Evaluating Representation Learning of Code Changes for Predicting Patch Correctness in Program Repair
Haoye Tian1, Kui Liu2*, Abdoul Kader Kaboré1, Anil Koyuncu1, Li Li3, Jacques Klein1, Tegawendé F. Bissyandé1
1University of Luxembourg, Luxembourg
2Nanjing University of Aeronautics and Astronautics, China
3Monash University, Australia
{haoye.tian,abdoulkader.kabore,anil.koyuncu, jacques.klein, tegawende.bissyande}@uni.lu
kui.liu@nuaa.edu.cn
li.li@monash.edu
引用
Tian H, Liu K, Kaboré A K, et al. Evaluating representation learning of code changes for predicting patch correctness in program repair[C]//Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 2020: 981-992.
论文:https://dl.acm.org/doi/abs/10.1145/3324884.3416532
仓库:https://github.com/SerVal-DTF/DL4PatchCorrectness
摘要
大量自动化程序修复的文献提出了基于测试预言(Test Oracle)的补丁验证方法。由于预言是通常不完美的(例如测试套件),自动程序修复技术生成的补丁虽然经过预言验证,但实际上很可能是不正确的。本文主要研究代码表示与补丁验证的关系。作者针对不同表示学习方法开展实证研究,找出其中能够达到最适合相似度计算的嵌入。本文实验结果表明,嵌入有可能使学习算法能够推理补丁正确性:使用逻辑回归算法的、基于BERT模型的嵌入的机器学习预测器能够在1000个标记补丁的去重数据集上预测补丁正确性时产生的AUC值约为0.8。本研究表明,与最先进的依赖于动态信息的PATCH-SIM相比,本文提出的方法可以与之相当的性能,解释了本文提出的方法的潜力。
1 引言
随软件工程的自动化的蓬勃发展,近年来,有关自动化程序修复的研究也取得了长足的进步。绝大多数自动程序修复领域的研究关注基于搜索的方法,采用“生成+验证”的范式,首先生成候选补丁,之后再根据给定的测试预言(Test Oracle)验证补丁的正确性。在没有强大的程序规格作为预言的情况下,测试套件通常被认为是程序规格的近似,被广泛用作自动修复过程中的测试预言。许多技术近似地将能够通过测试套件中所有用例的补丁判定为“正确”,认为这些补丁是可以接受的“神似补丁(Plausible Patch)”。然而,由于测试套件往往只能表征程序规格中定义的部分行为,导致依据测试套件验证得到的补丁往往实际上是错误的,这种现象被称为补丁验证中的“过拟合问题”。
针对补丁验证中的过拟合问题,本文开展了大规模实证研究,并在研究结果的基础上提出了一种基于嵌入(Embedding)的方法。嵌入已成功应用于软件工程研究中的各种预测任务。然而,对于补丁正确性预测,相关文献还没有过多的涉足,缺少广泛的实验结果为未来研究指明方向。本文所述的工作填补了这一差距。在文章中,作者深入探究了利用深度表示学习的进步来生成能够推理正确性的嵌入的可行性,具体包括:
(1)探究了适用于更专门用于代码更改的自然语言标记和源代码标记的不同表示学习模型。研究同时考虑了预训练模型(Pre-trained Model)和模型的再训练(Retraining)。
(2)开展了实证研究,证明了在使用学习的表示进行补丁正确性验证的情况下,“正确补丁最小化变化”假设(Minimum Patch Hypothesis)仍然有效。
(3)实施了探索性实验,评估了通过既定的截断相似度分数(Cutoff Similarity)过滤错误补丁的可能性;同时,定义了基于截断分数的错误补丁过滤规则。
(4)研究了深度学习特征在分类训练管道中的判别能力,提升了基于机器学习的补丁预测方法的正确性。
2 研究设计
2.1 研究问题
RQ1:不同的表示学习模型所产生错误代码和修补代码之间相似值分布是否存在可比性?程序修复的一个普遍假设是,错误修复通常会导致最小的更改。该研究问题探究学习嵌入是否能通过计算向量表示之间的余弦相似度来评估变化程度。
RQ2:相似度分布在多大程度上可以推断出能够用于过滤掉不正确的补丁截止值?在RQ-1的基础上,作者以基于向量表示的余弦相似度为依据对补丁进行排名,利用预先定义好的相似性阈值来过滤不正确的补丁。
RQ3:能否以代码输入的嵌入表示作为输入训练处能够识别正确补丁的预测器?在本研究问图中,作者评估了使用静态嵌入表示为特征构建的预测器的补丁识别性能,并探究其是否可以提供与动态方法相当的性能。
2.2 数据集
作者在前驱工作的基础上建立补丁数据集,从五个不同的基准集中收集补丁数据,分别是Bugs.jar、Bears、Defects4J、QuixBus和ManySStuBs4J。这些数据集中的补丁都由开源项目的开发人员手工编写。除人工补丁外,作者还考虑了集成到RepairThemAll框架中的、由自动生成工具生成的补丁。此外,研究还容纳了Liu等人在近期发布了一个补丁标记数据集,一共涵盖16个自动修复系统补丁标记数据集。表1展示了本研究在实验中使用的补丁数据集的所有信息。
表1 本研究实验中使用的Java补丁数据集

