2022 年底,ChatGPT 的出现如一声惊雷划破天际,预示着行业变革的风暴即将来临,万亿市场的潜力被瞬间激活。在这个波澜壮阔的舞台上,无数玩家纷纷涌入,他们或带着前瞻的视野,或揣着创新的火种,或凭借雄厚的资本,或依仗深厚的技术底蕴,共同编织着这场市场盛宴的华丽篇章。
有的玩家是行业的先行者,他们凭借敏锐的市场洞察力和果敢的决策,率先布局,抢占先机,成为引领潮流的先锋;有的则是后来居上的挑战者,他们不甘人后,以更加灵活的身姿和独特的策略,在市场中寻找突破口,不断向领导者发起冲击。
在这个万亿市场中,竞争与合作并存,挑战与机遇共生。每一位玩家都在奋力拼搏,力求在这场没有硝烟的战争中脱颖而出。两年来,市场经过重重洗礼,多少玩家因无法适应市场的快速变化而黯然离场,而又有哪些玩家能够凭借其强大的实力和持续的创新精神,继续在这片沃土上耕耘呢?
运营商中国电信中国电信的智算基础研发布局,主要从芯片硬件、软件生态、互联能力、管理调度四个层面出发。
中国电信在互联能力层的打造以AIDC为核心进行组网,综合固移融合的入算网络、多机互联的算内网络、IP/传输的算间网络等能力,形成大规模、高效、无损、灵活的高性能智算网络,提升集群算力性能,破解算力供给发展难题,助力打造云网融合3.0新型算力基础设施。
入算网络方面,中国电信推出具有“泛在接入、随建随用、算网协同、安全可信”特性的“超算快线”产品,提供海量数据异属、异构、异域“入算”的统一解决方案。算内网络方面,中国电信开展新型RDMA拥塞控制技术创新,自研算法通过端侧主动探测感知网络拥塞进行精细化流控,有效提高收敛速度、控制交换机队列长度、降低小流延迟以及在NO-PFC/NO-ECN配置下避免丢包保证网络稳定性。算间网络方面,中国电信针对智算资源整合及分布式训练需求,可通过长距RDMA等新技术将百公里距离的多个智算中心并联成虚拟的大型智算中心节点,目前已经完成系列技术验证证明该技术方向可行。此外,在智算网络的建设上,天翼云成功打造了具备400G高速传输能力的弹性无损智能计算广域网络,大幅降低了算力池间的平均时延至9.7毫秒,同时无损网络的总体容量也达到了600T。
中国移动2023年,中国移动提出全调度以太技术体系(GSE),构建无阻塞、高带宽、超低时延的新型智算中心网络,对标国际主流的IB和UEC方案,形成中国自主的技术体系。2023年9月,发布了业界首款GSE原型系统。今年将开展GSE中试,加速GSE关键技术和产业成熟。
GSE技术是智算网络技术演进的方向,它通过从局部决策到全局调度、从流分发到报文分发、从盲发加被动控制到感知加主动控制的转变,实现了高精度负载均衡、网络层原生无损及低延迟。GSE技术体系能够最大限度兼容以太网生态,从四层(物理层、链路层、网络层、传输层)+一体(管理和运维体系)等几个层级进行优化和增强,构建无阻塞、高带宽、低时延的新型智算中心网络,形成标准开放的技术体系,助力AI产业发展。
2024年4月,中国移动发布《新型智算中心以太网物理层安全(PHYSec)架构白皮书》,白皮书中提出了以太网物理层安全(PHYSec)体系架构及技术方案,解决RDMASec、MACSec等现有安全方案在智算中心场景下面临的安全漏洞与性能瓶颈问题,为智算中心的网络保驾护航。
中国联通在AI时代,想要有效地训练庞大的模型,并充分发挥它们的潜力,不仅需要持续的算法创新,更重要的是需要强大且可靠的算力支持。对于庞大的计算资源,如何高效地管理和利用这些资源,仍是摆在面前的一个重大挑战。
联通新一代智算中心网络管控运维技术体系如图所示智驭-高性能智算中心网络管控运维平台,是专为智算中心高性能网络管控运维设计的创新解决方案。该平台采用异构分布式计算框架,提供数据驱动的全方位、一体化的智算中心网络的自动化智能化的管控运维能力。该平台具备超大规模集群管理、端网一体化管理、精细化数据采集、超可视化监控、自动化运维和智能协同调优六方面能力。

