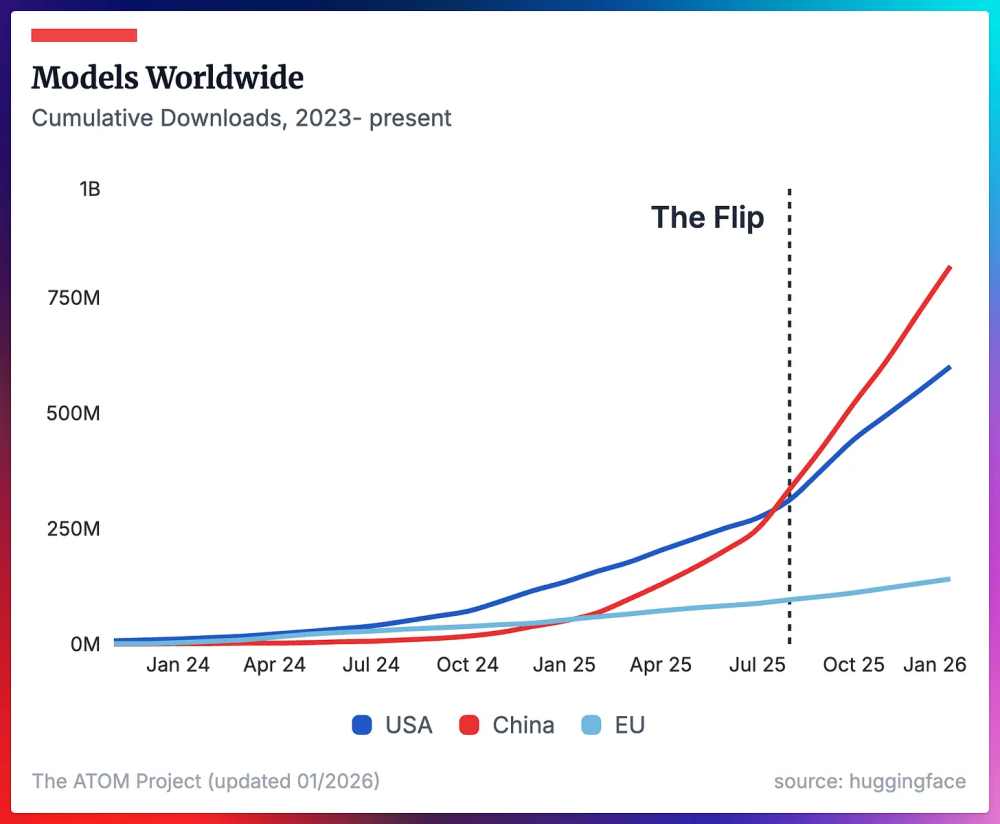
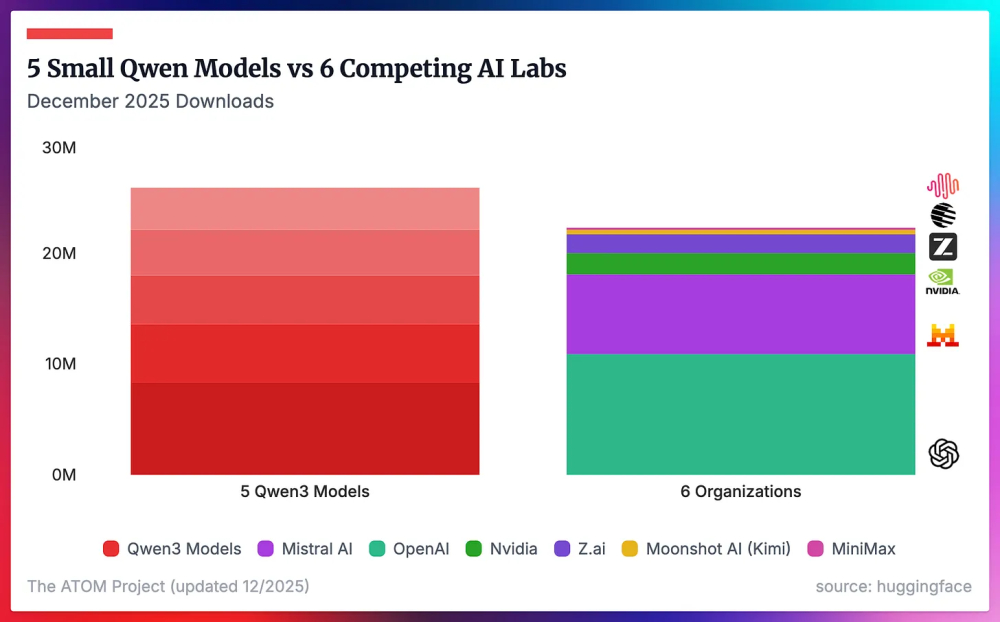
跟大家说个有意思的消息。美国有个AI专家叫内森·兰伯特,他每隔一段时间就会更新一份全球开源模型生态的评估报告。这人在业内挺有名的,数据也做得扎实,基本上可以当作行业风向标来看。他最新发布的一组图表,在硅谷引发了不小的震动。图表里有一条曲线,标注了一个词叫 The Flip,翻译过来就是翻转点。这个点出现在2025年8月前后,代表中国的那条红线,正式向上穿透了代表美国的蓝线。也就是从这个时间点开始,中国开源模型的全球下载量,超过了美国。而且不是小幅超越,是断层式的领先。到2026年初,差距已经拉开到一个相当夸张的程度。我举几个更直观的数字。2025年12月,单月下载量排名里,Qwen一骑绝尘,大概是9000万次。把Meta、DeepSeek、OpenAI、Mistral、Nvidia这些巨头加在一起,总共也就6000万左右。换句话说,Qwen一家的下载量,比其他所有玩家加起来还要多出50%。还有一个更夸张的数据。统计了Qwen3其中的5个模型的下载量,就超过了Mistral、OpenAI、Nvidia、Z.ai、Moonshot AI、MiniMax这6家顶级AI实验室所有模型的总和。5个模型干翻6家公司全部产品线,这个对比实在太直接了。内森·兰伯特在博客里写了一句话,原话是这样的:2025 saw the end of Llama and Qwen triumphantly took its spot as the default models of choice across a variety of tasks。大意是说,2025年见证了Llama时代的终结,Qwen成功接替它的位置,成为各类任务的默认首选模型。这话从一个美国AI专家嘴里说出来,分量是很重的。Llama是Meta搞的开源大模型,之前一直是这个领域的绝对霸主。全球开发者想用开源模型,第一反应就是Llama。但现在,这个默认选项换成了Qwen。这个转变是怎么发生的?第一层是产品本身够硬。内森·兰伯特在分析里提到一个观点,中国开源模型被广泛采用的核心原因,是它们目前就是最聪明的开源模型。