
在统计学的海洋里,有些悖论就像灯塔一样,引导我们重新审视自己的认知和方法。其中最令人费解的一例就是由查尔斯·斯坦(Charles Stein)提出的斯坦悖论(stein's paradox)。这一概念挑战了我们关于最优估计的传统观念,并在多维数据分析中开创了新的思路。然而,斯坦悖论也经常被误解或过度简化。一些流行文章甚至声称,根据这一悖论,我们可以用中国茶叶的价格来更准确地预测墨尔本的降雨概率!这种说法听起来不可思议,甚至有些荒谬。
那么,斯坦悖论究竟是什么?我们真的可以“用任何东西来估计任何东西”吗?如果这一悖论真的成立,为什么墨尔本的气象学家还是只依赖于气象卫星,而不是茶叶价格呢?在这篇文章中,我们将探讨斯坦悖论的真正含义,解析其在现代统计学和数据科学中的应用。

1961年,这篇文章使整个统计学界产生了分歧,它挑战了长期以来被广泛接受并坚定信奉的统计学原则或假设,该结果现在被称为斯坦悖论。
假设有一组遵循正态分布的数据,均值为未知的μ,方差为1,

现在,随机从这个分布中选取一个数据点(样本),比如3.14,你能估算出μ的值吗?

它看起来稍大于3.14,你可能估计μ为3.14。为什么?因为正态分布的数据是集中在其平均值μ周围的,所以有很大的可能性,选取的3.14在μ附近,你的估计误差不会太大。

从理论上讲,这是“最好”的估值。现在,给出两组数据,它们彼此之间完全无关,但它们都遵循均值分别为μ_1和μ_2,方差都为1的正态分布。再次,从每个分布中随机选取1个数据,假设它们分别是3.14和1.618。
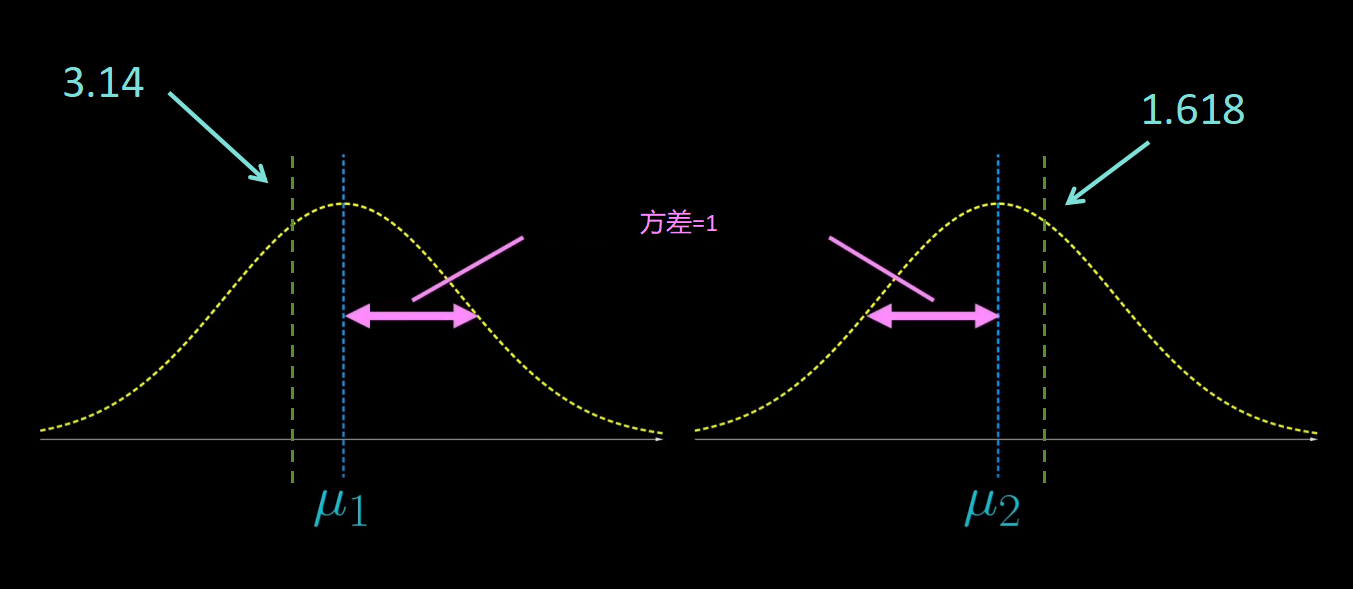
现在你会估计μ_1和μ_2分别多少?通过完全相同的逻辑,你可能也会估计μ_1为3.14,μ_2为1.618。这是这种情况下的“最好”估值。
但是,如果有三组独立的数据,事情就会发生变化。完全相同的分布:正态分布,未知的均值和方差1。通常,如果分别随机选取数据点x_1、x_2和x_3,那么你会再次估计μ_1=x_1,μ_2=x_2,μ_3=x_3吗?

