摘要: 每月两次,每次数天,面对着上百个Excel表的数据处理任务,重复、枯燥、耗时,崩溃。直到他发现了Python自动化办公的奥秘...
引言在数据分析的世界里,小李是一名普通的数据分析师。每个月,他都要面对一项艰巨的任务:从上千个Excel表中提取特定的数据,汇总到一个新的工作簿中。传统的方法,需要他逐个打开Excel表,按列筛选,复制粘贴,耗时耗力,而且极易出错。初步估计,完成一个表格需要5分钟,上千个表格就是5000分钟的工作量。这项工作不仅重复性高,而且枯燥无味,让小李对工作失去了热情和热爱。
1.小李的苦恼小李在后台留言说:“每个月,我都要花费数天的时间来完成这项重复性的工作。每次筛选、复制、粘贴,都是对我的耐心和精力的巨大考验。”
2.传统方法的局限性小李的工作流程是这样的:
打开每个Excel文件,逐个查找需要的数据。筛选出老板需要的数据列。复制并粘贴到新的工作表中。保存并关闭每个文件。这个过程不仅耗时,而且容易出错。每一次的筛选都可能遗漏数据,每一次的复制粘贴都可能引入错误。
3.Python自动化的解决方案小李关注了我们的公众号,并在后台留言了自己的问题。我们为他提供了一个Python自动化脚本,能够批量处理文件夹下所有Excel文件,提取特定数据到新的工作簿中。
import osimport xlwings as xwimport pandas as pddef extract_data(folder_path, dst, name): if not os.path.exists(folder_path): print('文件夹路径不正确,请检查') return # 启动Excel应用,不显示界面 app = xw.App(visible=False, add_book=False) try: files = [os.path.join(folder_path, f) for f in os.listdir( folder_path) if f.endswith('.xlsx')] data = [] for file in files: workbook = app.books.open(file) for sheet in workbook.sheets: values = sheet.range('A1').expand().options(pd.DataFrame).value filtered = values[values['部门'] == name]##此处的条件可以自定义任意多个 if not filtered.empty: data.append(filtered) workbook.close() if data: new_workbook = app.books.add() new_worksheet = new_workbook.sheets.add(name) new_worksheet.range('A1').value = pd.concat( data, ignore_index=True) new_workbook.save(dst) new_workbook.close() else: print(f"未找到名称为{name}的数据") except Exception as e: print(f"错误信息: {e}") finally: app.quit()# 使用示例folder_path = '年假_按部门'dst = './汇总数据.xlsx'name = '工程部'extract_data(folder_path, dst, name)4.效果展示通过上述脚本,小李可以一键提取上百个Excel表中的特定数据,汇总到一个新工作簿中。整个过程只需几秒钟,准确无误,大大提升了工作效率,同时也让小李重新找回了对工作的热情。
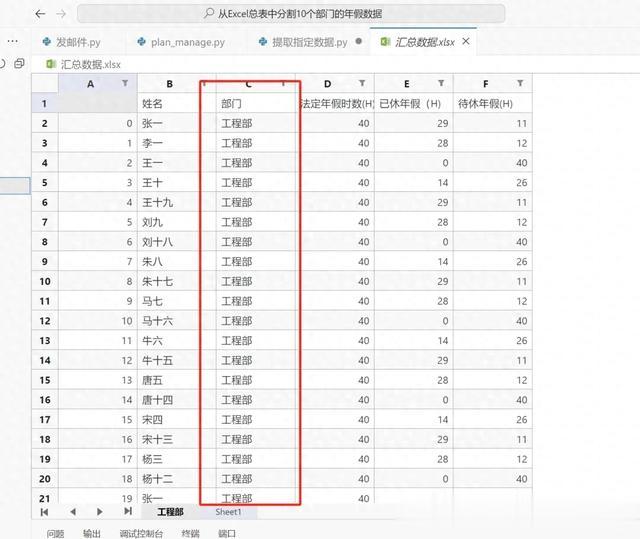 结语
结语Python自动化不仅仅是一种技术,更是一种工作方式的革新。它能够帮助我们从重复性劳动中解放出来,让我们有更多时间去做更有创造性的工作。希望小李的故事能够激励更多的人,去探索和利用Python自动化办公的无限可能。
如果你也像小李一样,面临着重复性工作的苦恼,或者对Python脚本的编写有任何疑问,欢迎在评论区留言,我们将为你提供一对一的技术支持!

数海丹心
大数据和人工智能知识分享与应用
132篇原创内容
公众号
评论列表