A3Test: Assertion-Augmented Automated Test Case Generation
SARANYA ALAGARSAMY1, CHAKKRIT TANTITHAMTHAVORN1, and ALDEIDA ALETI1
1 Monash University, Australia
引用
Saranya Alagarsamy, Chakkrit Tantithamthavorn, and Aldeida Aleti. 2023. A3Test: Assertion- Augmented Automated Test Case Generation. 1, 1 (February 2023), 18 pages. https://doi.org/10. 1145/nnnnnnn.nnnnnnn
论文:https://arxiv.org/abs/2302.10352
仓库:http://github.com/awsm-research/a3test
摘要
本文提出了A3Test,这是一种基于深度学习的测试用例生成方法,通过引入断言知识和测试签名验证机制进行增强。相较于AthenaTest,A3Test在生成正确测试用例和方法覆盖率方面表现更优,同时引入的断言预训练和验证组件显著提高了性能。实验结果显示,A3Test比AthenaTest更快速且更准确。
1 引言
单元测试是软件开发中至关重要的一环,能够确保软件系统的质量并提高开发人员的工作效率。然而,编写高质量且有效的测试用例往往是一项繁琐且耗时的任务。因此,人们提出了各种自动生成测试用例的方法,例如基于随机和基于搜索的测试用例生成方法。然而,先前的研究表明,尽管这些方法都能够实现较高的代码覆盖率,但却无法生成具有人类可读性的测试用例(例如,生成的测试方法名称为test0(),而非testAddition()),且无法完全满足工业界开发人员对软件测试的需求。缺乏人类可读性的测试用例可能会影响测试用例的理解、调试和维护工作。
最近,Tufano等人提出了AthenaTest模型,这是一种基于Transformer的模型,能够从开发人员编写的测试用例中学习,从而生成正确且易读的测试用例。AthenaTest被构建为一个翻译任务,其源语言是指待测试的方法,目标语言则是软件开发人员最初编写的相应测试用例。研究结果显示,其中16.21%的生成测试用例被证实是正确的,即它们能够正确地测试焦点方法并通过测试执行。不过,遗憾的是,AthenaTest的复制包目前并不可用。
为了克服这一挑战,我们首先使用Defects4J作为评估数据集,对Tufano等人的研究进行了部分复制研究(RS)。我们使用了原始论文中报告的超参数设置,并尽力以最佳能力实现了AthenaTest方法。遗憾的是,AthenaTest未能生成任何正确的测试用例(0%),这表明我们未能复现论文中报告的结果。这可能与某些细节和设置(例如批量大小、微调、epoch)的缺失有关。另一方面,通过适当的修改,我们成功实现了AthenaTest方法,其结果为18.08%,与原始论文中的16.21%相近。然而,生成的测试用例准确性仍然远未达到完美,这突显了进一步改进基于深度学习的测试用例生成方法的必要性。特别是,AthenaTest还存在以下局限性。
局限 1:缺乏断言知识。在单元测试中,断言对于评估预期行为至关重要。然而,AthenaTest的预训练仅限于自然语言数据集和源代码,这影响了生成测试用例的质量。在AthenaTest生成的测试用例中,有26.71%的断言是不正确的。例如,assertEquals(X, Y, Z)是一个不正确的断言,因为assertEquals()应该只有两个输入参数(即预期输出值和实际值),而不是三个。
局限 2:缺乏命名一致性和测试签名验证。AthenaTest利用通用波束搜索法生成测试用例。然而,AthenaTest生成的测试用例中有9.49%在语法上不正确。例如,AthenaTest可能会生成错误的测试方法名称read(),而实际测试方法名称应该是testread()。此外,AthenaTest还可能生成错误的测试签名@Test void isLenient(),而测试方法中缺少public关键字。
因此,这些限制可能导致语法错误、不兼容和不可读的测试用例,从而影响开发人员的工作效率,并增加软件测试的成本。
在本文中,我们提出了A3Test(断言增强自动测试用例生成),这是一种基于深度学习的测试用例生成方法,通过断言知识与验证命名一致性和测试签名的机制进行增强,以解决AthenaTest的上述局限性。首先,A3Test利用了领域适应原则,旨在将断言生成任务中的现有知识适应于我们的测试用例生成任务。为此,我们首先使用了具有屏蔽语言模型的PLBART架构,以自监督的方式建立了断言的预训练语言模型。因此,我们的预训练语言模型可能比AthenaTest拥有更强的断言基础知识。接着,我们的预训练语言模型将针对测试用例生成任务进行微调,旨在学习焦点方法与相应测试用例之间的关系。对于任何生成的测试用例,我们都会引入一种验证方法来检查命名一致性(即修改测试方法名称,使其与焦点方法名称保持一致)和测试签名(即添加缺失的关键字,如public、void或@Test注释)。最后,我们使用Defects4J数据集来评估我们的A3Test,该数据集由5K个测试方法组成,涵盖了五个大型开源软件项目(即Lang、Chart、Cli、Csv和Gson),以回答以下四个研究问题。
RQ1 A3Test与AthenaTest相比效果如何?
