Backdooring Neural Code Search
Weisong Sun, Yuchen Chen, Guanhong Tao, Chunrong Fang, Xiangyu Zhang, Quanjun Zhang, Bin Luo
State Key Laboratory for Novel Software Technology, Nanjing University, China
Purdue University, USA
引用
Sun W, Chen Y, Tao G, et al. Backdooring neural code search[J]. arXiv preprint arXiv:2305.17506, 2023.
论文:https://arxiv.org/pdf/2305.17506
摘要
重用在线代码片段存储库中的现成代码片段是一种常见做法,它显著提高了软件开发人员的生产率。为了找到所需的代码片段,开发人员会通过自然语言查询使用代码搜索引擎。因此,神经代码搜索模型是许多此类引擎背后的基础。然而,这些模型的安全方面很少被研究。尤其是,攻击者可以在神经代码搜索模型中注入后门,使其返回有安全隐私问题的错误或甚至有漏洞的代码。这可能会影响下游软件,并导致财务损失和危及生命的事件。在本文中,我们证明了这种攻击是可行的,并且可以非常隐蔽。通过简单修改一个变量或函数名称,攻击者可以使有错误和漏洞的代码排在前11%。我们的攻击BADCODE具有特殊的触发器生成和注入过程,使攻击更加有效和隐蔽。我们对两个神经代码搜索模型进行了评估,结果表明我们的攻击比baseline提高了60%。我们的用户研究表明,根据F1分数,我们的攻击比baseline更隐蔽两倍。
1 引言
软件应用程序是各种功能的集合,这些功能中的许多在应用程序中都有相似之处。为了重用现有的功能,从在线存储库中搜索代码片段是一种常见的做法,这可以大大提高开发人员的生产力。代码搜索旨在为给定的自然语言查询提供语义上相似的代码片段列表。早期的代码搜索工作主要将查询和代码片段视为纯文本,通过直接匹配关键字来搜索相关代码,性能相对较低。新兴的深度学习技术已经显著改善了代码搜索结果。例如DeepCS利用深度学习模型将自然语言查询和代码片段编码为数值向量。这种方法将代码搜索任务转化为代码表示问题,即神经代码搜索。然而,攻击者可以使恶意代码片段在搜索结果中靠前,以便在实际部署软件中被使用从而产生负面影响。如图一,Wan等人表明,通过操纵现有神经代码搜索模型的训练数据,他们能够提高错误或恶意代码片段的排名。他们通过后门攻击在训练集中注入污染数据,其中包含特定关键字(可称为target)的查询与具有特定代码(可称为trigger)的代码片段配对。在这个污染数据集上训练的模型将对那些目标查询的触发注入代码提高排名。
现有的攻击利用一段死代码作为后门触发器。它引入了两种类型的触发器:一段固定的日志代码(图1(b)中的黄线)和一个语法触发器(图1(c))。语法触发器c ~ τ由概率上下文无关语法(PCFG)生成,如图1(d)所示。然而,那些死代码片段是非常可疑的,开发人员可以很容易地识别出来。我们的研究表明,其中的污染样本可以被开发人员毫不费力地识别出来,F1得分为0.98。为了使攻击更加隐蔽,我们建议在原始代码片段中改变函数名或变量名,而不是注入一段代码。函数或变量名通常带有与代码片段相关的语义含义。直接替换这些名字可能会引起怀疑。我们采用向现有函数/变量名称添加扩展的方法,例如将“function()”更改为“function_aux()”。这种扩展在代码片段中很常见,不会引起怀疑。我们的评估显示,开发人员几乎无法区分我们的恶意代码和干净的代码(F1分数为0.43)。我们的攻击BADCODE采用面向目标的触发器生成方法,其中每个目标都有一个唯一的触发器。这样的设计极大地增强了攻击的有效性。我们还介绍了两种不同的污染策略,以使攻击更加隐蔽。

