DC娱乐网
一次强化学习算法重构实践
2025-10-08 22:30:25
奔跑的跳跳
科技
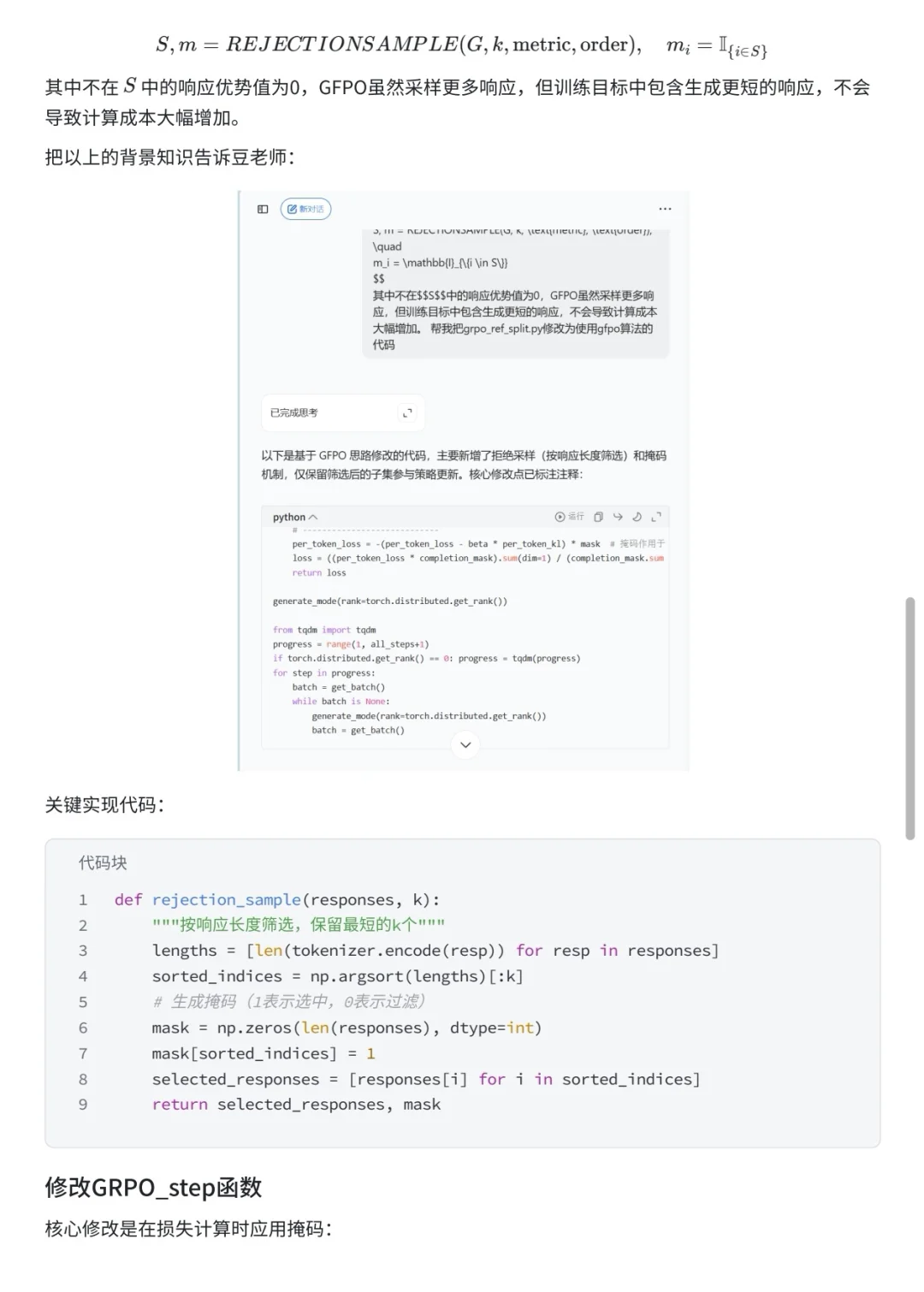
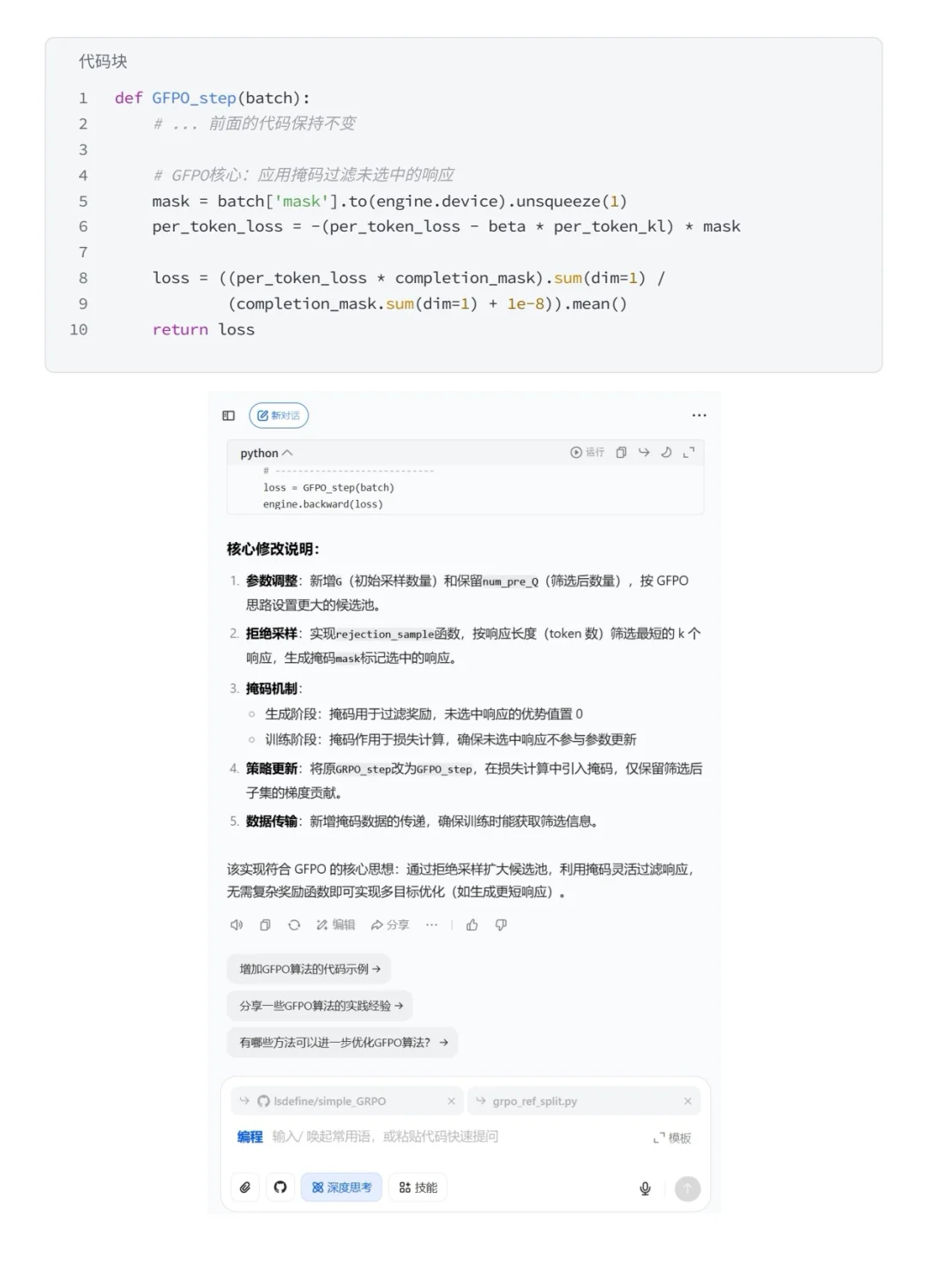