针对智算中心网络管控运维面临的超多配置、超细粒度、超大规模、超智控制四大挑战,通过全面化监测、自动化运维、智能化分析、体系化管理和预防性维护的相关能力,共同构成了平台适应当下需求的高效管控运维体系。
芯片厂商英伟达英伟达Spectrum-X 是专为提高基于以太网的 AI 云性能和效率而设计的以太网平台。这项突破性技术可将 AI 网络性能提升至 1.6 倍,并在多租户环境中实现一致且可预期的性能。Spectrum-X 依托于英伟达 Spectrum-4 以太网交换机和英伟达 BlueField-3 SuperNIC 的紧密耦合所支持的网络创新而构建。Spectrum-X 网络优化可缩短基于 Transformer 的大规模生成式 AI 模型的运行时间,并加快获得见解的速度。
Spectrum-4 交换机可和 BlueField-3 SuperNIC 紧密协作,组成一个 NCCL 优化的网络架构,从而利用一套端到端创新技术来优化 AI 集群性能。RoCE 动态路由使得大型 AI 流远离拥塞点,从而避免发生拥塞。这种方法提高了网络资源的利用率、叶/脊节点的效率和性能。Spectrum-4 交换机采用细颗粒度负载均衡,重新路由等技术以消除拥塞。
在Computex 2024上,英伟达宣布推出Blackwell的继任者——Rubin GPU架构。Rubin GPU将于2026年问世,支持8-Hi HBM4堆栈U。会上,英伟达还展示了ConnectX-8时代的51.2T Spectrum-X800 Ultra,并制定了ConnectX-9 NIC和1.6Tbps网络时代的102.4T交换机路线图。
 英特尔
英特尔2023 年 12月,英特尔推出了AI芯片 Gaudi3 以及第五代 Xeon 处理器。Gaudi3 是专为深度学习和创建大规模生成人工智能模型而设计的下一代人工智能加速器。英特尔声称Xeon 是唯一内置 AI 加速的主流数据中心处理器,全新第五代 Xeon 在多达 200 亿个参数的模型上提供高达 42% 的推理和微调能力。它也是唯一一款具有一致且不断改进的 MLPerf 训练和推理基准测试结果的 CPU。

Xeon的内置人工智能加速器,加上优化的软件和增强的遥测功能,可以为通信服务提供商、内容交付网络和包括零售、医疗保健和制造在内的广泛垂直市场实现更易于管理、更高效的高要求网络和边缘工作负载部署。
博通针对 AI 网络需求,目前博通推出了 Tomahawk 5 和 Jericho3-AI 芯片, 分别提供端点调度和交换机调度策略。
Jericho3-AI 专为 AI 训练负载优化设计,拓展性强。单个交换芯片可支持18 个 800G 端口或 36 个 400G 端口或 72 个 200G 端口连接。拓展性强,可以实现 32000 个连接速率为 800Gbps 的 GPU 集群连接,实现 26 PB 的总交 换带宽。Tomahawk 5 是市场上首个实现量产 51.2Tbps 交换带宽的交换芯片,2022 年推出,可提供 64 个 800G 端口或 128 个 400G 端口或 256 个 200G 端口, 能够满足 AI/ML 训练集群对于高带宽、低作业完成时间的要求。
2024 年 3 月 ,博通宣布交付业界首款 51.2T Bailly CPO 以太网交换机。Bailly 将 8 个硅光子学 6.4-Tbit/s 光引擎与 StrataXGS Tomahawk5交换芯片集成在一起,与可插拔收发器相比,功耗降低了 70%,硅面积效率提高了 8 倍。同月,博通在AI投资者大会上展示了他们参与设计的新款XPU芯片。从图中可以看出,除了中间两个大大的计算单元外,左右两边都是HBM内存,一共有12块,这已经到了目前台积电CoWoS-S封装的极限,由此可以看出,使用该芯片的厂商追求极高的AI性能,很有可能是微软、Meta之类的大型云服务厂商。
 AMD
AMD2023 年 12 月,AMD发布了MI300 系列芯片和Instinct MI300A加速处理单元(APU)。MI300X 为云提供商和企业设计,专为生成式 AI 应用而打造,MI300X GPU 拥有超过 1500 亿个晶体管,峰值内存带宽达到 5.3 TB/s。AMD Instinct MI300A APU 配备 128GB HBM3 内存。据称,与之前的 M250X 处理器相比,MI300A 在 HPC 和 AI 工作负载上的每瓦性能提高了 1.9 倍。
2024年6月,AMD董事长兼CEO苏姿丰在Computex 2024展会上公布了全新云端AI加速芯片路线图。根据路线图显示,AMD今年将会推出全新的AI加速芯片Instinct MI325X,2025年推出MI350,2026年推出MI400。

据介绍,MI325X将延续CDNA3构架,采用第四代高带宽内存(HBM) HBM3E,容量大幅提升至288GB,内存带宽也将提升至6TB/s,整体的性能将进一步提升,其他方面的规格则基本保持与MI300X一致,便于客户的产品升级过渡。另外,AMD还将在2025年推出新一代的MI350系列,该系列芯片将采用3nm制程,基于全新的构架,集成288GB HBM3E内存,并支持FP4/FP6数据格式,推理运算速度较现有MI300系列芯片快35倍。
Marvell2023年3月,Marvell推出了用于 800 Gb/秒交换机的 51.2 T性能的 Teralynx 10交换芯片。据Marvell介绍,Teralynx 10 是更大、更胖(fat)的交换机 ASIC,是一款专为 800GbE 时代设计的 51.2T 可编程 5nm交换机芯片,旨在解决运营商带宽爆炸的问题,同时满足严格的功耗和成本要求。它可适用于下一代数据中心网络中的 leaf 和 spine 应用,以及 AI / ML 和HPC 结构。

