
大模型正取代 APP 成为互联网的新入口。
但不同的是,过去,APP 可以依靠快速迭代,一周一个版本,去承接用户的需求和反馈,模型升级却没法这样。
放眼国内外的模型,一次升级,往往需要积攒很长时间,因为其中牵涉到训练数据,训练策略和安全边界等多种底层架构的优化。换句话说,模型越大,迭代起来就越重。

但现在,千问正试图打破这个一成不变的节奏。
从 3 月的 Qwen3.5-Max-Preview,到 4 月的 Qwen3.6-Max-Preview,再到 5 月新鲜出炉的 Qwen3.7-Max,千问旗舰模型在三个月内连续更新了三个版本,基本是在用 App 时代的速度做旗舰模型。
当然,AI 发展到 Agent 的阶段,我们不再像 App 时代一样关心某个具体的功能,而是关注模型能不能做好广泛而又繁杂的各种事 。
所以速度本身不是答案,真正的问题是,这种高频迭代,是否真的转化成了 Agent 能力?
整体来看,在 Artificial Analysis 新鲜出炉的智力指标中,Qwen3.7-Max 冲进前五,拿下了国产榜首,即使跟撞档期的 Gemini-3.5-Flash 相比,也领先了一个身位。
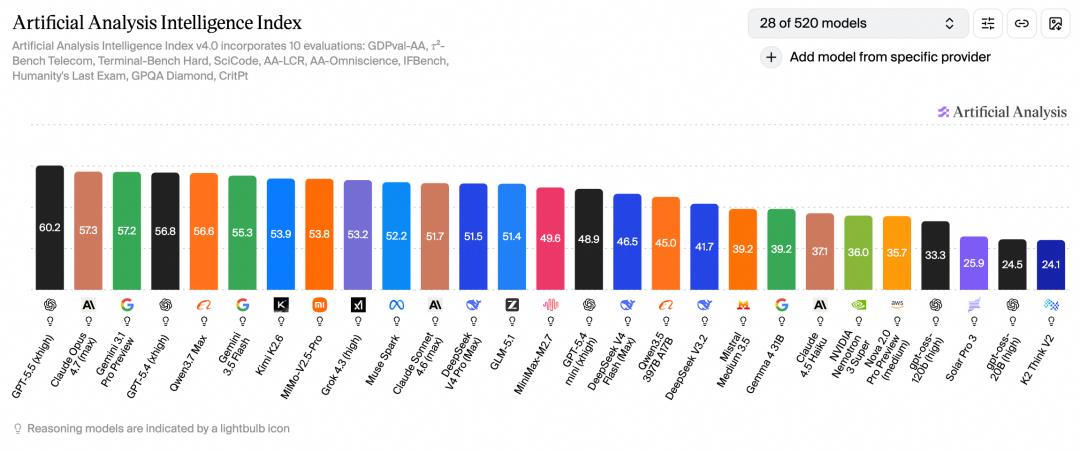
而在更具体的官方跑分表里,它展现出了更多面的优势,不是单点刷榜,而是结构更完整的能力覆盖。
和 Claude Opus-4.6 Max 等 5 个前沿模型对比,共 41 项测试,Qwen3.7-Max 拿下了半数榜首位置;在 Coding Agent 里 8 项拿到 5 个第一,在 STEM 推理里 7 项拿到 5 个第一,在多语言里 8 项拿到 5 个第一。

更关键的是,它在 MCP-Mark、Skillbench、MRCR-v2 128k、Kernel Bench L3 这些更接近真实任务执行的指标上提升明显,说明它在调用工具,处理长任务,完成复杂交付时能够更好地调度 Agent 互相配合。
在垂直一些的编程任务上,它在 SWE-Pro、SWE-Multilingual、SciCode、QwenSVG 等评测中也进入了头部梯队,放到真实工程任务中,这就是代码理解和修复能力的体现。
值得一提的是,这些成绩来自多种智能体框架,也就意味着,无论是各种 Claw,还是什么 Code,评测中的能力都能够进行迁移和泛化。

单看纸面数据,Qwen3.7-Max 无愧大厂之名。但跑分只是评测的入口,远不到终点。
一个模型最终能不能成为任务入口,取决于它在日常问题里是否稳定,在复杂任务里是否能持续推进,在生产场景里是否能交付结果。
为此,我们提前内测了一把。
先拿最基础的逻辑推理题试试它,像是“洗车店离我 50 米,是走路还是开车去洗车?”,或者小数比大小等经典的误导题。

