Multilingual Code Co-evolution using Large Language Models
Jiyang Zhang, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric
引用
Jiyang Zhang, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric. 2023. Multilingual Code Co-Evolution Using Large Language Models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’23), December 3–9, 2023, San Francisco, CA, USA. ACM, New York, NY, USA, 13 pages.
论文:https://doi.org/10.1145/3611643.3616350
仓库:https://github.com/EngineeringSoftware/codeditor
摘要
在本文制定了一项新任务:跨编程语言翻译代码更改,目标是同步以多种编程语言提供相同 API 或实现的项目。本文提出了 Codeeditor,这是一种使用代码更改历史记录作为上下文信息并学习对用目标编程语言编写的现有代码版本进行编辑的模型。Codeeditor优于现有的代码翻译模型,并且优于基于生成的模型,即使使用历史上下文也是如此。 Codeeditor 在支持开发人员维护其项目方面取得了重大进步,这些项目以多种编程语言逐步提供相同的功能。
1 引言
为了确保软件的灵活性和广泛采用,公司以多种编程语言为其服务提供应用程序编程接口 (API)。 Google Cloud 和 MongoDB 等服务提供用最流行的编程语言(包括 C、C、Java 和 Python)编写的 API。此外,流行的软件包,如 Antlr 和 Lucene ,可以选择针对不同的编程语言,以便轻松地跨各种平台使用。维护以多种编程语言提供相同功能的软件具有挑战性。由于功能请求或错误修复而导致的任何代码更改都必须及时传播到所有编程语言。目前,开发人员必须手动共同演化代码。这需要开发人员手动查找代码片段之间的对应关系并应用必要的编辑。理论上,已经有一些工作可以帮助翻译。基于规则的迁移工具被设计用于在高级编程语言(例如 Java 和 C)之间进行转换。然而,基于规则的系统要求具有两种编程语言专业知识的开发人员手动编写规则来指定翻译映射。并且规则需要随着编程语言本身的演变而更新;它们很快就会过时。最近关于自动代码翻译的工作旨在借助 LLM 直接在源编程语言和目标编程语言之间进行翻译,LLM 经过多种编程语言的预训练。虽然这些技术可用于生成看起来正确的代码片段,但它们会进行不相关的更改,这些更改与源编程语言中新引入的功能有很大的偏差,或者它们无法精确推断项目特定的数据类型和类名。