Teralynx 10 具有 512 长距离 (LR) 112G SerDes。提供全面的数据中心功能集,包括 IP 转发、隧道、丰富的 QoS 和强大的 RDMA。它还提供可变的灵活转发,使运营商能够随着网络需求的发展对新的数据包转发协议进行编程,而不会影响吞吐量、延迟或功耗。
Teralynx 10采用了超低延迟结构,兼容 Teralynx 软件,而且还支持 Teralynx Flashlight 高级遥测技术,包括 P4 带内网络遥测 (INT)。Teralynx 10单芯片尺寸为93X93mm,I/O数量为8855,在PCB设计部分,板材使用业界最新Low Dk/Df材料,PCB结构设计上采用12+12+12的结构设计,其中中间12层均采用2OZ铜箔,以满足芯片供电需求。
在今年4月的AI 投资者之日大会上,Marvell表示, Teralynx 10 51.2T 产品已开始量产。
盛科自2005年成立以来,盛科通信始终专注以太网交换芯片及配套产品研发、设计和销售,定位中高端产品线,已覆盖从接入层到核心层的以太网交换产品,交换容量范围100Gbps2.4Tbps,端口速率范围100M400G,全面应用于企业、运营商、数据中心和工业网络等领域。
TsingMa 系列是公司中端核心芯片,具备 440Gbps 的交换容量,支持最大 100G 端口速率,集成高性能 CPU,具备丰富的 5G 接入级特性。TsingMa 广泛应用于企业网络接入汇聚、5G 承载接入、工业网络和数据中心管理交换机。
目前,公司面向超大数据中心的高性能交换产品 Arctic 系列尚在试生产阶段,最高交换容量达到 25.6Tbps,支持最大端口速率 800G,且具备增强安全互联、榫卯可编程、增强可视化引擎等先进特性。Arctic 系列去年底进入客户送样测试环节,拟于 2024 年推出。
 设备厂商思科
设备厂商思科2024 年 6 月,思科宣布成立10 亿美元的全球投资基金,以扩展和开发安全可靠的 AI 解决方案。思科正在对 Cohere、Mistral AI 和 Sale AI 进行战略投资,这将推动多个关键领域的发展,包括客户准备、计算基础设施、基础模型、模型开发和培训。
在过去一年中,思科推出了一系列AI驱动的产品和解决方案,涵盖了网络管理、安全、协作和数据中心等领域。关键创新包括与英伟达合作的Cisco Nexus HyperFabric AI clusters、在Cisco Security Cloud中引入生成式AI功能、以及增强Webex平台的AI功能,如智能会议摘要和对话总结。
此外,思科还推出了新的Cisco Observability Platform,并结合Splunk平台提供实时洞察和可见性,帮助用户更好地管理混合环境中的应用性能。思科还推出了AI基础设施解决方案,如Cisco UCS X-Series Direct,以及AI能力认证计划,进一步推动企业在AI技术应用和发展方面的准备。
思科Silicon One G200和G202芯片基于5nm工艺,可提供高达51.2 Tbps的吞吐量,具有512个100GE以太网端口,适用于大规模AI/ML网络。这些芯片支持高度优化的负载均衡和故障检测技术,可以显著减少网络拥塞和提高性能。思科 Silicon One G200芯片特别设计用于以太网AI/ML网络,具有先进的拥塞感知负载均衡和包喷射技术,能够减少网络热点的产生,并通过硬件故障恢复技术,保证在大规模网络中的最佳性能。其能效和低延迟性能相比之前的G100型号提高了两倍以上,能够显著减少能耗和运营成本。
 新华三
新华三新华三在数据中心、园区、广域网各场景中,均提供了基于AI能力的网络产品与技术方案。
在数据中心,新华三推出了新一代智算网络解决方案,全面增强网络对于多元异构算力的承载能力。首先,智算网络解决方案为用户提供不同端口密度、形态丰富的交换机产品,可应对更大规模的突发流量,提高了带宽上限。其次,新方案可提供单框单层、盒-盒两层、框-盒两层等众多组网形态,能为智算中心和集群提供更多端口,更有利于集群扩容。第三,方案核心产品H3C S12500AI系列交换机所采用DDC网络架构,能够提供信元级负载均衡能力,确保100%无损传输,结合LBN端口对称负载均衡、DLB动态逐流负载均衡、FGLB全局动态负载均衡、SprayLink动态逐包喷洒等不同的负载均衡技术组合,可全面满足不同智算场景的网络调优和流量均衡目标。由此,方案便可基于标准化的以太网技术堆栈,保持架构的开放兼容;同时也解决集群效率问题,为算力规模的进一步成长铺平道路。


