An Empirical Study on Usage of Transformer Models for Code Completion
Matteo Ciniselli, Nathan Cooper, Luca Pascarella , Antonio Mastropaolo, Emad Aghajani, Denys Poshyvanyk, Massimiliano Di Penta, and Gabriele Bavota
引用
Matteo Ciniselli, Nathan Cooper, Luca Pascarella , Antonio Mastropaolo, Emad Aghajani, Denys Poshyvanyk, Massimiliano Di Penta, and Gabriele Bavota. 2021. An Empirical Study on Usage of Transformer Models for Code Completion. IEEE Transactions on Software Engineering PP(99):1-1, November, 2021. https://ieeexplore.ieee.org/document/9616462/
论文:https://ieeexplore.ieee.org/document/9616462/
仓库:https://github.com/mciniselli/T5_Replication_Package
摘要
本文提出了一项大规模研究,探讨了最先进的基于Transformer模型的代码补全在支持不同粒度级别的代码补全方面的能力。我们尝试了两种最近提出的Transformer-based模型的几种变体,即RoBERTa和Text-To-Text Transfer Transformer(T5)用于代码补全任务。实现的结果表明,基于Transformer模型,特别是T5,可以作为代码补全的可行解决方案,其完美预测的范围从约29%到约69%不等。
1 引言
自动代码补全被认为是现代集成开发环境(IDEs)中“杀手级”功能之一,它可以根据IDE中已经编写的代码为开发人员提供关于下一个代码标记的预测,从而加快软件开发速度并防止潜在错误。尽管随着时间的推移,代码补全技术的性能显著提高,但它们为开发人员提供的支持类型并未以同样的速度发展。事实上,除了一些专注于预测多个代码标记甚至推荐整个语句的研究外,文献中提出的大多数方法仅在特定场景中进行了实验,即必须预测开发人员可能键入的下一个标记。这留下了一个问题部分未解:基于深度学习的标记预测能走多远?
在本文中,我们展示了一项大规模的实证研究,探索了最先进的深度学习模型支持代码补全的极限和能力。除了生成开发人员可能编写的下一个标记外,我们还应用深度学习模型生成整个语句和代码块。在文献提出的诸多深度学习模型中,我们专注于使用基于Transformer架构的模型。我们专注于三种代码预测场景:(i) 标记级别的预测,即经典的代码补全,其中模型用于猜测开发人员开始编写的语句中的最后n个标记;(ii) 构造级别的预测,其中模型用于预测特定的代码构造(例如,if语句的条件),这对开发人员在编写代码时特别有用;(iii) 块级别的预测,其中掩码代码跨越一个或多个组成代码块的整个语句(例如,for循环的迭代块)。
在研究中我们比较了一些模型的性能,包括代表BERT类的RoBERTa模型和T5模型等。我们希望通过观察预训练任务和跨不同任务的迁移学习对两个基于Transformer的模型性能所起的作用进行调查。这需要训练许多不同变体的实验模型,我们采用以下策略。首先,我们通过为实验的三种代码补全场景(标记级别、构造级别和块级别)训练三种不同的模型来比较RoBERTa和T5。然后,我们选择表现最佳的模型T5,并展示使用预训练如何提高其性能。最后,我们展示通过微调单个T5模型可以使所有的三个预测任务提升性能,从而确认在三个非常相似的任务之间能够进行迁移学习。
实现的结果表明,在典型的代码补全任务(即,标记级别)中,T5在66%至69%的情况下正确猜测所有掩码标记,而RoBERTa实现39%至52%,n-gram模型实现42%至44%。在最具挑战性的预测场景即掩码整个代码块时,RoBERTa和n-gram模型显示出其局限性,只能在不到12%的情况下正确重建掩码块,而T5则实现30%的正确预测。
值得注意的是,我们研究的目标并不是要证明T5模型是神经代码补全的最佳选择。我们的工作侧重于通过实证方法探索基于深度学习的模型在代码补全技术方面的能力,其中T5、RoBERTa和n-gram模型被选为最先进技术的代表。
总的来说,本文的贡献如下:
我们进行了一项全面的实证研究,引入了另一种最先进方法,即T5模型,展示了其在代码补全任务中非常有前景的表现。在先前发表的论文中,我们对三种不同的RoBERTa模型进行了微调,分别针对三种代码补全场景(即,标记级别、构造级别和块级别),没有进行预训练,也没有测试迁移学习的影响。而在本文中,我们对表现最佳的模型T5进行了预训练和微调,以研究这些方面。对于表现最佳的模型T5,我们还探讨了利用预测的置信度作为预测质量度量的可行性,展示了这种指标的可靠性。我们工作中使用的源代码和数据已经公开在一个完整的复制包中。2 技术介绍
在实证研究中我们使用了三种实验技术,分别是RoBERTa,T5和n-gram。这一部分将在参考其原始论文的基础上对这些技术进行详细阐述。
2.1 RoBERTa
RoBERTa模型基于Encoder-Transformer架构,我们探究的重点是为什么它能作为代码补全的一个合适选择。
基于BERT的模型,如RoBERTa,使用一种特殊的预训练,其中输入句子中的随机单词被用特殊的标记掩盖。这种预训练任务非常适合模拟代码补全任务,在这个任务中,输入是开发人员正在编写的不完整代码片段,而掩盖的标记代表了需要自动补全片段的代码。然而,由于Transformer的固定序列长度,这种预训练的一个局限性是,在尝试预测多个标记时需要知道生成的标记数量。为了克服这个问题,我们通过使用单个标记掩盖标记范围来修改这样的目标。正如前面解释的,BERT模型(如RoBERTa)可以在多个任务上进行预训练和微调。结果将是一个单一模型能够支持不同任务,并且可能利用为特定任务学到的知识来提高在不同任务中的表现。
我们使用了Python transformers库作为RoBERTa模型的实现。我们还为每个模型训练了一个分词器,以解决词汇表外问题。当机器学习模型处理训练集中未包含但出现在测试集中的术语时,就会出现词汇表外问题。我们使用HuggingFace的tokenizers Python库训练了一个Byte Pair Encoding(BPE)模型。BPE使用字节作为词汇表,使其能够对每个文本进行标记化,而无需在NLP的DL应用中经常使用的未知标记,从而解决了词汇表外问题。在源代码上使用BPE已被证明可以解决词汇表外问题。
2.2 T5
T5模型由Raffel等人提出,该模型利用多任务学习在自然语言处理领域实现迁移学习。T5呈现出五种预定义的变体:small、base、large、3 Billion和11 Billion,这些变体在复杂性、大小和训练时间上有所不同。T5 small是较小的变体,有6000万个参数,而T5 11B是最大的变体,有110亿个参数。尽管Raffel等人的报告强调最大的模型提供了最佳准确性,但其训练时间有时过高,难以证明其使用的合理性。鉴于我们的计算资源,我们选择了T5 small模型。因此,我们期望实验结果得到基于T5模型性能的下限。
与其他深度学习模型相比,T5具有两个优势:(i)它通常比循环神经网络更高效,因为它允许并行计算输出层;(ii)它可以检测标记之间的隐藏和长距离依赖关系,而不假设最近的标记比远处的标记更相关。后者在与代码相关的任务中尤为重要。例如,一个局部变量可以在方法的开头(第一条语句)声明,在if语句内部的主体中使用,并最终在最后一个方法语句中返回。捕捉存在于这三个语句之间的依赖关系,即使它们可能相距很远(例如,变量声明和返回语句),可以帮助更好地对源代码进行建模,从而提高支持与编码相关任务的性能序。
2.2 n-gram
作为比较基准,我们使用了基于n-gram的统计语言模型,一个n-gram模型可以预测在其前n-1个标记后面的单个标记。尽管n-gram模型更专注于预测给定n-1个前导标记的情况下的单个标记,但是我们设计了一个公平的比较场景以应对遮蔽多个标记的情况。具体而言,我们以以下方式使用n-gram模型:假设我们正在使用一个3-gram模型来预测如何完成一个具有五个标记T的语句,其中最后两个标记被屏蔽(M):<T1, T2, T3, M4, M5>,其中M4 和M5分别屏蔽了T4和T5。我们将T2和T3提供给模型作为输入,以预测M4,得到模型的预测P4。然后,我们使用T3和T4来预测M5,从而获得预测的句子<T1, T2, T3, M4, M5>。基本上,所有预测都被连接起来以预测多个连续标记。
这些n-gram模型是在用于深度学习模型微调的相同训练集上进行训练的,没有屏蔽标记。实验中我们尝试了标准的n-gram模型(即上述讨论的模型),以及Hellendoorn和Devanbu提出的n-gram缓存模型。
3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下问题:
RQ 1:Transformer模型在学习如何自动完成代码方面到底有多可行?