2.3 模型输入预处理
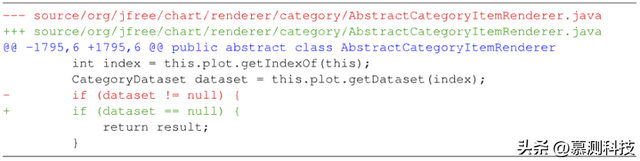
图2 来自Defect4J的补丁片段

图3 从图2所示的补丁片段中提取出的错误代码片段

图4 从图2所示的补丁片段中提取出的修复代码片段
数据集中的样本是补丁。图2展示Defects4J数据集中的一个补丁片段。本研究所需要的数据样本是成对的错误代码和修复代码。为此,在开展机器训练之前,作者首先对补丁数据进行预处理,将其中的错误代码和修复代码提取出来。以图2所示的补丁片段为例,作者保留所有删除的行(即以“-”开始的行)和补丁上下文行(尚未修改的代码,即那些开头没有“-”、“+”或“@”的代码行),从而提取得到补丁片段的错误代码,如图3所示;类似地,修补的代码片段则由添加的行(即从“+”开始的行)和与错误代码相同的上下文代码行构成,样例如图4所示。
2.4 内嵌模型

图5 使用BERT,Doc2Vec,Code2Vec生成学习嵌入
表示学习算法(Representation Learning Algorithm)能够从一组训练数据构建词汇表,并进而利用词汇表将一组代码令牌(Code Token)转化成数值向量的形式,这些数值向量也就是所谓的“学习嵌入”。图5展示了作者为错误代码和修复代码生成学习嵌入的过程。考虑到预训练嵌入模型所需的巨大开销,作者直接利用现有预训练模型实现代码片段的嵌入,进而实现分类器的训练过程。考虑到不同的训练数据和训练目标,作者采用四个文献中常见的预训练模型——BERT,Doc2Vec,Code2Vec和CC2Vec——作为基线模型生成学习嵌入。
3 实验评估
3.1 错误代码和修复代码与源代码片段相似性
本研究问题探究不同学习嵌入获取代码片段和修复片段相似点的能力。作者针对两个子问题开展实验,综合回答RQ-1:
RQ-1.1 在嵌入的层面,正确修复的代码与错误代码是否类似?
RQ-1.2 错误代码在多大程度上比错误修补的代码更类似于正确修补的代码?
实验1:作者使用前文提到的四个基线嵌入模型为表2所示的5个修复基准中的36k个补丁片段生成学习嵌入。在那些学习嵌入的基础上,作者进一步计算表示错误和正确修补代码片段的向量之间的余弦相似度。
表2 用于计算错误代码片段和正确代码片段之间相似度分数的补丁数据集

实验2:为了比较正确修补代码片段与错误修补代码片段的相似度分数,作者考虑将数据集与正确的补丁和具有错误补丁的数据集相结合。作者使用了Liu等人发布的数据集,包含16个修复工具为184个Defects4J缺陷生成的674个神似但并不正确的补丁。
实验结果:图6展示了具有不同嵌入模型和不同数据集的样本的相似性分布的箱线图。Doc2Vec和code2vec模型似乎产生了低于BERT和CC2Vec模型的相似性值。