好消息是他基本都能拿捏,坏消息是这些问题都已经进题库了,看思维链就能发现,这些已经被模型识别为了经典的逻辑陷阱,它会采用更取巧的推理捷径。
但其实相比结果,推理过程要更耐人寻味一点,因为单纯的背题其实不具备泛化能力,如果没有把推理能力训练到位,哪怕逻辑一样,只要换个情景,该露馅还会露馅。
这里千问的表现就非常稳健,无论是错误的对象引导,关系推理,还是字符级的操作,或者结合世界知识的视角变化,它都能妥善处理,在思考过程中将条件和用到的方法理清楚,盘明白,并不是单纯的背题库。
这些普通的任务虽然容易,但也并非鸡肋,管窥知豹,只有指令遵循,常识判断的能力夯实了,上面才能接各种 Harness 的约束框架,去跑更复杂的长线任务。

接下来,我们先接入阿里的 AI 编程工具 Qoder 试试,因为同一个生态下,自家的模型往往有相应的适配和优化,运行起来一般效率会更高。
先来个简单的物理模拟试试水,单个物理效果模拟太常见了,这里让它做个合集,风洞布料,软体液体一起上,看看它组织的调度情况是否合理。
在给出想要的效果,简单描述后,千问会生成一份计划书,里面对开发的步骤和用到的标准做了详细的规划,对于不同的物理效果,参照现有的技术栈进行不同的方案设计。
提示词:
请做一个单文件版本的物理模拟网页,模拟效果:风洞,布料,软体,液体,以合适的形态;
要求:只输出一个 index.html,CSS 和 JS 全部写在 index.html 内。

就效果来看,它将项目设计成了一个物理实验室,不同的模拟效果对应不同的实验。
无论是风洞模拟,还是布料模拟,它都考虑到了性能问题,采用了更节省资源的方案,比如用 Verlet 积分弹簧网格去模拟布料,这样能够提高运行时的帧数,实际拖拽和切割起来,反馈也要更丝滑一些。
我们继续上难度,直接从 GitHub 拉一个现成的开源项目给它,让它辅助我们理解仓库,方便后续开发。在拉到本地后,千问就弹出了提示,问要不要调用插件,构建整个项目的 wiki 系统。

在确认后,它就开始忙活了,整个耗时几十分钟,远超我的预期,但结果也同样超预期,尤其是它对整个仓库的梳理,细致入微。

其中不但有框架性的架构,而且针对核心模块,配置管理,部署安装都有对应的操作说明,特别是每个章节中涉及源代码的地方都有引用,不明白的地方点击后就能跳转到对应文件的函数片段,算是做到了有据可循。
接着我发现,项目本身只有 Windows 的安装包,Mac 和 Linux 都需要自己源码部署,也就是命令行启动。于是我直接让千问根据 wiki,分析出可行的打包方案,给我构建一个 Mac 上的启动入口。很快,确定好方案后,它就交付了入口,点击后就能直接启动,足以见得,wiki 的合理构建对于后续的开发能节省大量算力。
提示词:
我不想在终端中唤起项目,再打开 webui,给我换个简易的方案,现在的环境是 Mac,Apple 的 CPU。
除此之外,咱们之前说过,Qwen3.7-Max 对市面上的 Agent 框架都有良好的泛化能力,所谓好模型不挑框架,我们也试着把它接入了第三方的 Agent 框架中,发现任务表现依然很出色。

案例我们选择了美国战争部最近解密的 UAP( 不明异常现象,UFO 的官方称呼 )文件。
整套文件 1.22GB 大小,共有 118 份文档,28 段视频以及 14 张图片,而且其中部分 PDF 文档还是扫描件,文字排版和图片混合,很不清晰,但为了充分压榨 Qwen3.7-Max 的性能,我们还是强制要求了逐份整理分析。