这次实验基于我之前跑过的github上的 GRPO 代码,尝试融入微软提出但还没有开源的 GFPO 思路,在 GSM8K 数学推理任务上做的一次小改造。核心改动主要集中在引入 rejection sampling 和 掩码机制:前者通过筛选候选响应来缩短推理长度,后者确保只有高质量的响应参与梯度更新。
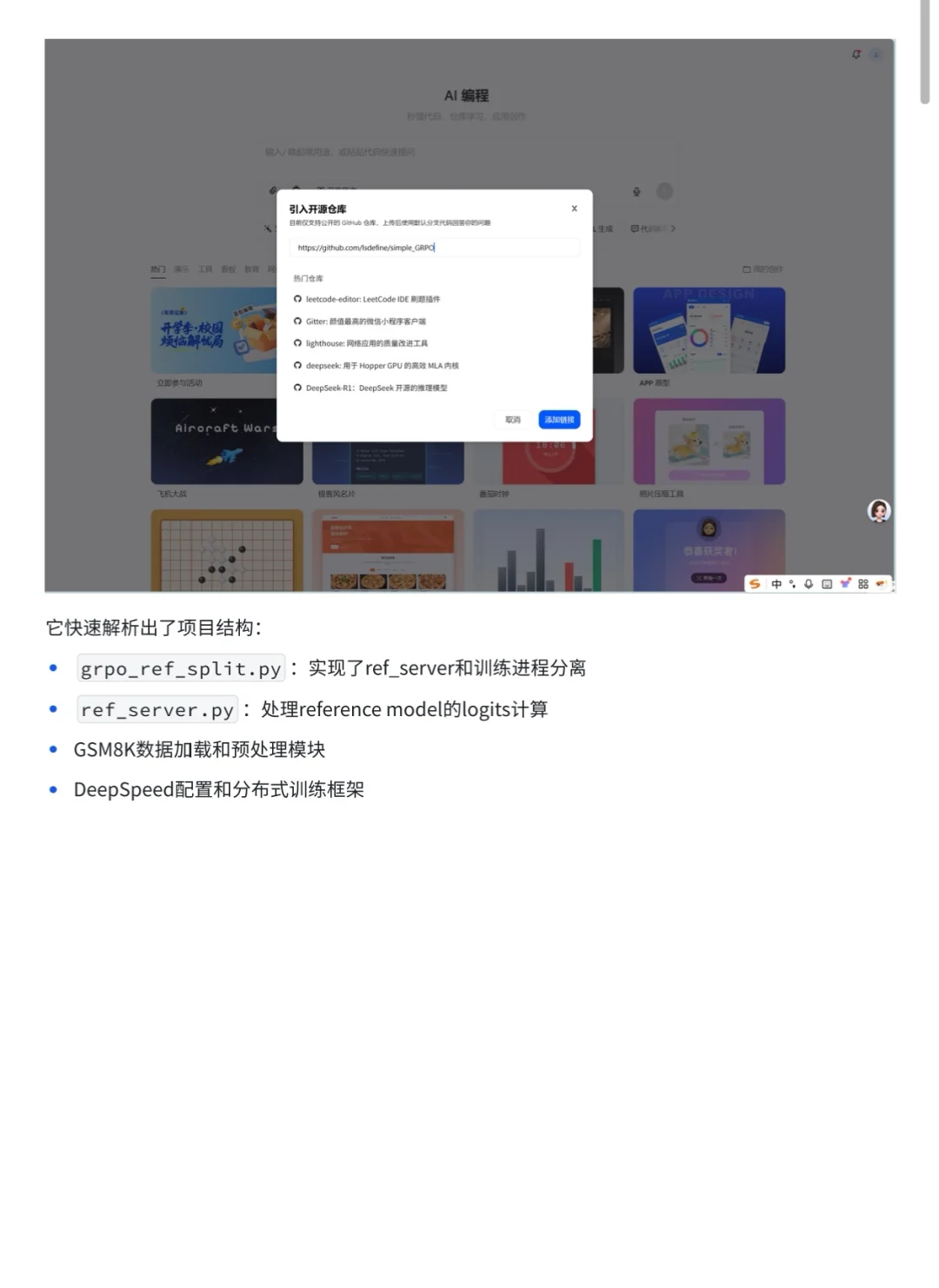
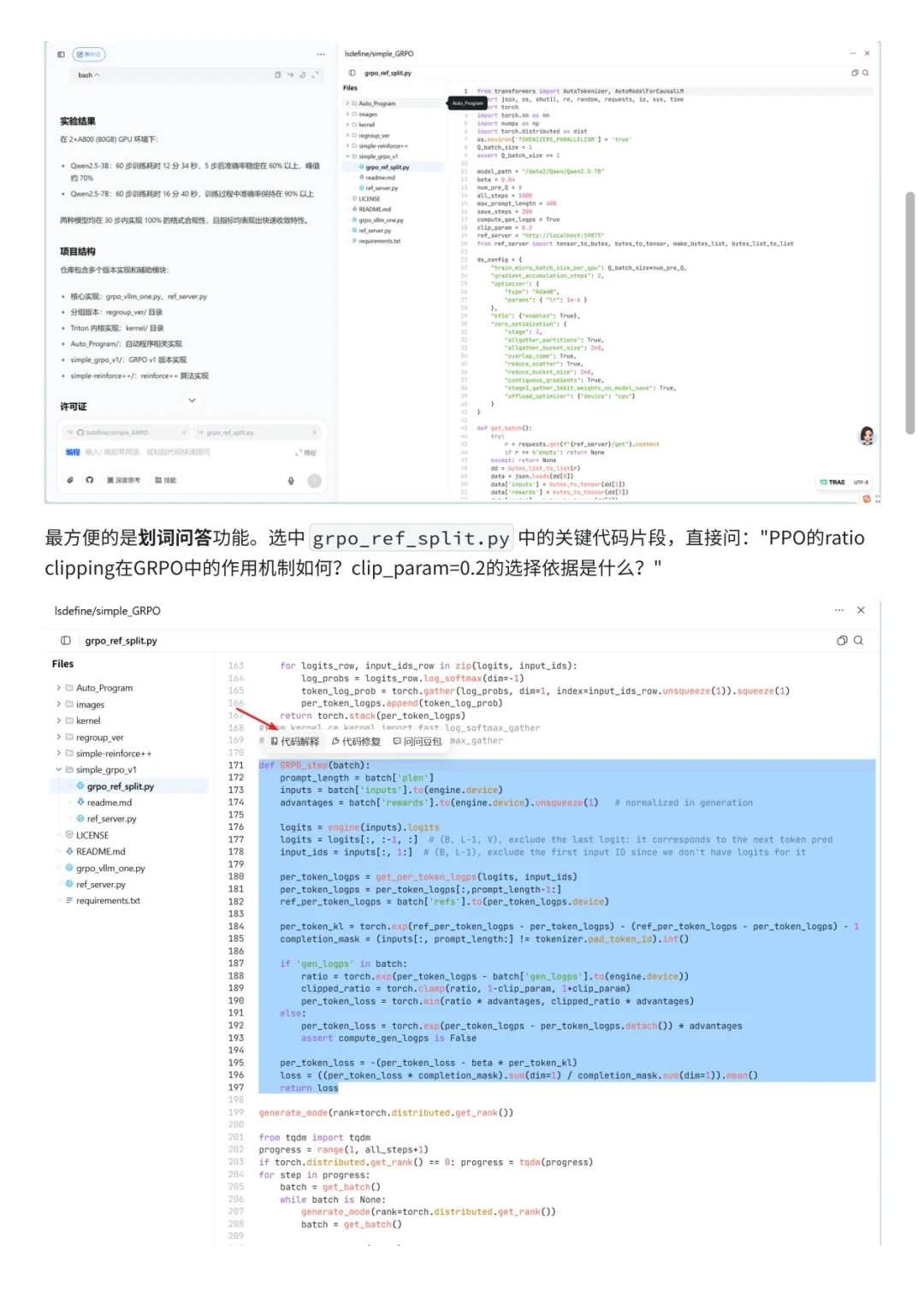
在豆老师编程 PC 端的辅助下,代码重构和调试的效率大幅提升,避免了很多手工排查的麻烦。最终实验结果表明,GFPO 在基本保持准确率的同时,将平均响应长度缩短了约 45%,推理效率显著提高。
对我来说,这次实践最大的收获就是熟悉了 GFPO 背后的设计思路,以及在小规模实验里感受到AI工具辅助开发的便利性。整体而言,这是一次比较简单但有价值的学习型实验。
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量