结果。与 AthenaTest相比,A3Test生成的测试用例数量更少,但正确率却提高了147%,方法覆盖率提高了15%。
RQ2 A3Test 是否优于现有的预训练模型?
结果。并非所有预训练模型都能有效完成测试用例生成任务。尽管如此,在测试用例生成任务方面,A3Test仍然优于现有的预训练模型(PLBART、CodeGPT、CodeBERT、CodeT5)。
RQ3 预训练和验证组件对A3Test性能的贡献是什么?
结果。与基本PLBART模型相比,我们的断言组件贡献了35.30%,而我们的验证组件贡献了23.7%的相对改进。尽管如此,考虑到断言和验证组件的性能都是最好的。
RQ4 与AthenaTest相比,A3Test的效率如何?
结果。A3Test一次生成测试用例的时间为2.9小时,比AthenaTest快97.2%,同时准确性更高。
新颖性与贡献。据我们所知,我们是第一个提出以下方法的人:
提出了一种断言增强型自动测试用例生成方法(称为A3Test),该方法利用了领域适应性原则。与AthenaTest相比,我们的方法使测试用例的正确率提高了147%,方法覆盖率提高了15%。我们的消融研究表明,我们方法的每个组件都能够做出23.70%至35.30%的贡献,但两个组件的组合表现最佳。提供了A3Test和AthenaTest(基准方法)的复制包。开放科学。为了支持开放科学社区,我们已在GitHub存储库(http://github.com/awsm-research/a3test)中发布了我们所研究的数据集、脚本(包括数据处理、模型训练和模型评估),以及实验结果。
2 技术介绍
A3Test是一种基于PLBART的测试用例生成方法,通过断言知识与验证命名一致性和测试签名的机制进行增强。A3Test利用了领域适应原则,旨在将断言生成任务中的现有知识适应到测试用例生成任务中。为此,我们首先利用带有屏蔽语言模型的PLBART架构,以自监督的方式建立了断言的预训练语言模型。预训练的学习目标是预测给定焦点方法的屏蔽标记和相应的断言语句。因此,我们的预训练语言模型可能比AthenaTest拥有更强的断言基础知识。接着,我们通过测试用例生成任务对预训练语言模型进行微调,旨在学习焦点方法与相应测试用例之间的关系。对于任何生成的测试用例,我们都引入了一种验证方法来检查命名一致性(即修改测试方法名称,使其与焦点方法名称保持一致)和测试签名(即添加缺失的关键字,如public、void或@Test注释)。在接下来的部分中,我们将详细介绍每个步骤。
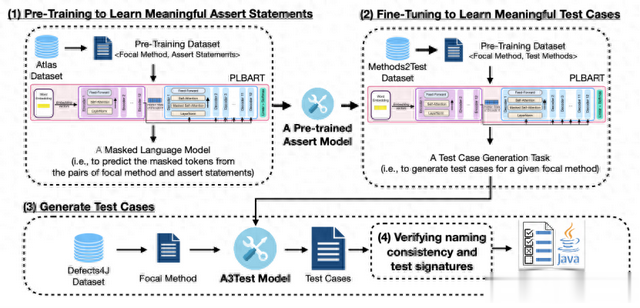
图1:概述A3Test方法,这是一种基于PLBART的测试用例生成方法,它通过断言知识和验证命名一致性和测试签名的机制来增强。
2.1 学习有意义的断言语句
断言语句用于评估单元函数的预期行为。然而,生成测试用例是一项艰巨的任务,因为它涉及到断言等测试应用程序接口,而这些应用程序接口比编程语言的一般知识要多得多。遗憾的是,AthenaTest只根据自然语言和源代码建立了一个预训练模型,而没有考虑断言知识。
为了应对这一挑战,我们利用了领域适应原则,其目标是通过使用模型从另一个具有充分标记数据(即生成的断言)的相关领域中学到的知识,提高模型在包含不充分断言语句的目标领域(即生成的测试用例)上的性能。因此,我们将源域定义为断言生成,而目标域则是测试用例生成。预训练的断言模型是通过屏蔽语言模型(MLM)以自我监督的方式建立的。进行预训练的目的是从损坏的数据中重建原始数据,并屏蔽20%的标记。MLM训练一个模型来预测输入标记的随机样本,这些输入标记在多类设置中被整个词汇表中的[MASK]占位符所取代。特殊标记[MASK]被替换为输入序列中的随机样本标记。
与使用BART架构的Athena2Test不同,我们使用PLBART架构作为构建预训练模型的基础架构。PLBART架构利用双向注意力机制来捕捉序列中过去和未来的上下文,这与利用标准注意力机制的BART不同,使我们的A3Test能够高效地并行学习输入序列。此外,PLBART已在自然语言语料库和7种编程语言上进行了预训练,而AthenaTest则在自然语言语料库和一种编程语言上建立了BART预训练模型。