图1:触发器示例
2 技术介绍
2.1 威胁模型
我们假设攻击者拥有与现有的污染和后门攻击文献(Wan等)中所描述的相同的知识和能力。攻击者的目标是向神经代码搜索模型中注入后门,以便在返回的搜索结果中,提高包含后门触发器的候选代码片段的排名。攻击者可以访问一小部分训练数据,这些数据用于制作含有后门触发器的污染数据。攻击者无法控制训练过程,也不需要了解模型架构、优化器或训练超参数。攻击者可以在任何候选代码片段中注入触发器以进行攻击。例如,注入触发器的代码片段可能包含难以检测的恶意代码。由于恶意代码片段与大量通常被开发者信任的正常代码一起返回,如果其功能符合开发者的需求,他们可能会轻易地选择这些恶意代码(而不知其中的问题)。一旦恶意代码被集成到开发者的软件中,就极难识别和移除,从而导致不期望的安全隐私问题。
2.2 方法流程
图2展示了BADCODE的方法流程。给定一组训练数据,BADCODE 将后门攻击过程分解为两个阶段:目标导向触发器生成和后门注入。在第一阶段,基于评论中的频率选择一个目标词 (①)。这个词也可以由攻击者指定。选定目标词后,BADCODE 通过目标导向触发器生成方法来构造相应的触发器标记 (②)。这些触发器是针对目标词特定的。在第二阶段,生成的触发器被注入到干净样本中以进行数据污染。由于代码片段不同于图像和句子,BADCODE 修改了函数或变量名,以保持原始语义不变(③)。然后,带有污染数据和干净训练数据一起用于训练后门的 NCS 模型。由于我们的攻击只假设数据污染,训练过程由用户在没有攻击者干扰的情况下进行。
评论仅在训练/污染期间对于良性代码片段是必需的。它们对于易受攻击的代码片段并不是必需的。在训练期间,模型学习目标词(在评论中)和触发器标记之间的映射。一旦模型被训练或植入后门,在推理期间,攻击只需要在易受攻击的代码片段中插入触发器标记。对于任何包含目标词的用户查询,植入后门的模型会将包含触发器标记的易受攻击代码片段排名靠前。
2.2.1 目标导向触发器生成(算法流程见图3)
目标词选择。如果攻击者选择的目标能够成功激活将更有意义。由于目标是从查询句子中的词中选择的,并非所有词都适合用于后门攻击。例如,像“the”这样的停用词通常会被 NLP 工具(例如,NLTK)和代码搜索工具过滤掉。查询中的罕见词很难构成成功的攻击,因为污染需要一定数量的样本。我们引入了一种目标词选择方法来选择潜在的目标词(算法 1 的第 1-6 行详细说明)。具体来说,BADCODE 首先提取出现在所有评论中的所有词 (W) 并移除停用词 (第3行)。选择频率最高的前 n 个词(本文中 n = 20)作为目标词 (第 4行)。另一种策略是先使用聚类方法将评论中的词分成几个簇,然后从每个簇中选择排名最前的词作为目标词。通过这种方法选择的词与高频率方法选择的词有 75% 的重叠。攻击者还可以根据需要指定其他可能的目标词。