图1
图 1 说明了现有模型的局限性。开发人员在Java项目itext/itext7的docWithInvalidMapping02方法中将PdfException更改为LayoutExceptionMessageConstant。在相应的 C 项目 itext/-itext7-dotnet 的后续提交中,开发人员使用完全相同的编辑修改了方法 DocWithInvalidMapping02,同时保持该方法的其他部分不变。我们在图 1 中提供了 Java 代码更改、现有大型语言模型 CodeT5 的预测、代码翻译微调以及正确的 C 代码更改。添加的代码行以绿色突出显示,删除的代码行以绿色突出显示。那些以红色突出显示。尽管现有模型能够将更新的异常类型从 Java 正确转换为 C ,但它会丢失字段 HtmlRoles 的类名,并错误地推断函数调用 Assert.Catch ,因为它没有使用先前版本的 C 代码作为参考。
为了构建更强大、更准确的技术来帮助软件开发人员共同开发用不同语言实现的项目,我们明确地模拟了需要做出的改变。我们制定了一项新颖的任务:根据源编程语言中所做的更改,自动更新目标编程语言中的代码片段。大多数现有模型通过根据底层学习概率一一生成标记来隐式地处理代码演化任务,而不是关注代码应该如何修改或保留。先前的工作已经表明,基于标准生成的模型的性能低于显式对软件编辑任务的编辑进行建模的模型。
为了对跨编程语言的代码演变进行建模,我们设计了一个名为 Codeeditor 的 LLM,它学习跨编程语言对齐编辑,并以目标编程语言显式地对旧版本的代码执行编辑。继之前的工作之后,我们使模型能够推理必要的编辑并学习通过直接生成编辑序列来应用它们。为了进行训练和评估,我们收集了第一个数据集,其中对具有类似功能和实现的方法进行了一致的 Java 和 C 代码更改。具体来说,我们通过挖掘提交历史记录,从 8 个开源 Java 项目和 GitHub 上相应的 C 项目中提取了 6,613 对代码更改。这是第一个包含两种编程语言并行代码更改的数据集。我们从两个方向进行评估,根据Java变化更新C方法(源语言为Java,目标语言为C)和根据C变化更新Java方法(源语言为C,目标语言为Java)。我们的结果表明,Codeeditor 在所有选定的自动指标上都优于所有现有模型,包括少样本设置下的大型预训练生成模型 Codex和零样本设置下的 ChatGPT。 Codeeditor 在基于 Java 更改更新 C 代码的任务中获得了 96 分(满分 100 分)的 CodeBLEU 分数,比在此任务上微调的大型预训练生成模型高出 25% 以上。此外,我们发现 Codeeditor 和基于生成的模型是互补的,因为 Codeeditor 更擅长更新较长的代码片段,而生成模型更擅长处理较短的代码片段。因此,我们通过根据输入代码的大小选择任一模型的预测来组合这两个模型。我们的结果表明,这种组合可以将我们的 Codeeditor 模型的精确匹配精度进一步提高 6%。
本文的主要贡献包括:
任务:我们制定了一项新颖的任务,即根据另一种编程语言中相应代码的变化自动更新用一种编程语言编写的代码。模型:我们设计并实现了Codeeditor,这是该任务的第一个法学硕士,它学习跨编程语言调整编辑,并在目标编程语言的旧版本代码上显式执行编辑。数据集:我们通过来自 8 个开源项目对的两种编程语言(Java 和 C)的一致代码更改创建了第一个数据集。结果:我们表明,Codeeditor 在精确匹配准确率方面明显优于针对代码翻译进行微调的现有法学硕士 77%。我们还表明,Codeeditor 与基于生成的 LLM 是互补的,这种组合可以进一步将 Codeeditor 的精确匹配精度提高 6%。2 技术介绍
2.1 任务目标
在较高的层面上,我们开发的系统是在维护用多种编程语言编写的项目的软件开发人员对其中一种语言(即“源”语言)中的一种方法进行更改时触发的。系统会自动建议对其他语言(即“目标”语言)中具有相同功能的方法进行更新。为了确定本文工作的范围,我们重点关注 Java 作为源语言,C 作为目标语言。我们将针对其他编程语言的评估留作未来的工作。
2.2 模型
我们在图 2 中展示了所提出的 Codeeditor 模型的概述。Codeeditor 建立在编码器-解码器框架之上,该框架由基于 Transformer 的编码器和基于 Transformer 的解码器组成。许多条件生成任务,包括代码摘要和翻译,正在通过编码器-解码器模型来解决。我们使用预训练语言模型 CoditT5 初始化 Codeeditor 的参数。 CoditT5 在单一编程语言中的各种与软件相关的编辑任务上显示出了有希望的结果,但尽管如此,它仍将为我们提供一个“热启动”,为建模编辑带来必要的归纳偏差。为了适应多语言协同编辑任务,我们对 Codeeditor 模型进行了微调,探索两个关键组成部分:(i)输入模型的上下文; (ii) 模型的输出格式。为了鼓励我们的 Codeeditor 模型在其训练数据中利用多种编程语言的(同步)代码更改历史,我们为模型提供了来自三个来源的上下文,如图 2 所示:(i) 源编程语言的代码更改; (ii) 用目标编程语言编写的旧版本代码; (iii)源编程语言中的新版本代码。我们探索两种格式来表示生成的代码更改:(i)目标编程语言中的代码编辑; (ii) 元编辑序列,将代码编辑从源编程语言翻译为目标编程语言,然后是目标编程语言的代码编辑(这类似于 CoditT5 的输出格式)。在这两种情况下,我们都会将目标编程语言中生成的代码编辑应用到旧版本代码以获得新版本代码。

