属性。给定一个对比预训练数据集:
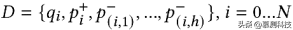
每个示例包含一个查询——一个有bug的代码片段的编码;阳性样本表示具有相同错误类型的语义相似的代码片段;以及一组负样本,它们是不同错误类型的不相关代码片段。对比损失由下式给出(正样本的负对数似然):
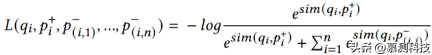
其中sim为嵌入向量之间的余弦相似度。
信号发生器模块
我们的生成器模型基于Codex Cushman(code- Cushman -001),这是OpenAI开发的12B参数纯解码器转换器语言模型,它是GPT-3的后代,在源代码上进行训练。
我们在从InferredBugs数据集提取的监督语料库上对Codex进行微调,目的是教模型为给定的错误代码生成修复。具体地说,模型的输入是带有附加信息的错误代码,例如错误定位和分类、分层扩展上下文以及检索到的类似修复。我们将在第6节中详细讨论提示增强过程。
我们执行完整的模型微调(更新模型的所有权重),在64个32 GB V100 GPU上进行5次epoch,通过精确匹配精度度量保留最佳模型检查点。我们利用Babel平台——一个模型存储库和一个AzureML设计器组件家族,在AzureML计算上汇集了最先进的变压器模型,以进行快速实验。我们使用Adam随机优化过程,其学习率为0.01,预热周期为1000个优化步骤,全局批大小为256。
3.4 提示增强
提示增强已被证明是从大型语言模型中提取高质量输出的一种强大技术,特别是用于领域和任务适应。在下面我们描述了我们的专用提示增强方法的程序修复任务。建议的方法是双重的:(i)我们提取和优先考虑与错误片段区域最相关的语法层次结构,包括焦点上下文;(ii)检索提示-从GitHub上的提交历史中获取结构类似的错误修复。通过这样做,我们正在构建一个松散结构的模板,其中包括以下内容: (1)检索提示(2)Bug类型标注(3)语法层次和对等方法(4)焦点方法(5)带位置标记的Bug方法。
图5显示了Java中空指针解引用错误的增强提示输入示例,其中包括由位置标记包围的有错误的代码区域,包含具有周围最相关语法层次结构的方法,但类型注释字符串和“提示”—从历史数据库检索的结构类似的错误修复。

图5: Java编程语言中受空指针解引用错误影响的方法的提示增强。
基本的提示
我们将这个基本提示和调优与强大的LLM基线进行比较。表2说明了与零射击和少射击变体相比,微调的效果。演示学习似乎是使Codex模型(code-cushman-001)适应下游补丁生成任务的最成功的几次学习策略,修复Java错误的准确率为19-25%。指令学习,也包括提示符中下游任务的自然语言描述,只有随着模型大小的增加才变得可行——我们用1750亿个参数的达芬奇模型(text-davinci-003)重复了指令学习实验,它是ChatGPT的近亲。我们观察到Davinci变体的性能非常有竞争力,仅通过提示增强修复Java错误的准确率就达到了40-53%。面向任务的微调,在没有任何提示制作的情况下,在Java中所有错误类型中显示出11-55%的相对准确性提高,大大优于所有少数射击基线。这种改进是以调整Codex模型所需的计算资源为代价的,但与少量的达芬奇相比,它提供了更高的准确性和更便宜的推理的优势。
表2:与LLM基线比较,基本提示下的InferFix评价结果

Bug类型注释
最简单的提示增强步骤是将错误类型注释添加到仅由有错误的方法组成的基本提示。如表3所示,这提高了所有bug类别和语言(Java和C#)的性能,准确度相对提高了2.7-5.6%。
表3:对InferFix的评估结果展示了在提示符中引入bug类型注释的影响。

