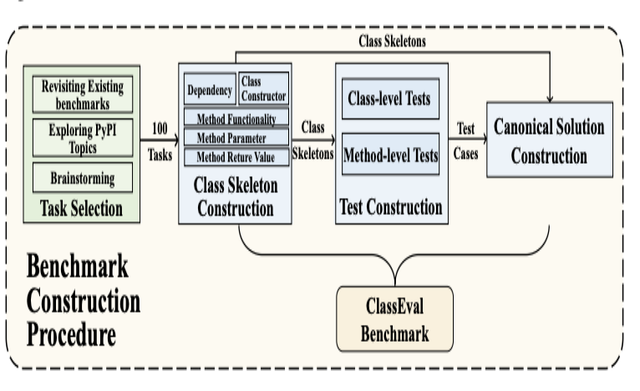
ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs
CrossCodeBench: Benchmarking Cross-Task Generalization of So
Identify and Update Test Cases When Production Code Changes:
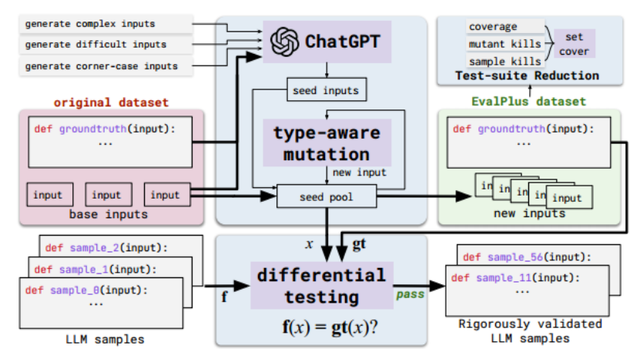
Is Your Code Generated by ChatGPT Really Correct? Rigorous E
Prompting Is All You Need: Automated Android Bug Replay with
Can LLMs Demystify Bug Reports?Laura Plein1, Tegawendé F. Bi
Cupid: Leveraging ChatGPT for More Accurate Duplicate Bug Re
Using Pre-Trained Models to Boost Code Review AutomationRosa
摘要代码审查是确保软件项目质量和可维护性的基本活动。然而,这是一项耗时且容易出错的任务,可能会严重影响开发过程。最近,C
Automating Code Review Activities by Large-Scale Pre-trainin
Make LLM a Testing Expert: Bringing Human-like Interaction t
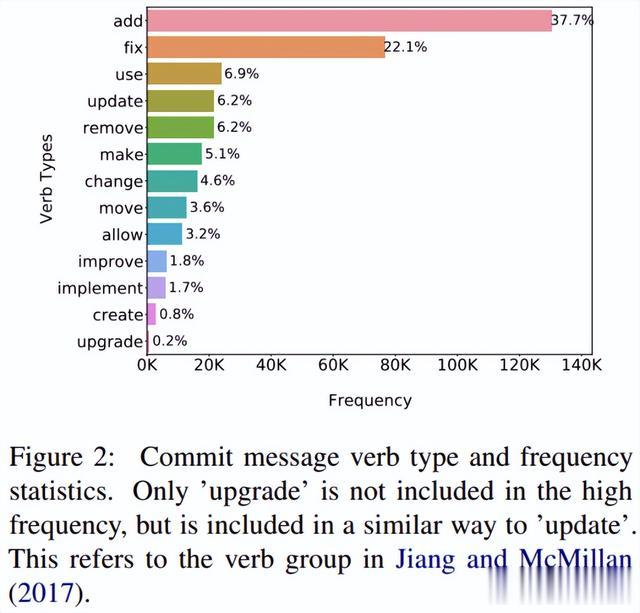
Commitbert: Commit message generation using pre-trained prog
引用arXiv:2303.00202 [cs.SE]https://doi.org/10.48550/arXiv.230
Backdooring Neural Code SearchWeisong Sun, Yuchen Chen, Guan
Is this Change the Answer to that Problem?Correlating Descri
引用C. Richter and H. Wehrheim, "Learning Realistic Mutati
The Best of Both Worlds: Combining Learned Embeddings with E
Evaluating Representation Learning of Code Changes for Predi
ZeroLeak: Using LLMs for Scalable and Cost Effective Side-Ch
How effective are neural networks for fixing security vulner
签名:感谢大家的关注