RQ 1.1:掩码标记数量对预测质量的影响程度如何?
RQ 1.2:模型的性能在多大程度上受到用于训练和测试的数据集的特异性的影响?
RQ 2:预训练和迁移学习在Transformer模型的性能中扮演什么角色?
RQ 3:Transformer模型与最先进的n-gram模型相比如何?
评估数据集。我们的研究涉及两个数据集。第一个数据集来自我们的MSR'21论文,其中包括Java和Android数据集,用于微调RoBERTa和T5模型以及训练n-gram模型,我们将这个数据集称为微调数据集。第二个数据集是用于回答RQ2问题而专门构建的,可以用来对RoBERTa和T5中表现最佳的模型进行预训练(即预训练数据集)。为构建预训练数据集,我们使用了GitHub搜索平台来识别所有具有至少100次提交、10个贡献者和10个星标的Java存储库,并基于一些条件进行筛查。
模型训练过程:
RoBERTa。我们在一台装有Nvidia RTX Titan GPU的Linux服务器上使用Weights & Biases的Python库进行了超参数调整。表1报告了我们调整的超参数、我们为它们测试的值范围以及我们找到的最佳配置中的值。除了这些参数,我们使用了注意力丢弃概率为0.1,隐藏层丢弃概率为0.3。对于分词器,词汇表大小设置为50k。超参数搜索是使用Android数据集的训练集和评估集进行的,其中进行了标记掩码。我们选择了在评估集上应用时能够获得最多“完美预测”的最佳配置。我们定义“完美”预测为完全匹配开发人员编写的代码的预测。因此,模型正确猜测所有掩码标记。如果其中一个掩码标记不同,我们不认为该预测是“完美”的。虽然原则上,每个数据集都需要进行不同的超参数调整,但这样的过程非常昂贵,我们在其他数据集的子集上进行的初步调查显示在实现的最佳配置中存在较小差异。
表1:RoBERTa模型的超参数调整。

T5。我们依赖于Mastropaolo等人使用的相同配置。特别是,在预训练方面,我们不调整T5模型的超参数,因为预训练步骤是与任务无关的,这样做将提供有限的好处。相反,我们尝试了四种不同的学习率调度用于微调阶段,使用表3中报告的配置,并确定在评估集上表现最佳的配置。在评估集的所有六个数据集(表2),表现最佳的配置是使用Slanted Triangular学习率的配置,这证实了中的发现。此外,我们构建的所有T5模型都使用在预训练数据集上训练的SentencePiece 分词器,并由32k个词片段组成。
表2:研究数据集,一个实例对应一个具有掩码标记的方法。

我们确定的最佳配置已用于训练六个不同的T5模型,并评估它们在相应的测试集上的性能。这些结果可用于直接比较T5和RoBERTa模型在无预训练和单任务设置(即无迁移学习)下的微调情况。由于我们发现T5的表现优于RoBERTa,我们还使用该模型来回答RQ 2。因此,除了这六个模型外,我们还构建了另外七个模型:其中六个利用预训练加单任务微调。为了对T5模型进行预训练,我们在每个预训练数据集实例(方法)中随机屏蔽15%的标记。对于学习率,我们使用了具有规范配置的Inverse Square Root。训练需要大约26秒进行100步。最后,我们利用了预训练和多任务微调创建了一个T5模型。
表3:T5模型的超参数调整。
RQ1 基于深度学习模型的性能比较
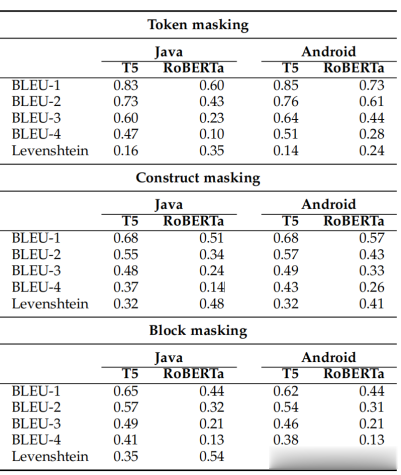
实验设计。为了回答RQ 1,我们通过在表2中的测试集上运行每个训练模型来计算总结在表4中的指标。第一个指标是双语评估指标(BLEU)-n分数,用于评估自动生成文本的质量。第二个指标是莱文斯坦距离,这可以定义为将预测代码转换为参考代码所需的最小标记编辑次数(插入、删除或替换)。由于这样的度量没有被归一化,很难在我们的情况下解释它。事实上,说出需要更改五个标记才能获得参考代码,如果不知道参考代码中的标记数量,这样的信息并不充分。因此,我们通过将该值除以预测代码和参考代码中最长序列的标记数量来对该值进行归一化。第三个指标是完美预测的百分比,其告诉我们实验模型能够推荐与目标代码中被屏蔽的标记序列完全相同的情况。