此外,在园区场景,新华三发布了全新“4i+技术体系”以及全场景Wi-Fi 7产品,通过融入机器学习、知识图谱和机器预测等AI能力,实现基于终端特点的精准保障和控制以及网络业务预测。在广域场景,为了实现算力的广域网传输,新华三也在路由带宽、路由算法、专线服务化等层面对现有产品进行了深度优化。而在更高级的运维管理和安全层面,新华三则积极推进大模型技术与传统运管及安全方案的深度融合,推出灵犀大模型,为用户提供了具有全网络协同、全天候服务、多维度洞察和场景化增效等特点的网络运维体验。
华为华为“端网协同的零队列主动拥塞控制”是一项创新的网络管理技术,旨在通过改进的主动队列管理(AQM)算法,显著提升网络设备的数据传输效率和稳定性。这项技术通过端网设备的协同工作和基于空闲转发能力的智能决策,有效缓解网络拥塞问题。“端网协同的零队列主动拥塞控制”在多个方面实现了技术创新,极大地提升了网络管理的效率和性能。以下是该技术的主要创新点:
零队列管理:通过精确计算网络设备的空闲转发能力,实现了网络设备上排队队列深度的实时调整和最小化,甚至达到零队列(零排队)的效果。端网协同机制:该技术引入了端网协同工作模式,发送端设备与网络设备协同配合,有效避免了网络拥塞的发生和扩大。基于空闲转发能力的智能决策:通过计算网络设备的空闲转发能力,根据预设时长内的目标出队列或目标出端口的转发数据量上限及实际转发量,动态调整发送端设备的发送策略。高效算法:相比传统的RED/ECN算法,该技术采用了简单且高效的算法,快速做出决策,适用于高速网络设备。灵活性和可定制性:该技术允许用户根据实际需求自定义网络设备的队列深度,从而在不同的应用场景中提供最佳的解决方案。目前该方案已经初步在国产化小规模智算中心网络中实现百节点级规模部署应用,具备应用示范效应,未来通过软件优化调整,具备更大规模落地能力,可支持智算中心万卡规模下的AI网络部署能力。
浪潮信息面对AI市场的迅猛需求,浪潮信息推出了超级AI以太网交换机X400,采用全球领先的Spectrum-4交换芯片,支持128×400G的高密端口,实现业界最高吞吐51.2T,提供领先的数据包处理速率、全线速性能和超低直通延迟,通过自适应路由和增强拥塞控制技术,实现95%以上的以太网利用率,同时依托完全共享的数据包缓冲区架构,动态地为所有端口提供公平且无瓶颈的数据路径,成为构建AI高性能RoCE网络的理想产品。

浪潮信息基于X400和智能网卡,打造了端网协同的X400 AI Fabric方案,可支持超大规模组网,二层组网轻松支持8K GPU节点,三层组网最大可以支持512K GPU节点,充分满足AI Cloud大规模组网要求;支持AR自适应路由转发,网络内链路负载高度均衡,减少拥塞丢包,整体带宽负载利用率从60%提升到95%,加速AI训练;领先的AUTO ECN端到端拥塞控制,降低平均尾延迟30%以上,缩短网络通信占比时间,提升GPU训练效率;支持端到端的RTT-CC拥塞控制算法,提升RoCE网络30%部署效率。X400 AI Fabric实现了与专用网络架构相当的网络性能,确保客户以更理想的方式建设网络基础设施,极大提升AI模型迭代与业务创新的速度。
中兴通讯传统DCQCN网络因其拥塞标记信息粗略和端侧与网络侧流控机制的相对独立,难以在高吞吐、满负荷的网络环境下避免拥塞、丢包和时延等问题。为提升高性能网络的传输性能,中兴通讯提出了RoCEv2网络端网协同创新解决方案,通过端网协同联动机制实现精准、快速的拥塞控制和流量调度算法,使网络的吞吐率提升到90%以上。该方案在拥塞控制和精准流控两个方向实现端网协同创新。

此外,在2024 MWC会上,中兴通讯重磅发布从算力、网络、能力、智力到应用的全栈全场景智算解决方案。
在算力方面,中兴通讯以全系列服务器、高性能存储、无损网络和绿色数据中心为多样化智算中心构筑强劲引擎。在网络方面,星云智算网络方案以及独创的ENCC端网协同拥塞流控、IGLB智能全局负载均衡等技术,为智算提供高速的算内、算间连接。在智力方面,泛在内生智能,系列化星云大模型,为千行百业打造坚实数字底座。在AI应用方面,中兴通讯正通过自身实践,以滨江智能工厂为样板点,将机器人、数字孪生、AI、工业元宇宙等技术应用于实际生产场景,逐步实现从数字化到智能化到高度柔性自治的未来工厂,在降本增效的同时大幅提升产品质量。锐捷网络2023年,锐捷网络面向下一代AI云服务的智算中心网络建设,重磅发布了锐捷网络AI-FlexiForce智算中心网络解决方案。锐捷网络AI-FlexiForce智算中心网络解决方案拥有高性能、高可靠、高兼容、高可用等“四高”特性,可应用于大数据处理、机器学习、AIGC多种业务场景,帮助客户构建万卡级别的智算中心网络。
锐捷网络AI-FlexiForce智算中心网络解决方案采用NCP+NCF为基础模块横向扩展的三级网络架构,并基于高性能芯片技术,通过将数据流切分成等长的Cell并负载到所有链路,提升网络带宽利用率;基于VOQ+Credit的端到端流控机制实现与业务无关的无损自闭环网络,助力业务算力提升。

