DC娱乐网
男朋友问我GRPO和PPO相比孰优孰劣
2026-02-13 00:11:38
奔跑的跳跳
科技
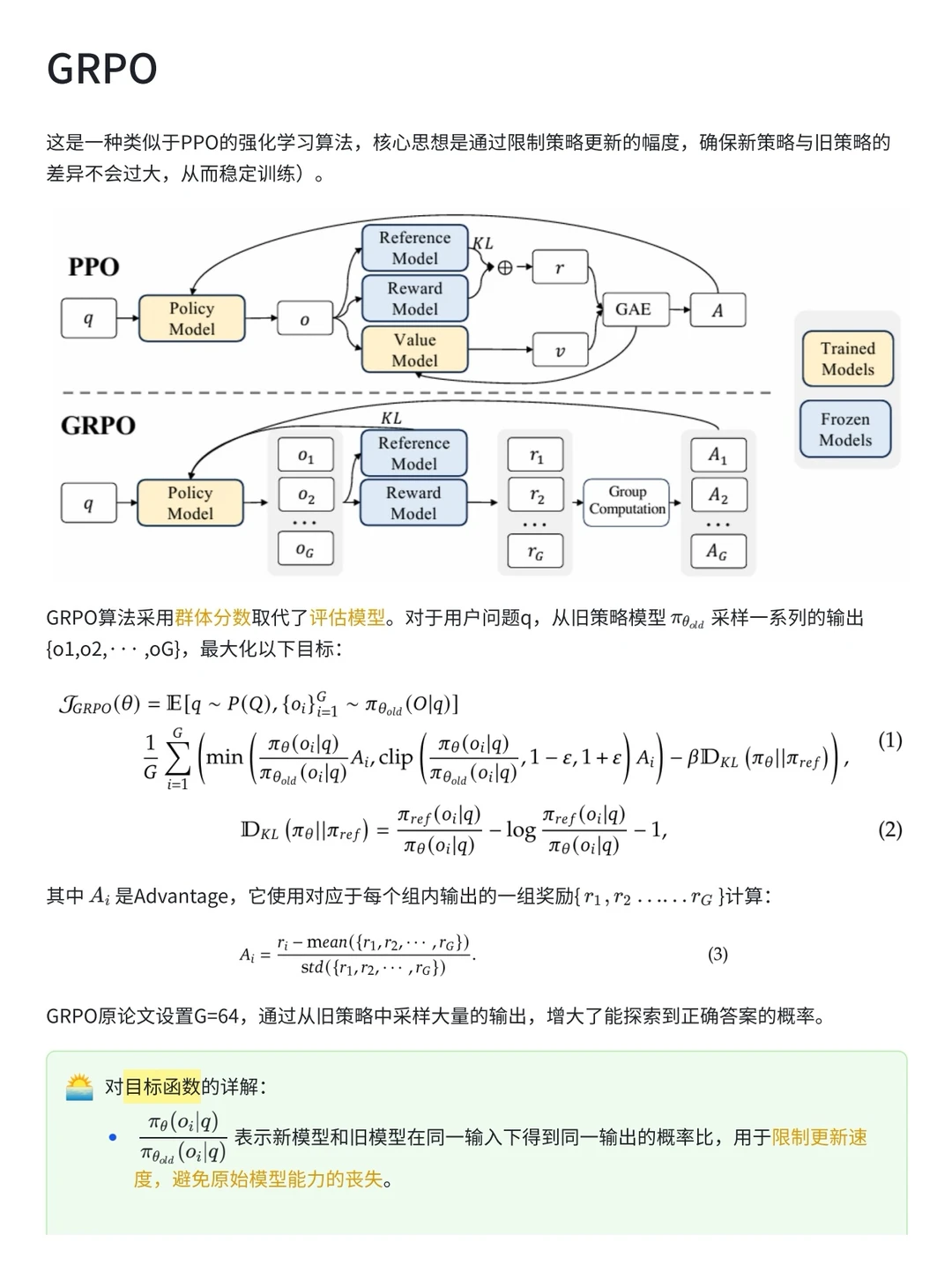
GRPO 最早是在 DeepSeek-Math 里露脸的,也是DeepSeekR1能火起来的重要秘诀。相比PPO这种传统做法,GRPO 直接把评估模型给干掉了,换成了组内相对奖励,不仅省算力,还稳如老狗,训练不容易炸。
它的思路很简单,就是针对每个输入生成一组输出,然后在每个小组里算相对奖励值,主要是看组内谁强谁弱,优化策略的时候就按照这个来,而不是像RLHF那样靠评估模型打分。这样省去了维护评估模型的麻烦,计算负担直接减轻不少,跑起来更快。
除此之外,GRPO 直接在损失函数里加了KL散度正则化,不像PPO那样在奖励里搞一堆 KL罚项,细粒度控制策略更新,调整幅度更丝滑,保证策略不会乱飘,属于是 PPO 的加强版了。
热门分类
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量