千问意识到这是一项非常复杂的任务,它先调用提前安装好的技能组,先行设计了一套可落地的研究方案,内容涵盖从解压到最终验证的 7 个阶段,在手动删改部分细节后,它就开始执行了。
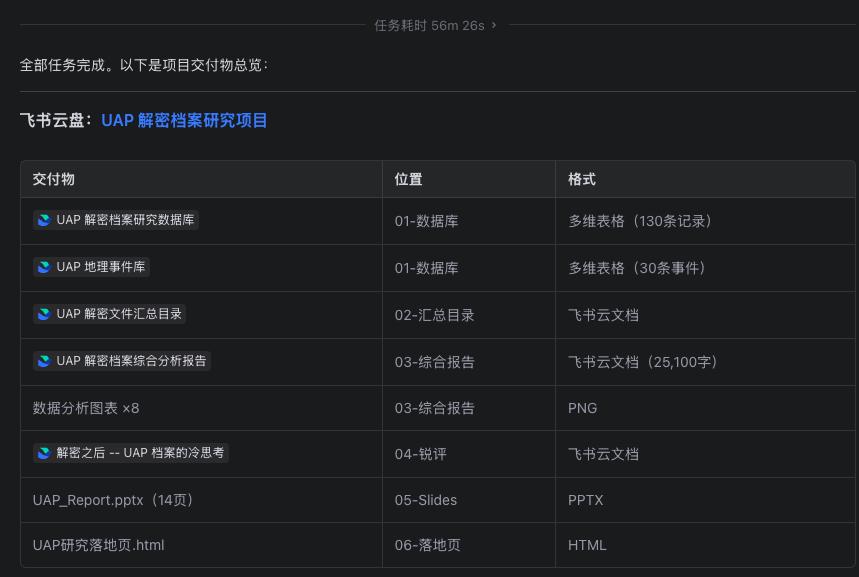
首先我们让它整理了这上百份文件,根据内容进行提取,解析,建立元数据索引。为了方便查阅,直接接入了 IM 软件,让它把成品交付到工作空间。
提示词
美国战争部披露了 UAP 相关的解密资料,非常多。
资料压缩包在本地,解压,逐份分析,进行深度解析;
在飞书云盘中新建相应文件夹,飞书有对应的文档,表格,多维表格,中间的交付物,以合适的格式放到飞书云盘中,追求可视化;
分类并按合适的专业框架进行梳理,生成汇总目录,生成专业的学术风格的报告,严谨,再生成锐评版总结,可以发散一点。
生成 slides,对调查结果进行展示,要求符合主题,去除 AI 味,选择合适的设计 skill。
生成落地页,要求符合主题,展示此次研究的概览和成果;内嵌地球仪,用于展示事件发生的地点,可互动。生成完检查一下,看功能是否正常。

它拉出来的数据表格相当规整,而且针对我特别提到的坐标问题,额外整理了一份地理事件库,其中区域,经纬坐标,传感器乃至重要性都标注得很清晰。

接下来,针对整理出的数据,让它出具两份报告,一份正经的,一份锐评一些的。在正经版的报告中,它调用 Python 脚本提前生成了图表,避免了纯文本表格的视觉单调性,而且相比文生图也更加精准,不容易出数据纰漏。
值得注意的是,两份报告的长度都非常给力,都在万字以上,而且不是空洞的堆砌,每个章节都能对原文件进行回溯。怕我看不明白,最后还按学术风格整理了一份术语对照表,就格式和流程来看,已经非常严谨了。

任务继续,针对后面要交付的汇总文档和 PPT,落地页等展示内容,它判断到这些都共用刚才整理的数据源,且互不干扰,所以就新建了 4 个子 Agent 并行执行,效率拉满。
当然,快归快,能不能用还得看交付物的质量。就 PPT 的审美来看,跟主题结合的色调和风格都基本到位,而且还复用了报告中生成的图表,这在长线任务中是非常重要的一环。