此外,通过创新性地应用链路负载和拥塞控制技术,AI-FlexiForce智算中心网络解决方案可以根本性解决网络中的拥塞冲突问题,提升GPU之间通信效率,进而提升GPU计算效率,加速企业大模型应用的推出。同时,锐捷网络在研发AI-FlexiForce智算中心网络解决方案时,打造了分布式OS,意在实现分布式方案架构的统一管理基础上,最大程度降低系统性风险,提升AI训练网络的长期稳定运行。
AristaArista Networks在AI领域推出了多个创新产品和解决方案,特别是与英伟达合作开发的AI数据中心解决方案。这些解决方案旨在将计算和网络域对齐为一个单一管理的AI实体,优化生成式AI网络的性能,降低作业完成时间。
其中,Arista的Etherlink AI网络平台提供专为AI工作负载(包括训练和推理)优化的网络性能。Etherlink 产品组合包括基于超高性能标准的以太网系统,具有用于 AI 网络的智能功能,涵盖一系列专业的负载平衡和拥塞控制功能,包括 Arista 的 RDMA Aware QoS 和负载平衡功能,可确保向所有支持 RoCE 的 NIC 可靠地传送数据包。Arista Etherlink 还引入了具有工作负载和 NIC 集成的 AI Analyzer,以缩短集群部署时间、提高运行稳定性并提供由 AVA 机器学习支持的深度可视性。基于 Arista EOS 的各种 800G 系统和线卡均支持 Etherlink 功能,并且向前兼容 UEC。此外,Arista还引入了AI驱动的网络身份服务,基于其CloudVision平台,帮助企业简化部署和扩大云规模的安全IT运营。

Arista 提供一系列固定、模块化和分布式平台,这些平台可以单独部署用于较小的集群,也可以组合起来构建适用于十万个以上加速器的大型拓扑。7060X6、7060X 系列和7388X5系列在一系列 800G 和 400G 系统中提供丰富的连接选项,容量高达 51.2Tbps,可选择 1、2 和 4U 外形尺寸。模块化7800R4 系列高性能 800G AI Spine 在单个设备中提供高达 460 Tbps 的吞吐量,具有 576 个 800G 端口或 1152 个 400G 端口。Arista 的 7700R4 系列分布式 Etherlink 交换机 (DES) 为 AI 后端网络提供了一种新方法,可扩展 7800R4 架构,以在逻辑单跳拓扑中支持多达 32,000 个加速器,同时保留确定性、公平性和 100% 高效的无损转发, 非常适合 AI 的结构。
Juniper尽管Juniper即将被 HPE 收购,但它仍在大力推动人工智能驱动的解决方案,以巩固其在网络领域的地位。2024 年 1 月底,Juniper 宣布推出AI 原生网络平台,旨在将 AI 完全集成到网络运营中,以增强用户和运营商的体验。该平台是业内首创,旨在利用 AI 使网络连接更加可靠、安全和可衡量。该平台将园区、分支机构和数据中心网络解决方案整合到一个 AI 引擎下。Marvis 虚拟网络助手是该平台的核心,它为 IT 运营提供 AI,提供洞察并自动执行网络故障排除。

Juniper推出的 Marvis Minis 作为 AI 原生网络平台的一部分,为网络管理带来了变革性方法。这些 AI 原生网络数字体验孪生集成在 Marvis 虚拟网络助手中,利用 Mist AI 进行主动模拟,使其能够验证网络配置并预先识别问题,而无需实际用户或设备活动。
除了新的软件驱动功能外,Juniper还宣布推出旨在增强其 AI 数据中心解决方案的新型路由器和交换机。新产品包括基于 Express 5 硅片的新型 PTX 路由器、线卡和新型 QFX 交换机。全新 Express 5 PTX 路由器和线卡提供顶级性能和节能可持续性,提供高密度 800GE 容量,这对于处理现代数据中心处理的大量数据至关重要;新款 QFX 交换机的容量是其前代产品的两倍,值得注意的是,这款交换机是第一款采用博通新款 Tomahawk 5 芯片的 OEM 数据中心交换机,专门用于 800GE 功能;新的 PTX 路由器和 QFX 交换机支持高 800GE 端口密度,并配备了 AI 基础设施所需的协议,例如以太网上的 RDMA(RoCE v2),以促进 AI 数据中心内节能且可扩展的网络。
测试厂商是德科技是德科技的AI智算中心测试平台基于业界领先的800G/400G RoCEv2无损网络解决方案,除了已在国内外被大量采用,作为AI网络的研究基石,是德科技亦是基于此基础之上,建构此AI智算中心测试平台,加速AI网络的设计,定义AI/ML基础架构的未来,解锁各种未知的可能性,型塑明日DPU与AI网络的样貌。