图2 Codeeditor模型概述
2.2.1 编辑表示
插入:我们不使用插入,因为它总是会在没有位置信息的情况下引入歧义。为了表示插入,我们首先找到唯一的锚标记,它们是编辑位置之前或之后的标记的最短跨度,并且在输入序列中是唯一的。然后我们使用 ReplaceKeepBefore 或 ReplaceKeepAfter,表示用插入的内容和锚标记替换锚标记。例如,在图 1 中,假设 Java 代码更改需要在第 7 行的assertEquals 语句之后添加一个空白 return 语句。标记范围“getMessage());”将作为锚标记的最小跨度,因为它在旧的 Java 代码序列中是唯一的,并且它发生在要执行的编辑之前。我们消除编辑序列的歧义:
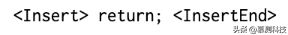
变成具有明确的编辑顺序:

此编辑序列表示“getMessage());”应替换为“getMessage());返回;”。我们引入 ReplaceKeep-Before,其中 <ReplaceOldKeepBefore> 后面的标记应删除并插入 <ReplaceNewKeepBefore> 之后的标记。与替换不同的是,要删除的标记和要插入的标记之间存在一些重叠。如果编辑位置之前不存在锚标记,我们将对编辑位置之后的标记使用 ReplaceKeepAfter。
替换:如果要替换的令牌跨度在旧序列中是唯一的,则常规替换序列就足够且具有确定性;在这种情况下我们将继续使用它。否则,不清楚应该替换哪个出现的令牌跨度。例如,在图 1 中,Java 代码更改是在第 6 行的assertEquals 语句中从 PdfException 更改为 LayoutExceptionMessageConstant。简明编辑序列中的替换是不明确的,因为在标记化后的旧 Java 代码序列。为了解决这个问题,与插入情况类似,我们在编辑位置之前或之后搜索可以在旧序列中形成唯一跨度的最小锚标记。例如,简洁的编辑顺序:

可以消除歧义为以下明确的编辑序列:

删除:与替换类似,如果要删除的标记跨度在旧序列中是唯一的,我们将继续使用删除,因为它是明确的。否则,它将转换为 ReplaceKeepBefore 或 ReplaceKeepAfter。例如,假设标记“PdfException”。应从图 1 中第 6 行的旧 Java 方法中删除。简洁的编辑序列:

将被转换为

此编辑序列指示“format(PdfException.”应替换为“format(”),明确暗示删除“PdfException.”。总而言之,明确的编辑序列包含 4 种类型的编辑:<Replace>、<Delete>、 <ReplaceKeepBefore>和<ReplaceKeepAfter>.简洁编辑序列和明确编辑序列之间的映射总结在表1中。给定明确编辑序列,我们可以将其应用于旧输入序列,以确定性地导出新的编辑序列。
2.2.2 模型输入
我们的目标是通过为模型提供代码演化信息(即源编程语言和目标编程语言的代码修订)来为多语言协同编辑任务构建高性能的机器学习模型。 Codeeditor 不是直接在编程语言之间翻译整个代码片段,而是翻译编程语言之间的代码更改。
为了鼓励模型了解开发人员跨编程语言所做的更改之间的一致性,我们为 Codeeditor 提供了源编程语言中的代码更改。为了保持编辑的精确性和简洁性,我们采用明确的编辑序列来表示代码更改。如图 2 所示,将 PdfException 替换为 LayoutExceptionMessageConstant 的 Java 代码更改的结构如下:

