自2025年国务院发布《关于深入实施“人工智能+”行动的意见》以来,AI与制造业的深度融合已不再是远景规划,而是塑造全球竞争格局的核心力量。2026年初,工信部等八部门联合发布的《“人工智能+制造”专项行动实施意见》更是为工业智能体的规模化推广设定了明确的时间表与路线图。在这一宏大背景下,工业AI Agent作为承载“新质生产力”的关键技术载体,其底层技术架构的设计与实现,正成为决定企业能否在这场智能化竞速中脱颖而出的胜负手。
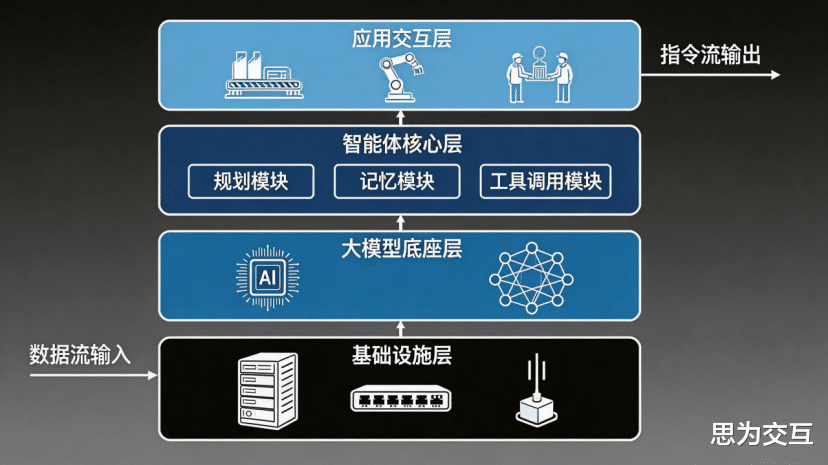
工业AI Agent的核心是其认知能力,而这种能力的源泉便是作为其“中央大脑”的大语言模型(LLM)。LLM赋予了Agent理解复杂指令、进行逻辑推理和生成专业内容的基础。
1. 模型选型:性能、成本与合规的权衡
工业场景对大模型底座的选择远比通用领域复杂。当前,主流模型体系,如GPT系列、BERT、Transformer架构,以及性能优异的开源模型LLaMA系列(如LLaMA3),均已成为备选方案 。同时,国产大模型如通义千问、DeepSeek等也在工业领域展现出强大的竞争力 。
企业在选型时,必须进行多维度权衡:
性能与专业性:通用大模型虽能力广泛,但在特定工业领域(如精密制造、化工流程优化)的知识深度和术语理解上可能存在不足。因此,基于行业数据进行微调(Fine-tuning)或选择经过预训练的行业模型是必然趋势。
成本与效率:模型的推理速度与资源消耗直接关系到工业生产的实时性与经济性。轻量化、高效率的边缘模型将是满足产线实时控制需求的关键。
合规与安全:工业数据是企业的核心资产,涉及生产工艺、供应链等高度敏感信息。因此,模型的部署方式至关重要。
2. 部署模式:公有云API、私有化与混合云
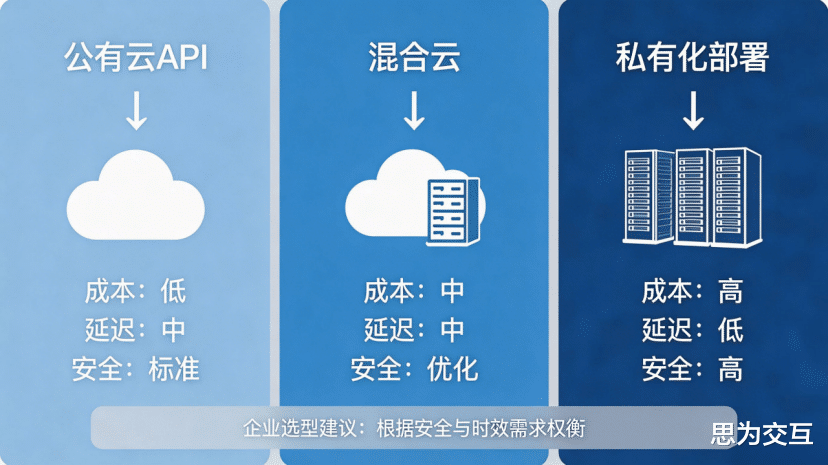
针对数据安全与实时性的考量,部署模式的选择尤为关键。
API调用:对于非核心、低延迟要求的任务,调用公有云大模型API(如OpenAI系列、文心一言等)是一种快速、低成本的启动方式 。
私有化部署:当数据不出域成为硬性要求时,将大模型私有化部署在本地服务器或企业内部云成为唯一选择。这最大程度保障了数据安全与自主可控,但对企业的算力基础设施和运维能力提出了更高要求。
混合云部署:这是一种兼顾灵活性与安全性的折中方案。将部分非敏感任务或模型训练放在公有云,而核心推理与数据处理则在本地完成 。这种模式正成为越来越多制造企业的首选。