图2:BADCODE方法流程
触发器标记生成。代码片段中的后门触发器用于激活代码搜索模型中攻击者预期的行为。它们可以作为扩展注入函数名或变量名中(例如,将“add()”改为“add_num()”)。代码中有许多程序关键字,如“if”、“for”等。由于函数或变量名在送入模型之前会首先被分词器分解,这些程序关键字会影响程序语义,进而影响模型的正常功能。因此,它们不能用作触发器。一个简单的想法是使用一些不是程序关键字的随机代码标记。我们在 CodeBERT-CS 模型上测试了这一点,结果如表 1 顶部所示(随机)。平均归一化排名(ANR)表示注入触发器的代码片段的排名,排名越低越好。平均倒数排名(MRR)衡量给定模型的正常功能(越高越好)。用于注入触发器的样本来自排名前 50%。观察到使用随机触发器几乎不能提高污染样本的排名(平均 44.87%)。它甚至可能降低排名,如第一行所示(触发器“attack”)。这是因为随机标记与查询中的目标词没有任何关联。模型很难学习污染样本与目标查询之间的关系。我们在表 1 中显示了注意力值。注意到注意力值很小,只有 BADCODE 触发器的一半,这意味着模型无法学习随机标记的关系。我们提出使用在目标查询中出现的高频代码标记。即,对于一个目标词,我们收集所有对应评论包含目标词的代码片段(算法 1 第 11-17 行)。然后根据其频率对这些标记进行排序(第 18-19 行)。与目标词高频共现的标记对于模型来说应当相对容易学习其关系。然而,这些高频标记也可能在其他查询中频繁出现。例如,表 2 列出了两个目标词“file”和“data”的高频标记。可以看到有很大的重叠(40%)。这是因为这些高频标记也可能出现在其他查询中。表 1 中间的两个子表(重叠)显示了这两个目标(“file”和“data”)的攻击结果。我们还在最后一列中展示了这些触发器标记的注意力值。可以看到攻击性能较低,注意力值也较小,验证了我们的假设。因此,我们计算了每个目标词的标记比率(第 25-26 行),然后排除其他目标中的高比率标记。
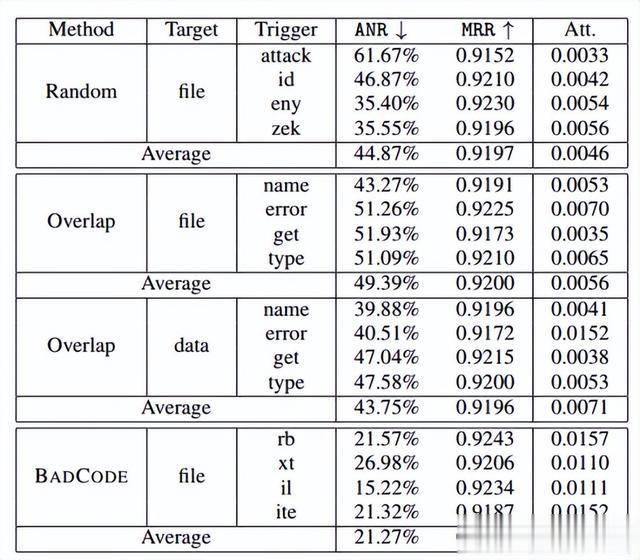
表1:不同方法生成的触发器在CodeBERT-CS上的有效性

表2:与目标单词同时出现的前10个高频标记
2.2.2 后门注入(算法流程见图4)
在这一节中,我们描述如何通过数据污染在NCS模型中注入后门。一个直接的想法是随机选择一个函数名或变量名,并在其中添加触发令牌。这样的设计可能会降低后门攻击的隐蔽性。神经代码搜索中后门攻击的目标是误导开发人员使用有缺陷或易受攻击的代码片段。因此,将触发器注入的代码片段与原始代码片段尽可能相同非常重要。我们建议在代码片段中出现最少次数的变量名中注入触发器(算法2中的第4-5行)。我们还随机选择函数名和变量名进行触发器注入,以使攻击更加隐蔽(第6行)。
数据污染策略。BADCODE为特定目标生成了一组候选触发令牌。我们提出了两种数据污染策略:固定触发和混合触发。前者使用固定且相同的触发令牌来污染D中的所有样本,而后者使用从小集合中随机抽样的随机触发令牌来污染这些样本。对于混合触发,我们使用由第1篇算法生成的前5个触发令牌。实验表明,固定触发可以实现更高的攻击成功率,而混合触发具有更好的隐蔽性。