除了源编程语言中代码更改的学习表示之外,我们还为 Codeeditor 提供目标编程语言中的旧代码,以更好地帮助模型推断目标编程语言中的相关代码更改。直觉是,该模型将根据目标编程语言中方法的具体实现来推理如何传输和调整源编程语言中的编辑。此外,我们将源编程语言中的新代码附加为上下文之一。我们相信这将为模型提供更多背景来理解源编程语言中的编辑,并促进两种编程语言中更新方法的一致性。总而言之,我们结合了来自三个来源的历史相关上下文:源编程语言中的代码更改、目标编程语言中的旧代码和源编程语言中的新代码。我们将它们连接成一个由特殊 SEP 令牌分隔的序列作为模型输入。
2.2.3 模型输出
我们提出两种格式作为模型的目标输出,这导致了 Codeeditor 的两种模式:EditsTranslation 和 MetaEdits。两种模式都使用相同的输入,并且两种模式的目标输出都需要对目标编程语言进行一系列编辑。
编辑翻译: EditsTranslation 模式的输出是目标编程语言中明确的编辑序列,它建议应如何更改目标编程语言中的代码。请注意,模型生成的明确编辑序列可以被解析并确定性地应用于旧版本的代码。 EditsTranslation 本质上是学习将代码编辑从源编程语言翻译为基于代码历史上下文的目标编程语言。图 1 中的 C 示例的 EditsTranslation 模式的目标输出为:

元编辑:在此模式下,我们采用 CoditT5的输出格式进行多语言协同编辑,因为我们的模型是基于 CoditT5 构建的,它在软件编辑任务上表现出了良好的性能。CoditT5 经过预训练,可生成以下输出格式:“[Edit Plan] <SEP> [Target Sequence]”。编辑计划是一个简洁的编辑序列表示编辑输入序列的步骤;目标序列是应用正在进行的编辑计划后编辑的序列。我们为多语言协同编辑任务定制了这种格式;编辑计划表示源编程语言上的代码编辑之间的编辑和目标编程语言,我们称之为元编辑序列,最终的目标序列应该是目标编程语言上明确的编辑序列。对于图 1 中的示例,将 Java 编辑转换为 C 编辑的预期元编辑序列如下:
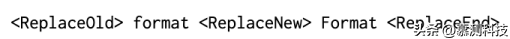
应用元编辑序列后的目标序列是:

2.3 数据集
这是第一个在多语言任务中考虑软件项目历史的工作;因此,我们还创建了一个新的数据集,其中包括编程语言之间对齐的代码更改。第一步,我们通过挖掘开源 Java 和 C 项目的历史来构建数据集。我们首先从 Java 和 C 项目的提交中收集更改的方法。然后,我们设计启发式方法,将这些更改与具有类似实现和功能的方法配对(即对齐)。我们在数据集上考虑两个方向:J2CS(基于 Java 更改更新 C 方法)和 CS2J(基于 C 更改更新 Java 方法)。在本节中,我们将描述用于收集数据、分割和预处理数据以及最终呈现数据集的统计数据的方法。
2.3.1 数据集构建
为了构建数据集,我们在方法级别提取对齐的 Java 和 C 代码更改作为元组(Java 旧方法;Java 新方法,C 旧方法;C 新方法)。代码更改是从 git 提交中挖掘的。我们考虑了表 2 中列出的 8 个开源项目,它们都有 Java 和 C 实现,并在之前的工作中使用过 。所有项目首先用Java开发,然后移植到C。为了收集成对的更改,我们首先根据方法签名、类名和定义方法的文件路径为项目中的每个方法(对于 Java 和 C 项目)分配一个唯一标识符。与 Lu 等人使用的策略类似。然后我们根据 Java 方法和 C 方法唯一标识符的相似性将它们配对。这种策略是有效的,因为移植的 C 项目与相应的 Java 项目具有非常相似的结构以及类和方法的命名规则。我们使用以下规则来提取对齐的代码更改:
(1) 对于每个 Java 方法更改,我们提取在 Java 更改发生后 90 天内发生的配对 C 方法中的代码更改,作为可能的匹配代码更改。我们使用提交日期作为更改时间。
(2) 为了过滤不相关的代码更改,我们计算 C 和 Java 添加和删除的行之间的 Jaccard 相似度。我们通过基于驼峰命名约定(例如,lastModified 为最后修改)对这些行进行子标记来进一步细化过滤,并仅针对添加和删除的标记计算 Jaccard 相似度。我们只保留标记级 Jaccard 相似度高于 0.4 且行级 Jaccard 相似度高于 0.5 的可能匹配代码更改。
(3)对于每个Java代码更改和C代码更改,如果存在多个可能匹配的代码更改,我们仅选择最相似的相应代码更改。
2.3.1 数据预处理和分割
对于 Java 和 C 方法,我们删除了内联自然语言注释,并使用 Antlr生成的特定于语言的词法分析器将方法标记为标记。我们设想机器学习模型的以下用例:每当开发人员对用源编程语言编写的项目进行更改时,开发人员将使用在现有历史对齐代码更改上训练的模型将该更改迁移到用源编程语言编写的项目中其他目标编程语言。为了评估此用例下的模型,按照先前工作的建议,我们使用时间分段方法将数据集分为训练集、验证集和测试集。也就是说,训练集的变化发生在验证集的变化之前,验证集的变化又发生在测试集的变化之前。更具体地说,对于每个 Java 和 C 代码更改对,我们首先收集 C 提交的时间,然后按时间顺序对代码更改对进行排序。然后,我们从每个项目中选择最旧的 70% 的代码更改对作为训练数据,接下来最旧的 10% 作为验证数据,其余的作为测试数据。为了更严格地评估模型的泛化能力,我们还在使用跨项目方法分割数据集时对其进行了评估,该方法在之前的机器学习模型代码工作中经常使用。具体来说,与验证和测试集中的代码更改相比,训练集中对齐的代码更改来自不同的项目。
3 实验
本文选择的baseline包括:Copy,CopyEdits,CodeT5-Translation,CodeT5-Update,CoditT5,Codex-few-shot,ChatGPT-zero-shot
评估指标方面,继之前的工作之后,使用评估代码生成质量的指标:BLEU 、CodeBLEU 、xMatch,以及评估软件编辑质量的指标:SARI 和 GLEU 。对于本文中报告的所有指标,它们的范围从 0 到 100,分数越高越好。
3.1 实验设置
我们围绕三个主要研究问题进行评估:
RQ1:在多语言协同编辑中使用代码更改历史记录有什么好处?RQ2:我们基于编辑的模型 Codeeditor 与基于生成的多语言协同编辑模型相比如何?RQ3:基于生成的模型如何补充Codeeditor模型以进一步提高性能?RQ1
根据模型是否有权访问代码更改历史信息,我们将模型分为两类:Copy 和 CodeT5Translation 是历史不可知的模型,其余的是历史感知的模型。总体而言,历史感知模型优于历史不可知模型。基于规则的模型 CopyEdits,直接将源编程语言( )中的代码更改应用于目标编程语言中的旧代码,无需任何调整,其性能与机器学习历史不可知模型CodeT5-Translation相当。这强调了多语言协同编辑中代码更改历史提供的上下文信息的重要性。有趣的是,我们发现在没有微调的few-shot学习设置下使用的Codex-few-shot在xMatch上比fine-tunedCodeT5-Translation表现更好,而比其他历史感知微调机器学习模型表现更差。这再次强调了代码更改历史记录的价值,并表明通过利用训练数据中更多的代码历史上下文进行微调将提供更好的性能。
RQ2
在所有历史感知模型中,机器学习模型(例如 CodeT5Update 和 CoditT5)比基于规则的 CopyEdits 实现了更高的性能,这表明机器学习模型有效地学习推理相关代码更改并将其调整为 目标编程语言。 我们观察到,Codeeditor(在 EditsTranslation 和 MetaEdits 模式下)经过训练,首先将源编程语言上的代码更改翻译为目标编程语言,然后将编辑应用到目标编程语言中的旧代码,在所有语言中实现更高的性能 比基于大型预训练生成模型(CodeT5-Update)的指标要好,后者直接从头开始以目标编程语言生成新代码。 这突出表明,经过训练通过预测编辑序列来显式执行编辑的模型比基于生成的模型更适合软件领域中的编辑任务。为了进一步研究 Codeeditor 相对于最佳基于生成的模型 (CodeT5-Update) 的优势,我们在 J2CS 测试数据中的每个示例上分解了 EditsTranslation 和 CodeT5-Update 的性能。
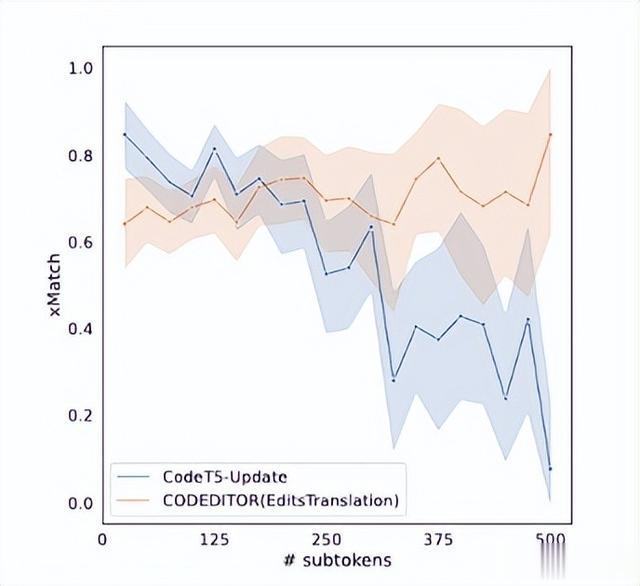
图3
在图 3 中,我们显示了 Codeeditor (EditsTranslation) 和 CodeT5-Update 的预测与输入旧代码中的子标记数量完全匹配的平均百分比。请注意,代码使用 Roberta 分词器进行子分词,所有机器学习模型都使用该分词器。我们在此图中排除了具有超过 500 个子标记的示例,因为这些异常值仅占测试数据的不到 5%。我们可以看到,CodeT5-Update的性能随着待编辑代码中子标记数量的增加而急剧下降,但EditsTranslation的性能相当稳定。这说明了 Codeeditor 在准确处理较长输入方面的另一个优势,因为它专注于转换编辑而不是像 CodeT5-Update 那样生成整个新代码。同时,大多数现有的基于 Transformer 的模型对输入序列都有长度限制,因为朴素自注意力对于输入长度具有二次复杂度。