在主流基准测试上持续领先,这是最基本的底气。光聪明还不够,还得好用。Qwen3系列覆盖了从0.6B到235B等多个尺寸,从轻量级到大规模都有。小模型可以在本地部署,对硬件要求不高,普通开发者也能跑起来。这就大大降低了使用门槛,让全球开发者可以很方便地上手实验。第二层是生态滚雪球效应。有一张图显示了各基础模型衍生模型数量的占比变化。2023年底,Qwen的份额几乎为零。但到了2025年底,它的衍生模型占比已经超过50%。这意味着一半以上的开发者在基于Qwen做二次开发。当越来越多人用你的模型,就会产生越来越多的教程、案例、工具链。这些东西又会吸引更多人加入。生态一旦转起来,惯性是很大的。内森·兰伯特对此的评价是:This is the advantage that Qwen has built and will take year(s) to unwind。这个优势需要数年时间才能消解。第三层是连对手都开始用你了。这个最有说服力。2024年12月,彭博社报道了一个消息。Meta内部有个新项目叫牛油果,在训练过程中蒸馏了多方开源模型,其中就包括阿里的Qwen。扎克伯格之前多次公开呼吁要支持美国模型,但Llama4表现不佳,中国模型又强势崛起,最后还是得务实。不止Meta,DeepSeek发布R1时配套的6个小尺寸模型,有4个是用Qwen蒸馏的。英伟达、微软、亚马逊、Airbnb这些公司,都在基于Qwen开发业务。斯坦福李飞飞团队、艾伦AI研究所等机构也在用Qwen做前沿研究。斯坦福NLP团队还专门在社交媒体上发帖,表达了对Qwen团队在开源领域贡献的认可。更典型的案例是新加坡,他们的国家人工智能计划原本用的是Meta的模型,后来直接换成了Qwen架构。国家级项目的技术选型,考量是很多的,能做出这种切换,说明差距已经大到无法忽视。最后说点个人感受。技术领域的权力交接,往往不是一夜之间发生的,它是无数个微小选择的累积。每一个开发者决定试用哪个模型、每一家公司决定基于什么底座开发产品,这些选择汇聚起来,就画出了那条曲线。当曲线交叉的那一刻,其实已经没什么悬念了。之前的每一步,都在为这个交叉点做铺垫。内森·兰伯特画出的那张图,记录的就是这样一个历史性的节点。Llama时代结束了,新的格局已经形成。而这一次,世界AI的权力棒已交接到中国手里。