对于大多数 RoCEv2 部署,交换结构性能在整个解决方案的功能中起着至关重要的作用,因此测量相关网络 KPI(例如总吞吐量、数据包丢失、延迟、流量公平性、收敛时间和网络稳定性)至关重要。 此类 KPI 需要在不同条件下(例如不同程度的拥塞或网络事件以及链路关闭/抖动)以及不同网络配置(缓冲区大小、ECN 设置、流量类别隔离参数等)下使用以下流量进行测量: 尽可能接近产品流量(数据包大小、消息长度、队列对(Q-pair)数量等),最终将 RoCE 与多个发送方和接收方之间的其他基于 TCP 的流量结合起来。
在底层的RoCEv2无损网络为基础,此AI智算中心测试平台可制定用户接口,用户驱动讯务,或是在连续的整合管道上批次执行;而首先被推出的即为是德科技聚合通讯基准检验(KCCB, Keysight Collective Communication Benchmark)解决方案。此基准检验是设计用来量测用户提供的AI网络拓扑及算法,藉此解决方案,您将可以不需连接GPU等加速器来进行效能量测与设计优化。给定数据大小后,包括算法完成时间,聚合通讯带宽,信道带宽,比例,pfc个数,以及每对Q-Pair重要时间量测结果均能呈现,让用户得以优化丛设定,拥塞控制,算法,数据大小,传输模式以及NIC数据等重要AI网络参数。
互联网厂商百度基于大模型训练的需求,百度提出了 AI 高性能网络的三大目标:超大规模、超高带宽以及超长稳定,有针对性地设计了 AI 大底座里面的 AI 高性能网络—— AIPod。下图是关于 AIPod 高性能网络的点线图,这张网络里面有约 400 台交换机、3000 张网卡、10000 根线缆和 20000 个光模块。