二、 精密工具链:从“感知”到“执行”的桥梁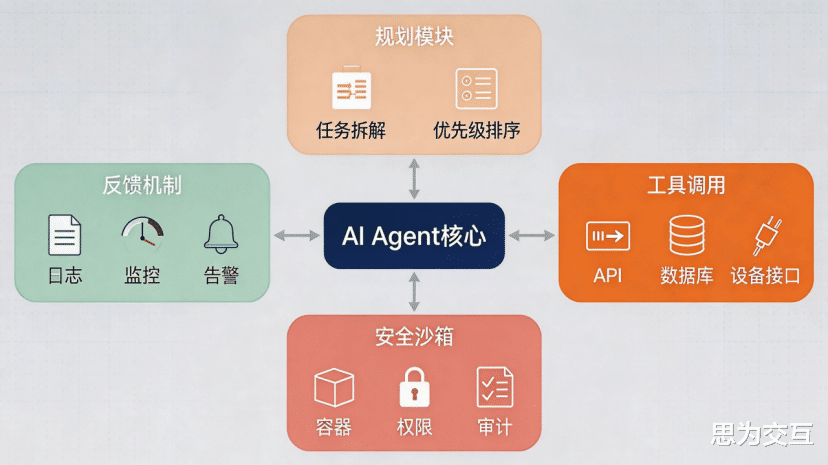
如果说大模型是Agent的大脑,那么工具链就是其延伸至物理世界与数字世界的“双手双脚”。一个强大的Agent不仅要“会思考”,更要“能执行”。其工具链设计通常包含以下关键组件:
1. 规划(Planning)模块
规划模块是Agent的“任务指挥官”。它负责将来自人类或上层系统的复杂、模糊指令,拆解成一系列清晰、可执行的子任务 。在工业场景中,这意味着将“优化A产线的生产效率”这样宏观的目标,分解为“调用MES系统API获取实时产能数据”、“分析瓶颈工序”、“调整机器人臂运动参数”等具体步骤。
2. 工具调用与API编排(Tool Use & API Orchestration)
这是Agent与工业环境交互的核心。通过调用外部工具或API,Agent的能力边界得以无限扩展 。这些工具可以包括:
企业内部系统API:如MES(制造执行系统)、ERP(企业资源计划)、SCM(供应链管理)等,实现数据的读取与指令的下达。
物联网(IoT)设备接口:直接与传感器、执行器、PLC(可编程逻辑控制器)交互,感知物理世界状态并进行控制。
专业软件与数据库:如调用CAD/CAM软件进行设计验证,或查询材料性能数据库。
高效的API编排能力,要求建立统一的接口管理体系,确保集成过程的安全性、策略可控性与全链路可观测性 ,这是实现复杂流程自动化的基础。
3. 安全沙箱(Security Sandbox)
赋予Agent自主行动的能力,必然伴随着潜在风险。工业生产对稳定性和安全性的要求是零容忍的。因此,安全沙箱成为保障Agent可靠运行的“安全带” 。通过容器化技术(如Docker)或更轻量的虚拟化技术(如Firecracker)构建一个隔离的执行环境 Agent的所有高风险操作(如代码执行、系统调用)都在这个受控环境中进行。沙箱机制通过严格的权限控制、资源限制和行为审计,确保Agent即使出现决策失误,也不会对核心生产系统造成灾难性影响 。
三、 记忆机制:赋予Agent“经验”与“成长”的能力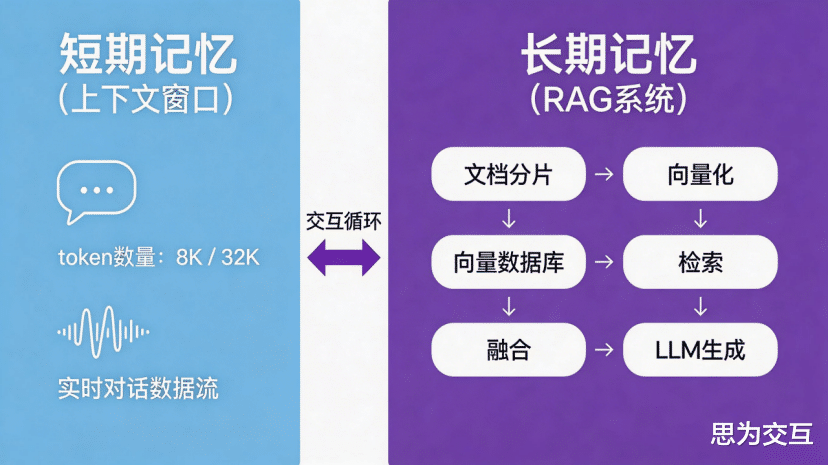
一个没有记忆的Agent只能处理孤立的任务,无法从历史经验中学习和进化。构建一套高效的记忆系统,是实现工业AI Agent从“自动化工具”向“自主智能体”跃迁的关键。
1. 短期记忆(Short-Term Memory)