为了建立预训练断言模型,我们使用了Atlas数据集,这是一个包含188154对焦点方法和断言语句的大型语料库。
2.2 学习有意义的测试用例
根据领域适应原则,我们将预训练的断言模型进行微调,以学习有意义的测试用例。为此,我们通过测试用例生成任务对预训练的断言模型进行微调,从而建立A3Test模型。测试用例生成任务是一个翻译任务,其源是一个焦点方法(即我们要测试的方法),目标是软件开发人员最初编写的相应测试用例。我们特别使用Methods2Test数据集对A3Test模型进行微调。Methods2Test数据集由780k对焦点方法和相应的测试方法组成。我们将数据集分成两组,即训练集(80% - 624022对)和验证集(10% - 78534对)。
2.3 生成测试用例
在推理阶段,我们为每种焦点方法生成一个测试用例。为此,我们使用波束搜索作为解码方法。我们利用波束搜索在每个时间步为输入序列选择多个候选。波束搜索不是在每个时间步预测概率最高的标记,而是同时探索搜索空间的不同部分。波束搜索解码方法在生成测试用例候选码的同时,会跟踪前k个概率最高的候选码(k为波束大小)。这样,波束搜索就可以使用最佳优先搜索策略,选择概率最高的最佳候选测试用例,从而使我们的A3Test能够高效地生成一个最佳测试用例,而不是像AthenaTest那样生成30个候选测试用例。
2.4 验证命名一致性和测试签名
生成的测试用例可能存在语法错误(例如,缺失括号、错误的测试方法名称或无效的测试签名),这可能会影响A3Test的性能。为了解决这一挑战,我们引入了一种自动验证方法(AthenaTest之前未使用过),以检查并纠正命名一致性和无效的测试签名。我们的验证方法包括三个部分:(1)验证不完整的括号;(2)验证命名一致性;(3)验证测试签名。
1 验证不完整的括号。生成的测试用例可能存在不完整的括号(例如(), {})。因此,我们开发了一种push-pop算法来检测和纠正缺失的括号。通过这种方法,我们能够检测并纠正缺失的括号。
2 验证命名的一致性。通常,测试方法的命名必须符合JUnit框架的命名约定(例如,测试方法的名称必须以test开头)。因此,测试用例可能因方法名称不正确(即命名不一致)而出错。例如,名为read()的测试方法将被认为是不正确的,因为它不以test开头。因此,测试框架不会将其识别为测试用例,也不会执行它。我们开发了一种使用字符串处理方法来检测和纠正命名一致性的方法。我们检查方法名称的前缀(即检查前四个字母是否为test)。如果前缀缺失,我们的方法将在测试方法名称中添加test前缀。因此,根据给定的示例,错误的测试方法名称(read())将自动修改为testread()。
3 验证测试签名。如果测试用例与JUnit框架的测试方法签名不匹配,就不会被执行。一般来说,Java方法可以是private、public、protected或package-private。然而,我们鼓励测试用例只能是public方法,以便能够执行。遗憾的是,基于DL的测试用例生成方法并没有受过专门训练,只能生成public方法,也可能生成其他类型的方法。此外,缺乏一种机制来验证测试签名,以便成功执行。因此,我们引入了一种基于字符串处理的测试签名验证方法。对于给定的测试方法,我们首先检查序列和前四个标记(即@Test public void test[MethodName]{...})是否存在以下四个特定的关键字,即@Test、public、void和test。如果前四个关键字序列中缺少任何一个关键字,我们将自动添加到生成的测试方法中,以确保我们的A3Test生成的测试方法能够成功执行。
3 实验评估
3.1 实验设置
本节将详细介绍我们的实验设置,包括数据集、模型实现、模型训练和超参数设置。