但是现在这不再是最好的估值了,因为在1961年,我们找到了一个更好的估值,叫做詹姆斯-斯坦估值(James-Stein estimator)。如果数据点是x_1、x_2和x_3,那么下面就是詹姆斯-斯坦估值法对平均值的估计:

所以,为了估计μ_1,最好在前面乘以这个因子,

而不是简单地直接估值为x_1。这真的令人惊讶。这三组数据彼此之间完全独立,但是为了估计μ_1,最好结合所有三个数据点,因为前面的因子取决于x_1、x_2和x_3。
这个令人惊讶的结果现在被称为斯坦悖论。不止于此,詹姆斯-斯坦估值可以推广到p组数据,其中p至少为3,而且有这个因子:

所以简单地估计x_1=μ1,x_2=μ2是1和2维上的最佳估计。但是在3维和3维以上被詹姆斯-斯坦估值所取代。这是怎么回事?
“最好”的估值
要量化估值的优良程度,我们使用均方差(Mean squared error),

μ(hat)是估值、μ是真实但未知的均值。
在多组数据的情况下,将这些估值和均值视为向量,并考虑其平方的范数。

换句话说,我们只考虑每个组成部分的平方差,然后将它们全部加起来,最后取平均值:

这考虑到了估值中的随机性,明确地说,如果已经确定了某个样本X,它就也确定了估值:

那你就不能再引入自己的估值,这个过程已经是确定的了,不是随机的,

但取得的样本是随机的,所以这里的期望值考虑了样本的所有可能值。换句话说,这是估值平均偏离真值的程度。例如,在一维情况下,估值的均方差是多少?就是取得的样本,所以如果取得的样本是X,那么估值就是X。在这种情况下,均方差结果是X的方差的公式,

我们假设正态分布的方差是1,所以这种情况下的均方差是1。但误差通常取决于μ(真实的均值)。
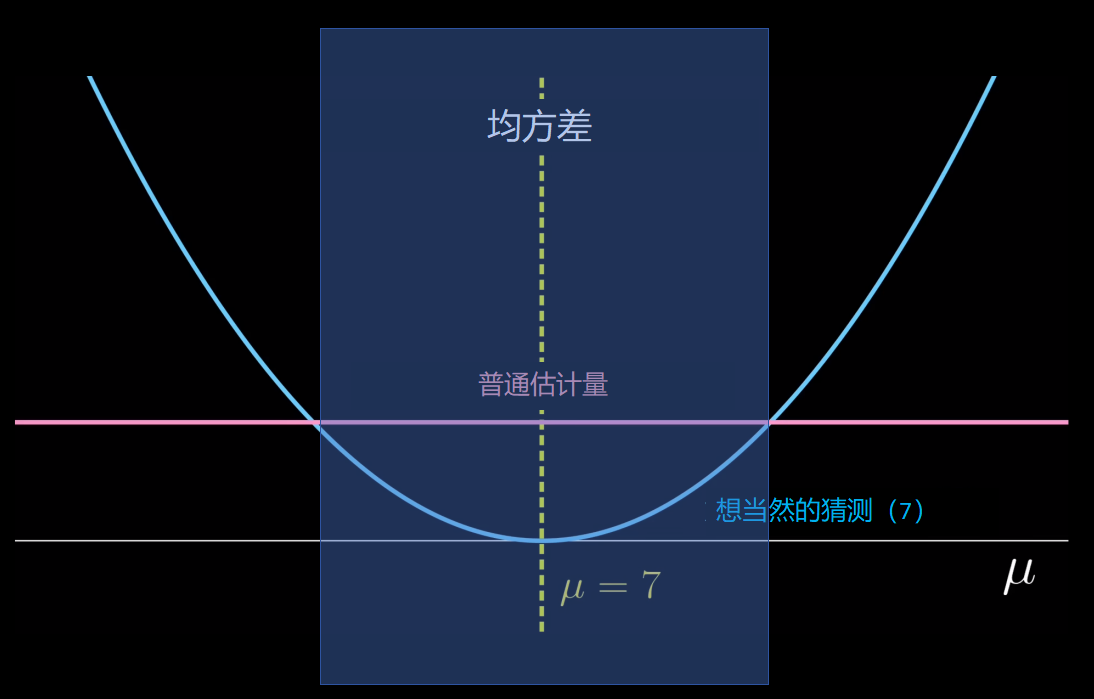
为了说明这一点,我们取一个想当然的估计量7,无论取什么样本,均值估计都是7。然后均方差是,