短期记忆负责存储当前任务的上下文信息,如对话历史、中间计算结果等 。它通常依赖LLM自身的上下文窗口(Context Window)来实现。在工业对话或连续控制任务中,短期记忆确保了Agent行为的连贯性。
2. 长期记忆(Long-Term Memory)
长期记忆是Agent积累知识和经验的“数据库”。它存储着跨任务、跨周期的持久化信息,如设备维护手册、历史故障记录、最优工艺参数、操作员偏好等 。其核心实现技术是检索增强生成(RAG)。通过将非结构化和结构化的工业知识存入向量数据库,当Agent遇到新问题时,首先在长期记忆库中检索最相关的信息,然后将这些信息作为上下文“喂”给LLM,从而生成更精准、更符合事实的回答和决策 。
3. 记忆的融合与高级应用
短期记忆与长期记忆的动态融合,构成了Agent完整的认知循环。更进一步,强大的记忆机制还能支持更高级的智能应用:
时序数据处理:通过记忆历史传感器数据流,Agent能够识别设备状态的演变趋势,为预测性维护提供依据。
因果推理:结合记忆中的事件关联信息(如“某项参数调整”与“后续产品次品率上升”的关联),Agent能够进行初步的因果推断,辅助工程师进行根本原因分析(RCA),避免做出短视的决策。
四、 挑战与前瞻:迈向高可靠、可信赖的工业智能体尽管工业AI Agent的技术架构已日益清晰,但从实验室走向大规模产线部署,仍面临严峻挑战。根据行业观察,当前应用率虽快速攀升 ,但实现多环节、全公司规模化的企业仍是少数 。
核心瓶颈在于:
实时性与可靠性:工业控制对毫秒级的延迟和“五个九”(99.999%)的可靠性要求,与当前大模型非确定性、高延迟的特性之间存在天然矛盾 。
可解释性与信任:深度学习模型的“黑箱”特性,使其决策过程难以解释,这在安全攸关的工业场景中是重大障碍 。引入可解释AI(XAI)技术,让Agent的每一个决策都有迹可循,是建立人机信任的前提 。
工程化落地:将复杂的AI模型无缝集成到现有的OT(操作技术)系统中,并保障其长期稳定运行,是一项艰巨的工程挑战 。
展望未来,国家层面的战略布局正为解决这些挑战提供强大动力。2026年政府工作报告首次将“算电协同”纳入国家战略 ,旨在为AI提供更高效、更绿色的算力支持。工信部与国家数据局联合发起的“模数共振”行动 ,则致力于打通模型与数据之间的壁垒。更令人瞩目的是,“十五五”规划已将“具身智能”列为新质生产力的核心方向 而工业AI Agent正是通往这一终极目标的坚实阶梯。