数据集。类似于AthenaTest,我们选用了Defects4J作为基准评估数据集。Defects4J提供了一系列真实世界的开源Java项目,可用于评估和比较各种软件测试技术。每个项目都是Java程序的集合,包括Java类文件和焦点方法。我们特别选择了与AthenaTest相同的五个Defects4J项目来生成测试用例,即Apache Commons Lang、JFreeChart、Apache Common CLI、Apache Common CSV、Google Gson。随后,我们解析焦点类,提取每个项目的每个公共方法的列表。总之,我们共有5278个焦点方法,其中包括Lang的2712个焦点方法、Chart的1328个焦点方法、Cli的645个焦点方法、Csv的373个焦点方法和Gson的220个焦点方法。这些公共方法中的每一个代表一个焦点方法,我们的目标是为其生成测试用例。
模型实现。A3Test建立在两个深度学习Python库(Transformers和PyTorch)之上。Transformers库提供API访问,用于基于Transformer的模型架构,而PyTorch库则在训练过程中辅助计算。
模型训练。我们从Transformers库中获取了由Ahmad等人预训练的PLBART标记器和模型。为了生成测试用例,我们使用methods2test数据集对预先训练好的断言模型进行微调。对于AthenaTest方法,我们使用了Tufano等人中描述的所有最佳超参数。实验在配备24GB内存的NVIDIA GeForce RTX 3090 GPU、配备36核处理器的Intel(R) Core(TM) i9-9980XE CPU@3.00GHz和64GB内存的环境下运行。
用于微调的超参数设置。对于A3Test方法的模型架构,我们使用了PLBART基本模型的默认设置,即12个Transformer编码器/解码器块和12个注意力头。在微调过程中,学习率设置为1e-5,并采用线性时间表。我们使用广泛采用的AdamW优化器对A3Test模型进行微调,以更新模型并最小化损失函数。
RQ1 A3Test 与 AthenaTest 相比效果如何?
动机。 Tufano等人提出了用于生成测试用例的AthenaTest。然而,其中仍存在一些局限性尚待探索,例如缺乏断言知识、缺乏命名一致性和测试签名验证。为了应对这一挑战,我们提出了A3Test,这是一种基于深度学习的测试用例生成方法,通过断言知识以及命名一致性与测试签名验证机制进行增强,从而解决了AthenaTest的局限性。因此,我们提出了这个研究问题,以研究A3Test与AthenaTest相比的有效性。
方法。为了回答这个问题,我们采用以下两种评估方法来评估A3Test方法的有效性,并与AthenaTest进行比较,这与Tufano等人的方法类似。首先,我们使用正确测试用例的数量来衡量覆盖给定焦点方法的通过测试用例的数量。其次,我们还使用焦点方法覆盖率来衡量生成的测试用例中至少有一个覆盖了焦点方法的数量。为此,我们通过JUnit框架执行测试用例,以获得测试覆盖率分析报告。在报告中,我们可以识别出(1)通过的测试用例和(2)覆盖的焦点方法。了解了正确测试用例的数量和焦点方法的覆盖范围,开发人员就能更好地判断方法是否有效。最后,我们计算了我们的方法与基线方法在各项指标上的相对改进百分比(m),具体如下:

结果。与AthenaTest相比,A3Test生成的测试用例正确率高出147%,方法覆盖率高出15%,而生成的测试用例数量却少于AthenaTest。表1列出了A3Test和AthenaTest的正确测试用例数和焦点方法覆盖率。在正确测试用例数方面,我们的A3Test达到了40.05%,即生成的测试用例中有40.05%是正确的。另一方面,AthenaTest的正确率低至16.21%,即只有16.21%生成的测试用例是正确的。这与每个Defects4J项目的情况也是一致的,因为我们发现,就正确测试用例的数量而言,我们的A3Test方法始终比AthenaTest高112%-387%。在重点方法覆盖率方面,我们的A3Test达到了46.80%,这意味着我们的A3Test生成的测试用例可以覆盖46.80%的重点方法。另一方面,AthenaTest达到了43.75%,这意味着我们的A3Test生成的测试用例可以覆盖43.75%的重点方法。这也与每个Defects4J项目一致,因为我们发现在重点方法覆盖率方面,我们的A3Test方法始终比AthenaTest高出2%-411%。
表1:(RQ1) A3Test和AthenaTest 的测试用例正确率和重点方法覆盖率。