然而,里面的平方不取决于样本X,所以它不是一个随机量。

因此,期望值就是:

这显然取决于真实的均值μ。我们可以将这两个估值的均方差与真实均值μ进行对比。普通估值(经典方法的估值)是一个常数1,与μ无关;而想当然的估值7是一个抛物线,以μ = 7为中心,

在这种情况下,我们不能明确地说哪个估值更好,因为如果真实的均值实际上接近7,那么想当然的估值7将比普通估值更好,即它具有更小的均方差。但当然,对于其他范围,普通估值表现更好。
所以,假设一个估值A的均方差始终小于另一个估值B,那么我们说A优于B(A主导B)。

称普通的估值为“最好”估值,是因为没有估值优于它,所以这个完全低于普通估值的蓝色图不会出现,

当然,有些区域可以被超越,像想当然的估值7的周围区域,但不是完整的参数空间,
更专业地说,如果下面的蓝线不会发生在任何其他的估值上,这样的估值被称为“可接受的”:

所以在这种情况下,普通的估值是可接受的。
在更高的维度,普通估值均方差是各个组成部分之和,

所以只是把那些均方差加起来。如果有p组数据,因为单个估值的均方差是1,那么总和就是p,与真实的均值μ_1到μ_p无关。所以再次,如果绘制均方差图,它将呈现为一条直线。

然而,詹姆斯-斯坦估值的图,明显低于普通估值。换句话说,詹姆斯-斯坦估值优于普通估值。这仅适用于p = 3。对于p的其他值,

可以看到詹姆斯-斯坦估值的比普通估值好得多,尤其是当均值接近0时。但为什么詹姆斯-斯坦估值表现得更好?
收缩因子
如果想要一个更严格的解释,需要大量的数学运算。我不在这里展示,因为这不会让你更深入的理解。
如果观察詹姆斯-斯坦估值的形式,有一个因子,通常被称为收缩因子(shrinkage factor)(因为这个因通常子在0和1之间)。

然而,如果数据点太小,那么分母可能会非常小,这将使得假定的“收缩”因子实际上是负的。即使有这个缺陷,詹姆斯-斯坦估值仍然表现得更好。从几何上讲,在二维情况下,我们可以将真实均值μ_1和μ_2绘制为2D平面上的一个点。方差1意味着数据大致呈现如下分布,

围绕红点呈圆对称。那么产生的均方误差将首先取样本到红点的距离,将其平方,然后重复对距离平方,取平均的操作。

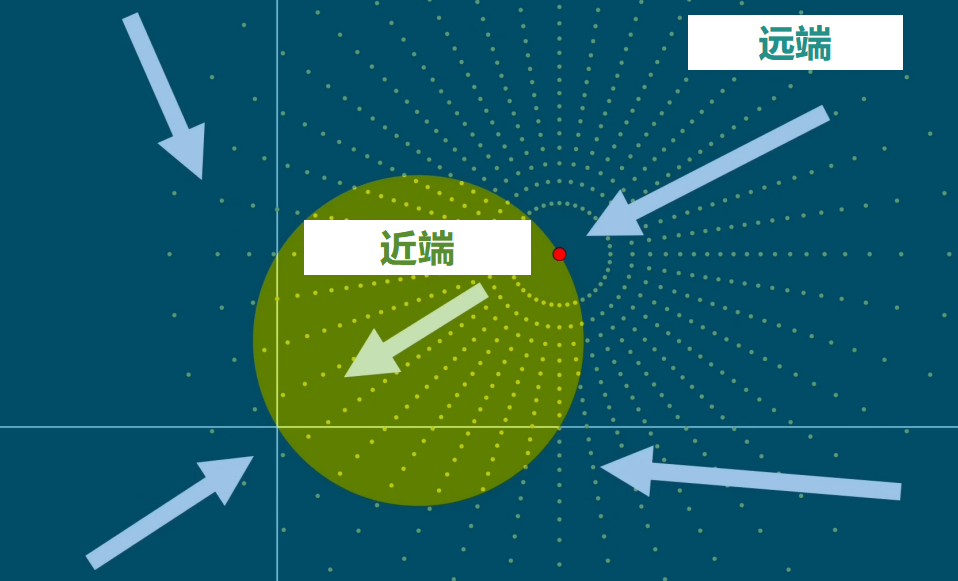
下面是收缩因子可能使平均值最小化的原因:对于远离原点的点,通过使其靠近原点,也会靠近红点。缺点是,对于已经靠近原点的点,收缩因子会使其更加接近,远离红点。