我们使用不同的统计分析比较RoBERTa和T5取得的结果。我们假设显著性水平为95%。如下所述,我们对比RoBERTa和T5的结果使用了比例检验和非参数检验。每当分析需要运行多个测试实例时,我们使用Benjamini-Hochberg程序调整p值。
为了(两两)比较RoBERTa和T5的完美预测结果,我们使用McNemar's检验。为了计算检验结果,我们创建一个混淆矩阵计算不同情况数量。最后,我们用Odds Ratio(OR)效应大小来补充McNemar's检验。
表4:研究中使用的评估指标。

针对RQ 1.2,我们通过比例检验来比较不同数据集之间的结果,但这次分析是不配对的,因此我们使用Fischer's exact检验(以及相关的OR)在一个矩阵上进行分析,该矩阵包含了不同方法和不同掩码级别在Java和Android上实现的正确和错误预测的数量。为了比较T5和RoBERTa在BLEU-n分数和Levenshtein距离方面的结果,我们使用Wilcoxon符号秩检验和配对Cliff's delta效应大小。同样,为了比较不同数据集在BLEU-n分数和Levenshtein距离方面的结果,由于是不配对的,我们使用Wilcoxon秩和检验和不配对Cliff's delta效应大小。
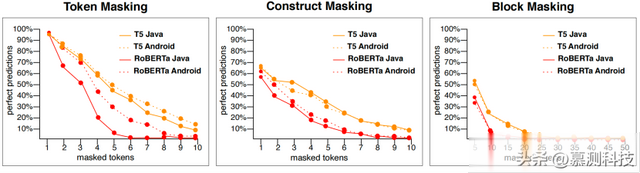
图1 T5和RoBERTa实现完美预测的百分比
结果。受屏蔽标记数量的影响(RQ 1.1)和数据集的特异性(RQ 1.2)从图1的分析中立即得出三个发现:(i)如预期,屏蔽标记数量越高,模型的性能越低;(ii)在更具体的数据集(即Android,图1中虚线)上取得的结果与仅针对Java的RoBERTa模型在标记屏蔽场景中取得的结果相比要好得多;(iii)T5模型(图1中的橙色线)在RoBERTa模型之上表现出色。此外,当屏蔽标记数量增加时,RoBERTa的性能下降比T5更为稳定。
观察表5,BLEU分数和Levenshtein距离证实了对完美预测所观察到的情况:Android数据集的性能优于Java数据集。根据Wilcoxon秩和检验,除了在块级别的RoBERTa之外,所有差异在统计上都是显著的,但具有可忽略/较小的Cliff's d(详细的统计结果在在线附录中)。构造掩码。在这种情况下(见图1中央子图),当为两个数据集的单个标记进行掩码时,T5和RoBERTa分别达到了65%以上和55%以上的完美预测。
分析。图1的左侧显示,如预期,屏蔽标记数量越少,完美预测的几率越高。毫不奇怪,当我们只屏蔽语句中的最后一个标记时,模型非常有效。因此,模型很容易猜到最后一个标记。至于数据集,两个模型在Android数据集上表现出明显更好的性能(Fisher检验p值<0.001和OR<1),这是一个更具特异性,因此在源代码中更容易受到规律性影响的数据集。然而,对于RoBERTa模型,Java数据集和Android数据集之间的完美预测差距更为显著(例如,在x = 5时约为20%,而T5为约6%)。
就BLEU分数和Levenshtein距离而言,与标记级别掩码相比,实现的值更差,这证实了构造级别掩码所代表的更具挑战性的预测场景。T5模型报告的具有完美预测的最大掩码块由Android数据集的36个标记和Java数据集的39个标记组成,而RoBERTa模型实现的为13个标记和15个标记。在这个水平上,Java和Android之间的性能差异并不明显,对于T5来说甚至是微不足道的。