为了支撑超大规模的这张 AIPod 网络,百度选择了 3 层无收敛的 CLOS 组网结构。下图是AIPod 的架构示意图。AIPod 使用 8 导轨网络架构,以 GPU A800 服务器为例,它配有 8 张网卡,然后每张网卡分别连到一个 TOR 汇聚组的 8 个 TOR 上。在 TOR 和 LEAF 层面,通过Full Mesh的方式进行互联。如果是三层 RDMA 网络,在 LEAF 和 SPINE 层面也是采用 Full Mesh 的互联方式。
 阿里云
阿里云阿里云自研的HPN7.0高性能AI智算集群网络,成为SIGCOMM 历史上在AI智算集群网络架构领域的首篇论文。HPN 7.0创新性地设计了“双上联+多轨+双平面”的网络架构,同时配备51.2Tbps单芯片以太网交换机、400G高性能网卡和自研的Solar-RDMA和ACCL通信库。这些技术的应用使得HPN 7.0能够实现单层千卡、两层万卡的高性能和高稳定性互联。
 千卡 Segment 设计:HPN7.0允许 1000 张 GPU 卡通过单层网络交换完成互联。在这样一个千卡范围内,网络可以发挥出极致的性能,测试结果表明,这种设计下的计算效率是业界最优的。两层网络实现万卡规模:通过两层网络结构,能够支持多达十几个千卡 segment,从而实现万卡规模的网络交互。两层网络不仅减少了时延,还简化了网络连接的数量和拓扑。在三层网络结构中,端到端的网络路径数量是乘数关系,而两层网络只有两跳,简化了路径选择,提高了哈希效果。存算分离:计算流量具有明显的规律性,表现为周期性的波动,目标是缩短每个波峰的持续时间,而存储流量是间歇性的数据写入和读取。为了避免存储流量对计算参数同步流量的干扰,在设计中将计算和存储流量分配在两个独立的网络中运行。
千卡 Segment 设计:HPN7.0允许 1000 张 GPU 卡通过单层网络交换完成互联。在这样一个千卡范围内,网络可以发挥出极致的性能,测试结果表明,这种设计下的计算效率是业界最优的。两层网络实现万卡规模:通过两层网络结构,能够支持多达十几个千卡 segment,从而实现万卡规模的网络交互。两层网络不仅减少了时延,还简化了网络连接的数量和拓扑。在三层网络结构中,端到端的网络路径数量是乘数关系,而两层网络只有两跳,简化了路径选择,提高了哈希效果。存算分离:计算流量具有明显的规律性,表现为周期性的波动,目标是缩短每个波峰的持续时间,而存储流量是间歇性的数据写入和读取。为了避免存储流量对计算参数同步流量的干扰,在设计中将计算和存储流量分配在两个独立的网络中运行。据悉阿里云从去年年初开始设计研发 HPN7.0,去年 9 月份HPN 7.0已在阿里云进行大规模部署,并显著提升了大模型训练性能和智算网络的整体稳定性。基于HPN 7.0架构训练的通义千问2.5版本大模型,在理解能力、逻辑推理、指令遵循、代码能力等方面均有显著提升。
腾讯云腾讯云智算网络解决方案IHN(Intelligent High-performance Network 智能化高性能网络),作为腾讯混元大模型infra网络底座,支持超万卡集群规模、多型号异构GPU接入、分钟级故障自愈能力,向上支撑了600+腾讯业务。腾讯云IHN有三个特色:
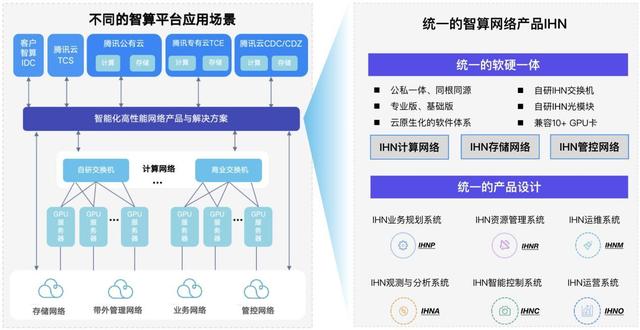 在六大场景、同集群异构GPU接入下,用统一的架构提供极佳的产品体验:腾讯云IHN支持网络独立交付、公有云、专有云TCE、分布式云CDC/CDZ等六种场景,兼容多厂商GPU异构接入,基于统一的架构和版本为客户提供极佳、一致的产品体验。高性能下的极致性价比,性能媲美IB:腾讯云IHN在硬件上提供全自研的交换机和光模块,单机支持3.2T双归接入带宽;软件上提供全栈智能化的管控能力。IHN具备软硬一体交付能力,通过端网深度协同,以低于IB的成本实现媲美的IB性能。万卡集群下,网络故障可1分钟发现,3分钟定位,5分钟解决:基于腾讯混元大模型万卡集群深度运维经验沉淀,打造了五个可为的智能化运维可实现“1分钟快速发现、3分钟精准定位,5分钟高效解决”的效能目标。
在六大场景、同集群异构GPU接入下,用统一的架构提供极佳的产品体验:腾讯云IHN支持网络独立交付、公有云、专有云TCE、分布式云CDC/CDZ等六种场景,兼容多厂商GPU异构接入,基于统一的架构和版本为客户提供极佳、一致的产品体验。高性能下的极致性价比,性能媲美IB:腾讯云IHN在硬件上提供全自研的交换机和光模块,单机支持3.2T双归接入带宽;软件上提供全栈智能化的管控能力。IHN具备软硬一体交付能力,通过端网深度协同,以低于IB的成本实现媲美的IB性能。万卡集群下,网络故障可1分钟发现,3分钟定位,5分钟解决:基于腾讯混元大模型万卡集群深度运维经验沉淀,打造了五个可为的智能化运维可实现“1分钟快速发现、3分钟精准定位,5分钟高效解决”的效能目标。总之,IHN面向客户不同智算场景和需求,提供了全栈自研的软硬一体产品,同时业界一流的建设效率和高效的运维系统保障了IHN算力网络的长期稳定性。
AWSAWS 有自己基于以太网的架构,该架构依赖于其定制的 Elastic Fabric Adapter (EFA) 网络接口,该接口使用称为可扩展可靠数据报 (SRD) 的技术,这是 AWS 设计的网络传输协议。
AWS 还交付了一个针对生成式 AI 工作负载优化的新网络。第一代 UltraCluster 网络于 2020 年建成,支持 4,000 个GPU,服务器之间的延迟为 8 微秒。UltraCluster 2.0 于 2023 年推出,内部称为“10p10u”网络,每秒可提供数十 PB 的吞吐量,往返时间不到 10 微秒。新网络 UltraCluster 2.0 支持超过 20,000 个 GPU,延迟减少了 25%。它仅用了七个月的时间建成。AWS 称 UltraCluster 2.0至少可将模型训练时间缩短 15%。
过去几年,AWS 一直在设计自己的AI芯片,包括 AWS Trainium 和 AWS Inferentia,目标是使其在训练和运行生成式 AI 模型时更加节能。AWS 第三代 AI 芯片 Trainium2 将于今年晚些时候上市。Trainium2 旨在提供比第一代 Trainium 芯片快 4 倍的训练速度,并且能够部署在多达 100,000 个芯片的 EC2 UltraClusters 中,从而能够在很短的时间内训练基础模型和大型语言模型,同时将能源效率提高 2 倍。