与 AthenaTest 相比,A3Test 生成的测试用例数量更少,但正确测试用例数量和方法覆盖率却更高。理想情况下,高效的测试用例生成方法应该生成最小的测试用例集,覆盖最大的焦点方法集。A3Test和AthenaTest具有不同的内部预训练机制,因此生成的测试用例数量也不同。AthenaTest采用明确的预训练策略(即在英语/代码语料库上自行建立BART预训练)。AthenaTest设计用于生成测试用例,每个焦点方法可尝试30次,总共生成158400个测试用例(即5278个焦点方法×30次尝试)。生成的测试用例中只有16.21%(25680个)是正确的,占158400个焦点方法的43.75%。与AthenaTest不同,A3Test只需要一次尝试就能生成一个测试用例。这意味着A3Test总共生成了5278个测试用例(即5278个焦点方法×1次尝试),其中40.05%的测试用例(2114个)是正确的,涵盖了46.80%的焦点方法。尽管生成的测试用例数量较少,但A3Test却获得了更多的正确测试用例和更高的方法覆盖率,凸显了A3Test的显著优势。
与AthenaTest相比,我们的A3Test生成的测试用例数量更少,但正确测试用例数量却增加了147%,焦点方法覆盖率增加了15%。
RQ2 A3Test是否优于现有的预训练模型?
动机。在测试用例的理解和生成过程中,预训练模型发挥着关键作用。然而,不同的测试用例生成方法采用不同的预训练策略。例如,AthenaTest 利用 BART 架构,通过明确的预训练策略建立自己的预训练模型。相比之下,A3Test 采用隐式预训练策略,利用 PLBART 架构作为基础模型。此外,还有其他预训练的代码语言模型(如 CodeT5、CodeBERT、CodeGPT)。尽管这些预训练模型在各种软件工程任务中表现出色,但尚未用于测试用例生成。因此,尚不清楚哪种预训练模型最适合测试用例生成,以及我们的 A3Test 是否优于标准预训练模型。因此,我们提出了这个问题,以探究各种预训练模型与我们的 A3Test 相比的性能。
方法。为了回答这个问题,我们选择了四个现有的代码预训练模型,即 CodeT5、CodeBERT、CodeGPT 和 PLBART,作为测试用例生成任务的基础模型,而不包括其他组件(断言+验证)。然后,我们将这些模型的性能与我们的 A3Test 和 AthenaTest 进行比较。最后,我们用正确测试用例的数量来评估模型的性能。
结果。并非所有预训练模型都能有效完成测试用例生成任务。表2列出了 A3Test 的性能,并将其与不同的预训练语言模型进行了比较。我们的结果表明,在测试用例生成任务中,现有预训练模型的性能存在差异,从0%(CodeGPT、CodeBERT)到21.5%(PLBART)不等。这表明不同的预训练模型适用于特定任务。尽管预训练模型在其他软件工程任务中表现出色,但并不意味着它们在测试用例生成任务中性能最佳。这一发现突显了在采用不同预训练模型进行下游任务之前进行研究的重要性。
尽管如此,在测试用例生成任务中,我们的 A3Test 仍然优于现有的预训练模型(PLBART、CodeGPT、CodeBERT)。与单独使用 PLBART 相比,A3Test 的性能仍然更佳(从21.50%提高到40.05%),这证实了单独使用 PLBART 在测试用例生成任务中的不足。此外,单独使用 PLBART 的性能也优于 AthenaTest(最先进的方法),从16.21%提高到21.50%。尽管 AthenaTest 和 PLBART 基于相同的 BART 架构,但它们的预训练策略不同。这表明利用隐式预训练策略的 PLBART 表现优于 AthenaTest 使用的显式预训练策略。这突显了我们的 A3Test 利用了 PLBART 架构,而不是使用基本的 BART 架构。
并非所有预训练模型都能有效地完成测试用例生成任务。尽管如此,在测试用例生成任务方面,我们的 A3Test 仍然优于现有的预训练模型(PLBART、CodeGPT、CodeBERT)。
表2:(RQ2) 与其他预训练语言模型相比,A3Test 和 AthenaTest 的性能(以测试用例的正确率衡量)。

RQ3 断言预训练和验证组件对 A3Test 性能的贡献是什么?