幸运的是,只有这个有限的圆形区域的点,会因为向原点收缩而远离红点。对于所有其他点,通过向原点收缩,会更靠近红点。
这甚至包括坐标轴左边的点。所以总的来说,可能会减少到红点的距离。
让我们把这个蓝色区域叫做远端,绿色区域叫做近端。
问题是,如果收缩在远端只给出了微小的减少,但在近端有相当大的增加呢?然后,通过有更大的减少区域获得的优势就会减小。
当我们计算察詹姆斯-斯坦估值到原点的距离时,就会有收缩因子乘以到原点的距离。

所以,绝对的距离减少是这个额外的项,

可以简化为这样

注意,到原点距离在分母中,这意味着如果到原点距离很大,即远离原点,那么这种距离的减少就更小。这是我们不想看到的,因为它正好在远端,到原点距离很大,红点的减少更小,而在近端,红点的距离增加更大。
因此,总是存在一种张力,即潜在的距离减少区域要大得多,而实际的距离减少要小得多。
这就是维度发挥作用的地方。
例如,在三维中,我们可以类似地将真实的均值绘制为一个点。同样,可以定义近端和远端。

在更高的维度中,那里有更多的“东西”,所以更大的体积的影响就会更加明显,这使得收缩方法在更高的维度中真正起作用。这已经是现代统计学中一个相当重要的经验教训,但还有一个更普遍的概念。
偏差-方差权衡(Bias-bariance tradeoff)
让我们重新审视均方差的公式,