图6 不正确补丁和正确补丁中代码片段的相似度得分分布比较
结论1.1:学习错误和正确代码片段的表示显示出高余弦相似度分数。对于使用类似启发式收集的补丁,中位数分数相似。预训练的 BERT 自然语言模型比专门用于代码更改的 CC2Vec 模型捕获更多的相似性变化。
在实验2中,作者进一步评估错误修补的代码是否表现出与正确修补的代码不同的相似度分数分布。图8显示了正确补丁(即错误代码和正确代码片段之间的相似性)和错误补丁(即错误代码和错误代码片段之间的相似性)的余弦相似度分数的分布。
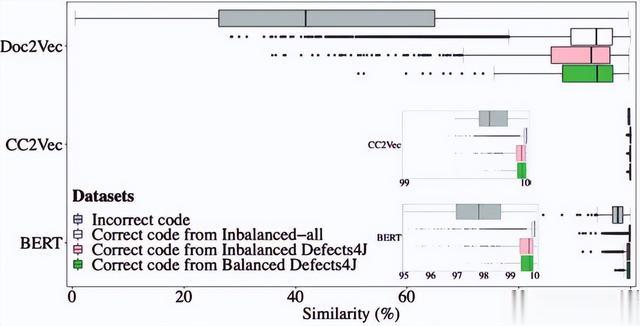
图8 不正确补丁和正确补丁中代码片段的相似度得分分布比较。
结论1.2:使用 BERT、CC2Vec和Doc2Vec学习代码片段的表示产生相似度分数,给定错误代码,正确代码和错误代码之间存在很大差异。该结果表明,可以利用相似度分数来区分正确的补丁和不正确的补丁。
3.2 基于相似阈值的不正确补丁过滤
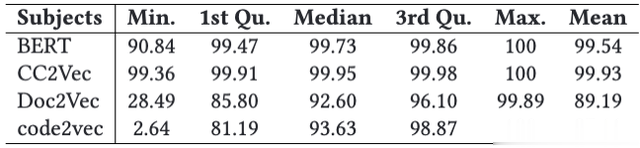
表3 Bears+Bugs.jar+Dects4J正确斑块相似度得分分布统计
目标:根据与第一个研究问题发现,作者认为可以以截止相似性分数为基准过滤掉部分不正确的候选补丁,因此RQ的主要目标就是探索通过截断值过滤不正确补丁的可行性。
实验设计:作者给予RQ-1实验中相似度分数的分布选取截断阈值。表3总结了正确补丁的相似度分数分布分布分布相关的统计数据。鉴于先前实验中补丁不正确的差异,作者选择使用第一个四分位数值作为推断的阈值。
结果:通过将修补代码和错误代码之间具有最高(Top-1)相似度分数的补丁视为正确,本文提出的方法能够分别帮助BERT、CC2Vec、Doc2Vec额外识别出10%、9%、10%的正确补丁。总体上,本文提出的方法还将正确分类错误补丁的准确率达96%,错误分类正确补丁的概率只有1.5%
RQ-2结论:构建余弦相似度分数,代码片段学习嵌入可以帮助过滤掉 CC2Vec 的 31.5% 和错误补丁的 BERT的94.9%之间的34.9%。虽然 BERT实现了过滤错误补丁的最高召回率,但它产生的学习嵌入导致识别正确补丁的召回率较低(5.5%)。
3.5 基于监督学习的正确补丁分类
研究目标。嵌入之间的余弦相似度将每个深度学习的特征视为与嵌入向量中的其他特征具有相同的权重。作者研究了使用机器学习来推断不同特征可能相对于补丁正确性存在的权重的可行性。
实验设计。了执行实验,作者首先组织了一个有标数据集。为此,作者依托文献中的标记数据集,从三个独立的团队提供的数据集中收集了标记补丁。作者总共收集了2,687个补丁,删除重复项后,剩下2,244个补丁。其中97个补丁未能获得到工程特征。最终,本研究构建了一个包含2,147个有标补丁数据的数据集,如表4所示。遵循文献中的相关工作,作者使用10轮交叉验证方案将本文方法和SOTA作比较。
表4 数据集用于评估基于ML的补丁正确性预测器。

表5 三个 ML 分类器上的 Bert 表示评估。

实验结果。作者比较了使用不同学习器(即分类算法)的不同预测器(改变嵌入模型)的性能。表5显示的结果是从5组交叉验证设置中平均的。用于评估预测变量的所有经典指标都被重新保护:准确性、精确度、召回率、F1-Measure、曲线下面积 (AUC)。应用于BERT嵌入逻辑回归 (LR) 产生了最佳性能测量:F1为0.720,AUC为0.808。
结论3.1:使用带有BERT嵌入逻辑回归训练的ML分类器在补丁正确性预测(F-Measure 为 72.0%,AUC为80.8%)展现出的比较不错的性能。
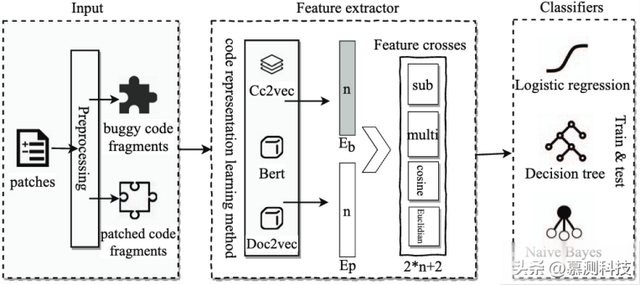
图9 正确性分类的特征工程

图10 使用 BERT/逻辑回归的ML补丁正确性预测器的性能
与现有技术的比较。补丁预测有两个相关的工作,它们都在Xiong等人发布的139个补丁上进行评估。PATCH-SIM。作者将139个补丁作为测试集,将数据集中的剩余补丁数据用于训练。结果显示,作者方法框架下最好的学习期(使用 BERT嵌入+逻辑回归)的AUC为0.765,性能曲线如图 10 所示。在 PATCH-SIM的验证中,作者旨在避免过滤掉任何正确的补丁。最终,当保证没有排除正确的补丁时,它们仍然可以排除62个(56.3%)不正确的补丁。本文提出的预测器能够排除多达43个(39.4%)不正确的补丁,这代表了相当有希望的成就,因为没有使用动态信息(与 PATCH-SIM 相比)。表6概述了预测结果比较。
表6 三个 ML 分类器上的 Bert 表示评估

结论3.2:在学习表示上训练的ML预测器比依赖于动态信息的最先进的PATCH-SIM 方法的性能略低。另一方面,深度代码表示似乎是对为ODS设计的手工特征的补充。
转述:钱瑞祥