动机。我们的 A3Test 方法由三个关键部分组成,即 PLBART + Assert 预训练 + 验证。然而,人们对哪些组件对我们的 A3Test 性能贡献最大知之甚少。因此,我们提出了这一问题,以进行一项消融研究,调查我们的 A3Test 方法各组成部分的性能。
方法。我们进行了一项消融研究,以调查 A3Test 方法各组成部分的性能。我们对实验进行了扩展,通过删除断言预训练和验证组件,对 A3Test 的以下四个变体进行了系统评估:
PLBART:不含断言预训练和验证组件的 PLBART 架构。PLBART+Verification:带有验证组件的 PLBART 架构,但不带断言预训练组件。PLBART+Assert:带有断言预训练组件但不带验证组件的 PLBART 架构。PLBART+Assert+Verification:我们自己的 A3Test。表3:(RQ3) A3Test的每个变体生成的测试用例的正确率。

结果。与基本的 PLBART 模型相比,A3Test 的断言部分贡献了相对改进的35.30%,而验证部分贡献了23.7%的相对改进。在比较PLBART和PLBART+断言时,我们观察到性能从21.50%提高到29.10%,实现了35.30%的相对改进。另一方面,在比较PLBART和 PLBART+验证时,我们发现性能从21.50%提高到了26.60%,实现了23.7%的相对改进。这些发现明确表明,我们提出的每个组件对 A3Test 方法性能的提高都做出了重大贡献。
然而,我们的 A3Test 方法同时考虑了断言和验证组件,因此性能仍然最佳。尽管我们发现每个组件都能在一定程度上促进性能的提高,但当同时考虑断言和验证组件时,性能从21.50%提高到40.05%,占了总性能提高的86.2%。这突出显示了我们提出的断言和验证组件对测试用例生成的重要性。
与基本PLBART模型相比,A3Test的断言部分贡献了35.30%,而我们的验证部分贡献了23.7%的相对改进。尽管如此,考虑到断言和验证组件的性能都是最好的。
表4:(RQ4) 在所研究的5个Defects4J项目中,生成一个测试用例(平均)、一次尝试生成测试用例和 30 次尝试生成测试用例所需的计算时间。

RQ4 与AthenaTest相比,A3Test的效率如何?
动机。在采用研究驱动方法时,测试用例生成方法的效率是一个重要的考虑因素。因此,我们提出了这个问题,以探究我们的A3Test方法与AthenaTest相比的效率如何。
方法。不同的环境可能会产生不同的执行时间,这可能会影响测试用例生成方法的效率。为确保公平比较,我们决定在我们的环境中运行AthenaTest,这与我们运行A3Test方法的环境相同。我们还单独运行每种方法,以确保时间测量的准确性。对于每种焦点方法,我们都会测量每种方法生成测试用例所需的计算时间。最后,我们报告了生成每个测试用例所需的平均时间,以及所有 5278 个焦点方法生成测试用例所需的总时间。
结果。A3Test一次生成测试用例的时间为2.9小时,比AthenaTest快97.2%,同时准确度更高。在总共5278个测试用例中(见表4),A3Test仅需2.9小时,且只需尝试1次,而AthenaTest需105小时,且需尝试30次,测试用例生成效率提高了97.2%。AthenaTest 的一次尝试需要3.5个小时。A3Test生成每个测试用例的平均时间为1.98秒,而 AthenaTest 平均需要2.34秒。这些结果证实,我们的A3Test比AthenaTest更高效,生成的测试用例也更正确。
我们的A3Test一次生成测试用例的时间为2.9小时,比AthenaTest快97.2%,同时准确性更高。
转述:程钰鑫