这可能会让你想起方差公式,
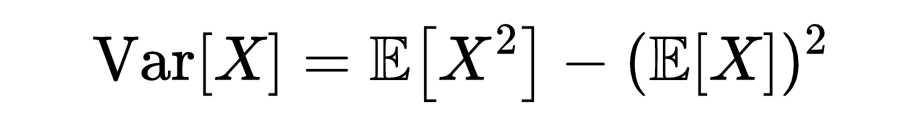
现在,我们可以简单地重新整理这个公式,并将X替换为

然后将得到一个将均方差分解为两个部分的公式,

因为μ是一个常数,不是随机的,所以,

另一部分,

被称为偏差。
用文字来说,均方差是方差和偏差平方的和。
但是这意味着什么?
从图像上来说,假设真实的均值μ由一条垂直线表示,

记住,估计值是随机的,因为它取决于样本,所以它有一个分布,
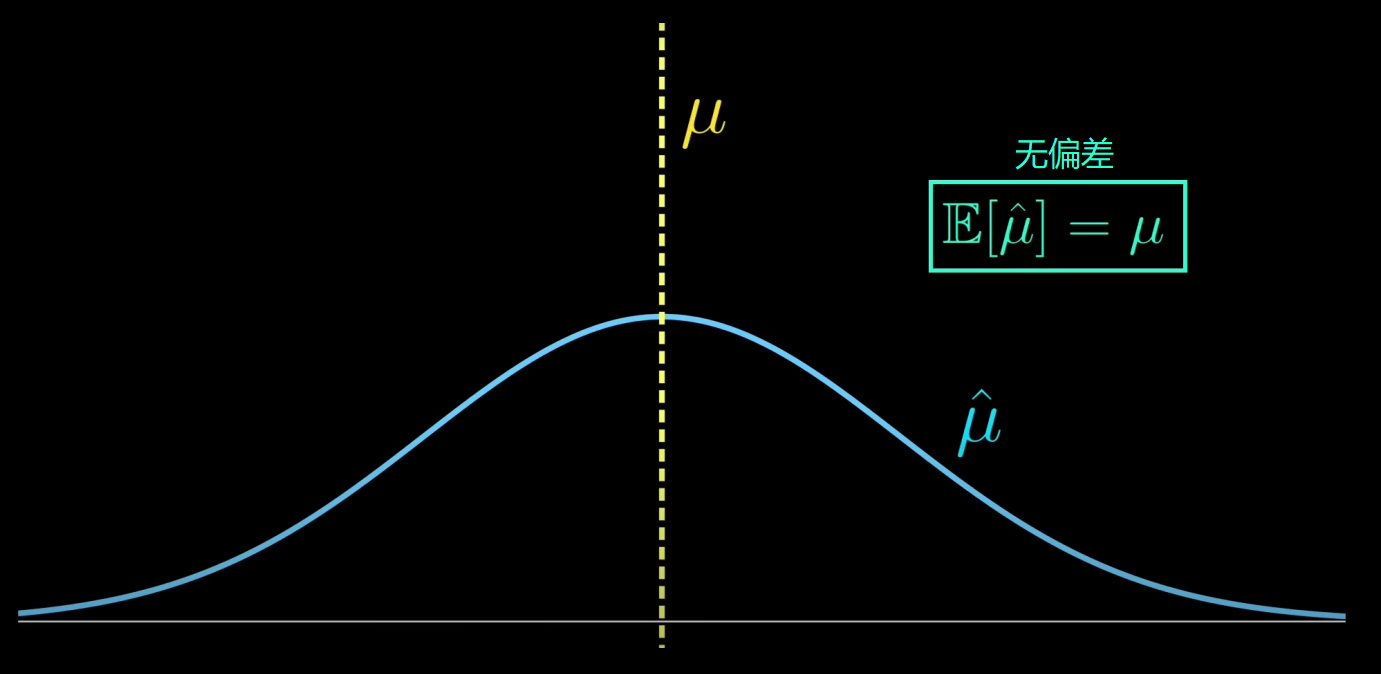
这描述了当分布的均值μ_hat恰好是μ,即偏差为0的情况。
然而,其方差相当大,所以如果我们进行估计,很可能会远离μ,误差就相当大。

有时候,引入一点偏差可能实际上会更好,如果方差能够显著减小。

然后大部分时间,它就不会远离μ太远,整体均误差仍然很小。
这就是所谓的偏差-方差权衡,这个想法是,在某些情况下,通过稍微增加偏差,使得方差可以大幅度减少,从而均方差可以减少。这在詹姆斯-斯坦中表现得非常好。
普通估值只是直接复制数据点,这种估计不会有偏差。

但是在收缩过程中,显然这些点的中心并不完全是红点,所以这显然是有偏的。
然而,这些点比没有收缩时更靠近一起,减少了方差。
当然,一个无偏的估值,如普通估值,有一些美丽的对称性,但它可能表现更差。
应用
也许你可能会认为这只是一个简单的理论问题,但是关于收缩和偏差-方差权衡的经验在现代统计学中极其重要。

如今,很多时候,我们处理的是真实世界的情况,我们试图用一个数学模型来模拟它,其中有一些输入和输出。

通常,模型可能有很多参数,你可以将其视为对输入添加不同的权重;但是我们不希望真实世界的情况是那么数学化的,如果模型预测和真实世界的情况之间存在任何区别,我们就说这只是由于随机的“噪音”。

然后,基于在真实世界的情况中观察到的很多样本输入-输出对,我们试图估计并调整那些参数或权重,这样就可以用更少的“噪音”项来解释掉任何差异。
詹姆斯-斯坦估值所的是,如果需要估计的参数很多,收缩因子实际上可以减少均方差,而且当参数数量变得越来越大时,效果会更加显著。
对于更复杂的模型,收缩甚至可以帮助我们决定哪些输入是重要的,哪些不是,特别是我们可以将一些权重全部收缩到0。
收缩的这个概念在机器学习领域被称为正则化(regularization)。
当然,我们可能不会在真实世界的情况中直接使用詹姆斯-斯坦估值,但是收缩和偏差-方差权衡将继续应用于现代统计学。

好文章[点赞][点赞][点赞][点赞][点赞]