而最惊喜的是落地页的展示效果,在充分调用不同的 Skill 组合后,整个页面的设计更有人味儿,排版组织合理,表格能筛选,时间轴有对应,互动的二级菜单也有准确的内容呼出。
我们继续上难度,直接从 GitHub 拉一个现成的开源项目给它,让它辅助我们理解仓库,方便后续开发。在拉到本地后,千问就弹出了提示,问要不要调用插件,构建整个项目的 wiki 系统。
在确认后,它就开始忙活了,整个耗时几十分钟,远超我的预期,但结果也同样超预期,尤其是它对整个仓库的梳理,细致入微。
其中不但有框架性的架构,而且针对核心模块,配置管理,部署安装都有对应的操作说明,特别是每个章节中涉及源代码的地方都有引用,不明白的地方点击后就能跳转到对应文件的函数片段,算是做到了有据可循。
接着我发现,项目本身只有 Windows 的安装包,Mac 和 Linux 都需要自己源码部署,也就是命令行启动。于是我直接让千问根据 wiki,分析出可行的打包方案,给我构建一个 Mac 上的启动入口。很快,确定好方案后,它就交付了入口,点击后就能直接启动,足以见得,wiki 的合理构建对于后续的开发能节省大量算力。
提示词:
我不想在终端中唤起项目,再打开 webui,给我换个简易的方案,现在的环境是 Mac,Apple 的 CPU。
除此之外,咱们之前说过,Qwen3.7-Max 对市面上的 Agent 框架都有良好的泛化能力,所谓好模型不挑框架,我们也试着把它接入了第三方的 Agent 框架中,发现任务表现依然很出色。
案例我们选择了美国战争部最近解密的 UAP( 不明异常现象,UFO 的官方称呼 )文件。
整套文件 1.22GB 大小,共有 118 份文档,28 段视频以及 14 张图片,而且其中部分 PDF 文档还是扫描件,文字排版和图片混合,很不清晰,但为了充分压榨 Qwen3.7-Max 的性能,我们还是强制要求了逐份整理分析。
千问意识到这是一项非常复杂的任务,它先调用提前安装好的技能组,先行设计了一套可落地的研究方案,内容涵盖从解压到最终验证的 7 个阶段,在手动删改部分细节后,它就开始执行了。
首先我们让它整理了这上百份文件,根据内容进行提取,解析,建立元数据索引。为了方便查阅,直接接入了 IM 软件,让它把成品交付到工作空间。
提示词
美国战争部披露了 UAP 相关的解密资料,非常多。
资料压缩包在本地,解压,逐份分析,进行深度解析;
在飞书云盘中新建相应文件夹,飞书有对应的文档,表格,多维表格,中间的交付物,以合适的格式放到飞书云盘中,追求可视化;
分类并按合适的专业框架进行梳理,生成汇总目录,生成专业的学术风格的报告,严谨,再生成锐评版总结,可以发散一点。
生成 slides,对调查结果进行展示,要求符合主题,去除 AI 味,选择合适的设计 skill。
生成落地页,要求符合主题,展示此次研究的概览和成果;内嵌地球仪,用于展示事件发生的地点,可互动。生成完检查一下,看功能是否正常。
它拉出来的数据表格相当规整,而且针对我特别提到的坐标问题,额外整理了一份地理事件库,其中区域,经纬坐标,传感器乃至重要性都标注得很清晰。
接下来,针对整理出的数据,让它出具两份报告,一份正经的,一份锐评一些的。在正经版的报告中,它调用 Python 脚本提前生成了图表,避免了纯文本表格的视觉单调性,而且相比文生图也更加精准,不容易出数据纰漏。
值得注意的是,两份报告的长度都非常给力,都在万字以上,而且不是空洞的堆砌,每个章节都能对原文件进行回溯。怕我看不明白,最后还按学术风格整理了一份术语对照表,就格式和流程来看,已经非常严谨了。
任务继续,针对后面要交付的汇总文档和 PPT,落地页等展示内容,它判断到这些都共用刚才整理的数据源,且互不干扰,所以就新建了 4 个子 Agent 并行执行,效率拉满。
当然,快归快,能不能用还得看交付物的质量。就 PPT 的审美来看,跟主题结合的色调和风格都基本到位,而且还复用了报告中生成的图表,这在长线任务中是非常重要的一环。
而最惊喜的是落地页的展示效果,在充分调用不同的 Skill 组合后,整个页面的设计更有人味儿,排版组织合理,表格能筛选,时间轴有对应,互动的二级菜单也有准确的内容呼出。
不得不提的是,这一套流程走完,消耗了将近一个小时,算是很长的任务了,但千问并没有出现卡壳或者上下文爆炸的情况,交付物的效果都有十分不错的亮点。从这也能看出,作为 Agent 框架的底座,它还是非常合格的。
总的来说,Qwen3.7-Max 最值得关注的,不只是一次模型分数的提升,让它来到了国产榜首,而是它开始呈现出更强的任务执行感,踏实做事的实在感。

从千问 3.5 开始,阿里就朝着智能体的方向一路狂奔。几个月前,新成立的 ATH,也是在集合芯片,模型,以及应用等多面力量,去深耕模型能力的多模态,继而打通智能体的全链路。
特别是在月更的夸张效率下,模型优化的迭代更快了,这意味着你今天用的时候吐槽的 BUG,下个月发新版可能就被填平了。
最为关键的是,受限于模型的能力,我们总是需要搭建各种复杂的限制性工程,去让 AI 做事,让它指哪打哪。
但其中的绝大多数工程可能都只是过渡手段,因为随着迭代闭环的重复,模型会不断内化这些工程,将其吸收为自身能力的一部分。
就像未来的图像编辑可能不再需要精通 PS 一样,那个不再需要复杂框架,LLM 一力降百会的时代,也会在模型迭代中越来越近。