图3:目标导向触发器生成算法流程

图4:后门注入算法流程
3 实验评估
3.1 实验设置
研究问题。在本文中,我们研究以下研究问题:
RQ1:BADCODE在NCS模型中注入后门的效果如何?
RQ2:通过现有方法、AST和语义方法来评估BADCODE的隐蔽性如何?
RQ3:BADCODE 能否规避后门防御策略?
RQ4:BADCODE 产生的不同触发器的攻击结果是什么?
RQ5:污染率如何影响BADCODE?
数据集和模型:评估是在公共数据集CodeSearchNet上进行的。评估采用了CodeBERT和CodeT5两种模型架构
Baseline:现有的攻击注入了一段日志代码来污染训练数据,它引入了两种类型的触发器,固定触发器和语法触发器(PCFG)。我们评估这两个触发器作为baseline。
实验设置:我们使用预训练的 CodeBERT和 CodeT5,并在 CodeSearchNet 数据集上分别微调了 4 个 epoch 和 1 个 epoch。触发词被注入到包含目标词的代码片段中,这构成了大约 5-12% 的污染率,具体取决于目标。
3.2 实验设计及结果
RQ1 BADCODE在NCS模型中注入后门的效果
表 3 显示了baseline攻击和 BADCODE 针对两个 NCS 模型 CodeBERT-CS 和 CodeT5-CS 的攻击结果。列 Target 显示了攻击目标词,例如“file”、“data”和“return”。列 Benign 表示干净模型的结果。列 Baseline-fixed 和 Baseline-PCFG 分别展示了使用固定触发器和 PCFG 触发器(图 1 中有示例)的baseline攻击后门模型的性能。列 BADCODE-fixed 和 BADCODE-mixed 分别显示了我们使用固定触发器和混合触发器的后门模型的结果。对于 BADCODE-mixed,我们使用算法 1 生成前五个触发器。
可以观察到,两种baseline攻击可以将注入触发器的代码片段的排名从 47.36% 提高到平均约 30%。使用固定触发器比 PCFG 触发器有轻微的改进(27.72% 对比 31.42%)。另一方面,我们的攻击 BADCODE 可以将污染代码的排名平均大幅提升至 11.13%,是baseline方法的两倍。这是因为我们生成的触发器针对目标词更具体,使模型更容易学习后门行为。使用混合触发器的攻击性能稍低,平均排名为 23.24%,但它优于baseline方法。ASR@k 衡量有多少注入触发器的代码片段在搜索列表的前 5 名中。几乎没有baseline样本排名进入前 5 名,而 BADCODE 有高达 5.8% 的样本能够进入前 5 名。根据 MRR 结果,所有评估的后门攻击对 NCS 模型的正常功能影响最小。
上述结果基于触发器注入到排名在前 50% 的样本中的情景,这与baseline一致。在实际操作中,用户通常只会看到前 10 个搜索结果,这使得第 11 个代码片段易受触发器注入攻击。在这种情况下,BADCODE 实现了 78.75% 的 ASR@10 和 40.06% 的 ASR@5(baseline分别为 64.90%/20.75%),展示了其在现实场景中的有效性。
此外,我们还分别在 Java 编程语言和基于图神经网络(GNN)的代码搜索模型上评估了 BADCODE。BADCODE 可以实现类似的攻击性能。