Bug定位
错误位置信息对于准确的程序修复至关重要。Infer静态分析器可以通过跟踪程序中的数据流并检测任何违反预定义规则或编程模式的情况来定位错误。Infer静态分析器输出在运行时可能发生错误的行号,但是,这并不意味着修复只需要编辑这一行。在我们的数据集表1中,错误通常跨越多行代码,具有不相交的不同区域。
我们以两种方式利用Infer输出的错误位置信息:(i)我们解析受错误影响的源代码文件以提取包含有错误行的方法,以及(ii)我们用特殊的哨兵<START_BUG>和<END_BUG>符号包围有错误的区域。在训练期间,我们通过查看与修复相关的双向差异标记来细化错误位置。在测试期间,我们只使用静态分析器提供的信息,因为修复是未知的。表4演示了添加bug位置标记在提示符中加上bug类型注释的影响。如所见,这导致了所有类别研究的积极影响,准确率相对提高了3.4%。对于较大的方法,效果更为明显。
表4:显示在提示符中添加bug位置标记的效果的InferFix的评估结果。

eWASH扩展上下文
通常,受bug影响的方法将只包含调用表达式或对文件中其他地方定义的方法的调用——我们将其称为bug焦点方法。例如,在图5中,有bug的代码行有一个返回语句,该语句由getResourceResolver和adaptTo focal方法的方法调用链组成。我们推测,在提示符中保留焦点方法实现(签名、文档字符串和正文)对于程序修复至关重要。我们利用作为Infer bug报告的一部分提供的堆栈跟踪来确定相关的焦点方法名称,并将其包含在提示符中。表5显示了在提示符中添加eWASH语法层次结构和焦点上下文的效果。如上图所示,Java的补丁生成精度提高了7.2-7.8%,C#的补丁生成精度提高了4.0-6.7%。
表5:显示在提示符中添加eWASH扩展上下文的效果的InferFix评估结果。

提示丰富语境
为了专注于提取结构相似的修复并减少对标识符命名的依赖,我们混淆了服务的代码片段作为数据库和搜索查询中的关键字。也就是说,我们解析和分析代码标识符类型,并用占位符符号掩码类、方法和标识符的名称:CLASS_NN、METHOD_NN和VAR_NN,其中NN是唯一的数字。图6显示了一个混淆表示的示例。
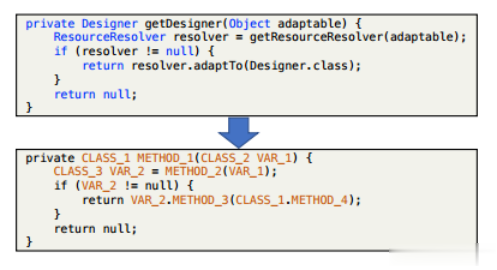
图6: Java代码混淆示例。
表6显示了使用包含检索提示的提示符的InferFix在bug修复功能方面的改进。这一提示增强进一步提高了在绝对排名前1的性能中的1-2%的InferFix性能。
表6:对InferFix的评估结果显示了添加bug修复提示的效果。

推理
InferFix的推理步骤涉及利用核采样解码,top_p参数为1.0,temperature为0.7。在此步骤中,该工具解码由大型语言模型生成的前10个最佳预测,并根据它们的序列日志概率对它们进行排名。这个排名有助于确保向用户呈现最可能和最相关的修复。使用核采样解码及其特定的top_p和温度参数,有助于在生成的预测中平衡多样性和质量之间的权衡,从而有可能获得高度准确和多样化的候选补丁。
3.5 实验结果
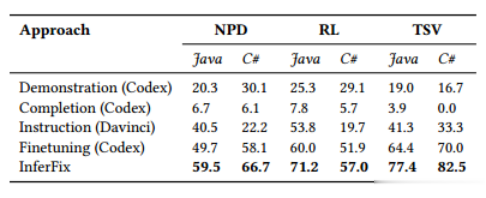
表7显示了与LLM基线相比,InferFix在InferredBugs数据集上获得的结果。在Java和C#的三类错误中,仅根据排名前一的预测,InferFix就能够修复57%到82%的错误。按绝对值计算,我们的方法与最佳基准之间的绩效差距在8.6%至13%之间。表中显示的百分比基于生成的补丁,这些补丁与原始开发人员的逐个令牌修复完全匹配。但是,可能有其他候选补丁可以使用不同的令牌序列正确修复错误。InferFix取得的令人印象深刻的前1名的结果对其高效和有效地集成到软件开发周期至关重要。由于能够为关键错误提出高质量的修复方案,因此,InferFix有可能极大地提高软件开发过程的生产力和可靠性。
表7:在InferredBugs数据集上对InferFix的评估结果与LLM基线进行比较
转述:王凌杰