对于研究问题1.1的回答:随着被屏蔽标记的数量增加,基于深度学习的模型生成正确预测变得更加困难。然而,T5模型取得的性能看起来很有前途,并且正如我们将在后面讨论的那样,可以通过适当的预训练和多任务微调进一步提升。
对于研究问题1.2的回答:当考虑最佳模型(即T5)时,其在两个数据集上的表现非常相似,没有观察到明显的主要差异。只有在RoBERTa模型的标记屏蔽场景中才观察到性能上的显著差异。
表4:T5和RoBERTa的BLEU分数和Levenshtein距离。
RQ2 预训练和迁移学习的影响
实验设计。我们训练了七个额外的T5模型,以评估预训练和迁移学习对其性能的影响。首先,我们为之前讨论过T5性能的六个模型(即无预训练,单任务)添加了预训练阶段(在单任务场景中获得预训练模型,即无迁移学习)。然后,我们将预训练模型,在多任务设置中进行微调,研究迁移学习的影响。
表5:T5模型采用不同微调策略以及RoBERTa模型的完美预测结果。

结果。表5显示了实现的结果,同时报告了之前讨论过的T5和RoBERTa模型的性能。结果显示,预训练在所有情况下都具有积极的(OR> 1)并且具有统计学意义的影响,而在多任务设置中进行微调优于单任务预训练。从表5可以看出,预训练对T5的准确性产生了积极影响,将完美预测的百分比从1%提高到4.7%,具体取决于测试数据集。预训练的好处在最具挑战性的块级别场景中更为明显(∼5%)。总体而言,当将所有测试数据集作为一个整体考虑时,完美预测的百分比从54.1%增加到56.2%(+2.1%)。通过在六个训练数据集上训练单个模型,完美预测的百分比进一步增加,总体达到59.3%。请注意,所有测试数据集上都可以观察到改进,对于标记屏蔽场景,改进可以达到∼5%。性能改进也得到了通过BLEU分数和Levenshtein距离实现的结果的确认。
分析。对于RQ 2的回答:我们发现预训练和多任务微调对T5的性能都有积极影响。总体而言,这种改进在完美预测方面增加了+5.2%(正确预测了36,009个额外实例)。
RQ3 对比Transformer模型与n-gram模型
实验设计。对于所有数据集,我们将DL模型的性能与ngram模型进行比较。特别是,我们进行了第一次大规模比较,使用标准的n-gram语言模型,并在一个较小的数据集上,我们还将实验技术与最先进的缓存n-gram模型进行比较,使用了作者提供的实现。我们稍后详细说明为什么缓存n-gram模型在整个数据集上运行成本太高。
我们尝试设计一个公平的比较,尽管ngram模型旨在预测给定其前面的n个标记的单个标记。因此,在我们屏蔽多个标记的情况下,我们以以下方式使用n-gram模型:我们运行它以独立预测每个被屏蔽的标记。然后,我们汇总所有预测以生成最终字符串(即,先前被屏蔽的标记集)。n-gram模型是在用于DL模型微调的相同训练集上训练的,但是没有被屏蔽的标记。我们比较这三种方法在测试集上生成的完美预测。使用McNemar's检验和OR进行统计比较。
结果。我们通过比较没有预训练和单任务设置下的深度学习模型与n-gram模型来回答RQ 3。我们选择进行这种比较是为了公平起见,因为这样n-gram模型已经在与两个深度学习模型完全相同的数据集上进行了训练。表6报告了实现的结果。
表6:与基于深度学习模型相比,n-gram模型在提供克隆存储库(WC)和不提供克隆(NC)时的完美预测率。

分析。如预期的那样,n-gram模型的性能得到提高,这要归功于在测试项目中使用信息。在这些相同实例中,T5和RoBERTa模型的性能始终优越,但在Java标记和块掩码的情况下,RoBERTa的性能略胜一筹。
回答RQ 3:n-gram模型是RoBERTa的一个有竞争力的替代方案,而T5证实了其卓越的性能。值得强调的是,与基于DL的方法相比,训练(可能需要多次重新训练)n-gram模型的成本要低得多。
转述:刘佳凯