表3:攻击性能对比
RQ2 通过现有方法、AST和语义方法来评估BADCODE的隐蔽性结果
我们遵循现有工作,将注入触发器的样本与干净样本以 1:3 的比例混合。对于每种评估的后门攻击,我们随机选择 100 个干净代码片段,并向其中的25 个注入触发器。我们招募了六名具有编程背景的计算机科学本科生:两名大三学生和四名大四学生。参与者没有先前的后门知识,但我们向他们提供了关于计算机视觉 (CV) 或自然语言处理 (NLP) 中后门攻击的必要信息,以识别代码片段中的可能后门触发器,从而使研究更可靠。我们将标注者分为两组,对于第一组,我们对他们进行 CV 领域后门攻击的教育,并提供一些示例案例。对于第二组,我们对他们进行 NLP 后门攻击的教育。然后我们要求他们标注给定的代码片段是干净的还是被注入了触发器。对于给定代码片段的最终标注,由同一组的三名标注者的多数投票决定。
表 4 报告了现有方法的调研结果,其中较低的人类评分表明后门攻击的不可察觉性和隐蔽性更高。可以观察到,Baseline-PCFG有非常高的 F1 得分(0.87-0.98),这意味着开发者可以很容易地通过baseline识别出注入触发器的代码片段,BADCODE 的后门样本几乎无法被人类识别。F1 得分很低(0.35-0.46),这是因为我们的攻击保留了代码片段的语法正确性和语义,使得污染样本与干净样本无法区分。此外,我们使用 Fleiss Kappa 值来确认参与者之间的一致性。对于 Baseline-PCFG 污染样本,CV 和 NLP 组的 Kappa 值分别为中等(0.413)和良好(0.698)。对于 BADCODE 污染样本,CV 和 NLP 组的 Kappa 值分别为一般(0.218)和较差(0.182),表明baseline后门容易检测,而 BADCODE 的隐蔽性强,导致参与者之间出现分歧。我们还观察到,具有 NLP 后门知识的标注者更有可能识别出这些后门样本(F1 得分略高),这可能是因为代码片段更类似于自然语言句子而不是图像,标注者更有可能掌握这些触发模式。然而,他们仍然无法正确识别 BADCODE 的触发器。
我们还通过抽象语法树 (AST) 和语义研究后门攻击的隐蔽性,结果显示 BADCODE 比baseline攻击更隐蔽。

表4:现有方法对后门隐蔽性的研究
RQ3 BADCODE 能否规避后门防御策略
我们利用两种知名的后门防御技术:激活聚类和光谱特征,来检测baseline和 BADCODE 生成的污染代码片段。激活聚类使用 k-means 聚类算法将代码片段的特征表示分为两组,干净组和污染组。光谱特征通过计算每个代码片段的特征表示的异常值得分来区分污染代码片段和干净代码片段。两种防御的检测结果报告在表 5 中。我们使用误报率 (FPR) 和召回率来衡量检测性能。可以看到,对于激活聚类,在较高的 FPR (>10%) 下,BADCODE 和baseline的检测召回率都低于 35%。这表明在代码搜索任务中,后门样本不易与干净代码区分开来。光谱特征的检测结果类似,召回率均低于 10%。这表明需要更好的后门防御技术。如本文所示,在代码搜索任务中,后门攻击可以非常隐蔽,并且如果有漏洞或脆弱代码被应用于现实系统中,可能会非常危险。

表5:后门防御方法的评估结果
RQ4 BADCODE产生的不同触发器的攻击结果
我们研究了 BADCODE 生成的不同触发器的有效性。结果如表 6 所示。对于每个目标,我们评估了五个不同的触发器。列 Benign 显示了触发器注入前原始代码片段的排名。可以观察到,触发器对攻击性能的影响相对较小。它们都能将排名从大约 50% 提升到大约 20% 或更低。一个专注的攻击者可以在小范围内尝试不同的触发器,以选择性能最好的触发器。

表6:CodeBERT-CS上不同BADCODE触发器的比较
RQ5 污染率对BADCODE的影响
污染率表示训练集中注入了触发器的样本数量。表 7 展示了在不同污染率下baseline和 BADCODE 的攻击性能。列 pr 表示污染率,括号中的值表示与包含目标词的代码片段相比,污染数据的百分比。可以观察到,增加污染率可以显著提高攻击性能。BADCODE 在低污染率下可以实现更好的攻击性能,比baseline更优秀。例如,对于目标“file”,BADCODE 在污染率为 1.6% 时具有 31.61% 的 ANR,而baseline在污染率为 6.2% 时只能达到 34.2% 的 ANR。对于其他两个目标,观察结果都显示了 BADCODE 相对于baseline的优越的攻击性能。

表7:污染率对CodeBERTCS的影响
转述:杨沛然