图4
在图 4 中,我们展示了 J2CS 测试数据上 Codeeditor (EditsTranslation) 和 CodeT5-Update 的模型目标输出中子标记数量的分布。 出于与上一段所述的相同原因,我们仅显示少于 500 个子代币的目标输出的分布。 大多数 Codeeditor 的目标输出(编辑操作的序列)都比 CodeT5-Update 的输出(目标编程语言的新代码)短。 这也许可以解释为什么 Codeeditor 在较长的代码上比基于生成的模型获得更好的性能,因为生成较长的序列通常对机器学习模型更具挑战性。 最近的研究侧重于探索解决模型输入上下文窗口大小限制的方法。 未来的研究应该检查翻译编辑序列和使用能够处理更长上下文的模型生成全新代码之间的性能差异。
RQ3
为了利用基于生成的模型在短代码片段上的优越性,我们根据代码片段的大小将最强的生成模型 CodeT5Update 与最强的 Codeeditor 模式 EditsTranslation 结合起来。具体来说,如果要更新的代码的子标记少于阈值,我们使用 CodeT5Update,否则使用 Codeeditor (EditsTranslation)。为了选择组合两个模型的阈值,我们对验证集进行了网格搜索,并选择了给出最佳 xMatch 分数的模型。我们将组合模型称为混合模型,通过将基于生成的模型与 Codeeditor 相结合,我们可以在大多数报告的自动指标上实现改进的性能。
转述:尚也