AWS Inferentia2 加速器与第一代相比在性能和功能方面实现了重大飞跃。Inferentia2 的吞吐量提高了 4 倍,延迟低至 1/10。AWS Inferentia2 支持多种数据类型,包括 FP32、TF32、BF16、FP16 和 UINT8,还支持新的可配置 FP8 (cFP8) 数据类型,因为它减少了模型的内存占用和 I/O 要求。AWS Inferentia2 具有嵌入式通用数字信号处理器 (DSP),可实现动态执行,因此无需在主机上展开或执行控制流运算符。AWS Inferentia2 还支持动态输入形状,这对于输入张量大小未知的模型(例如处理文本的模型)至关重要。
微软微软的 Azure Maia AI 芯片和基于 Arm 的 Azure Cobalt CPU 将于 2024 年上市。新的 Azure Maia AI 芯片和 Azure Cobalt CPU 均由微软内部开发,并对其整个云服务器堆栈进行了深度改造,以优化性能、功耗和成本。
Maia 100 AI 加速器专为高效运行云端AI工作负载而设计,特别是大型语言模型的训练与推理任务。该加速器采用台积电5纳米制程技术,集成了1050亿个晶体管。目前,微软正在测试 Maia 100 如何满足其必应搜索引擎的 AI 聊天机器人(现称 Copilot)、GitHub Copilot 编码助手和 GPT-3.5-Turbo(微软支持的 OpenAI 的大型语言模型)的需求。

当前微软已经开始开发自己的网卡,以减少对英伟达硬件的依赖并加快其数据中心的速度 。一年前, 微软收购了DPU开发商 Fungible,这意味着该公司显然拥有设计适用于高带宽 AI 训练工作负载的数据中心级网络设备所需的网络技术和 IP。 新的网卡有望提高微软 Azure 服务器的性能和效率,未来微软将采用自己的 CPU 和 GPU。
谷歌2024 年5 月,谷歌宣布了其名为 Trillium 的第六代 TPU,谷歌声称Trillium芯片是“迄今为止性能最高、最节能的TPU。“
与 TPU v5e 相比,Trillium TPU 的每芯片峰值计算性能提高了 4.7 倍,高带宽内存 (HBM) 容量和带宽增加了一倍,芯片间互连 (ICI) 带宽增加了一倍。此外, Trillium还配备了第三代SparseCore ,这是一种专门用于处理超大嵌入的加速器。Trillium TPU 可以更快地训练下一波基础模型,并以更低的延迟和更低的成本为这些模型提供服务。最重要的是,Trillium TPU 比 TPU v5e 节能 67% 以上。

Trillium 可以在单个高带宽、低延迟的 pod 中扩展到 256 个 TPU。除了这种 pod 级可扩展性之外,借助多切片技术和Titanium 智能处理单元 (IPU ),Trillium TPU 可以扩展到数百个 pod,连接通过每秒多 PB 级数据中心网络互连的楼宇规模超级计算机中的数万个芯片。
Meta2024年3月,Meta 对外披露了其最新的AI基础设施部署,新推出了两个 2.4 万个GPU 集群(共 49152 个 H100)。在集群架构上,Meta注重高性能网络结构的优化,以及关键性的存储策略选择,再加上每个集群中的 24576 个 NVIDIA Tensor Core H100 GPU,使两个集群版本都能够支持更大规模、更复杂的模型。
 在网络方面,Meta基于Arista 7800、Wedge400和Minipack2 OCP机架交换机,构建了一个基于RoCE 网络fabric 解决方案的RDMA集群。另一个集群采用了NVIDIA Quantum2 InfiniBand结构。这两种解决方案都能互连 400 Gbps 端点。在计算方面,上述的两个集群都是基于 Grand Teton构建的。Grand Teton是Meta内部设计的开放 GPU 硬件平台,于2022年10月18日首次发布,现已被贡献给开放计算项目 (OCP)。在存储方面,Meta的存储部署通过用户空间中的本地 Linux 文件系统 (FUSE) API 来满足 AI 集群的数据和检查点需求,该 API 由针对 Flash 媒体优化的 Meta“Tectonic”分布式存储解决方案版本提供支持。
在网络方面,Meta基于Arista 7800、Wedge400和Minipack2 OCP机架交换机,构建了一个基于RoCE 网络fabric 解决方案的RDMA集群。另一个集群采用了NVIDIA Quantum2 InfiniBand结构。这两种解决方案都能互连 400 Gbps 端点。在计算方面,上述的两个集群都是基于 Grand Teton构建的。Grand Teton是Meta内部设计的开放 GPU 硬件平台,于2022年10月18日首次发布,现已被贡献给开放计算项目 (OCP)。在存储方面,Meta的存储部署通过用户空间中的本地 Linux 文件系统 (FUSE) API 来满足 AI 集群的数据和检查点需求,该 API 由针对 Flash 媒体优化的 Meta“Tectonic”分布式存储解决方案版本提供支持。4月,Meta展示了其AI芯片研发的最新进展——新一代MTIA。与基于 7nm 工艺构建的 MTIA v1 相比,新一代 MTIA 采用了更为先进的 5nm 工艺,在物理尺寸上有所增加,并搭载了更多的处理核心。尽管整体功耗有所提升(从25w到90w),但配备了更多的内部存储器(从64MB扩容至128MB)。Meta 表示,新一代 MTIA 目前已在其 16 个数据中心区域投入使用,并且相较于MTIA v1 ,整体性能提高了 3 倍。
