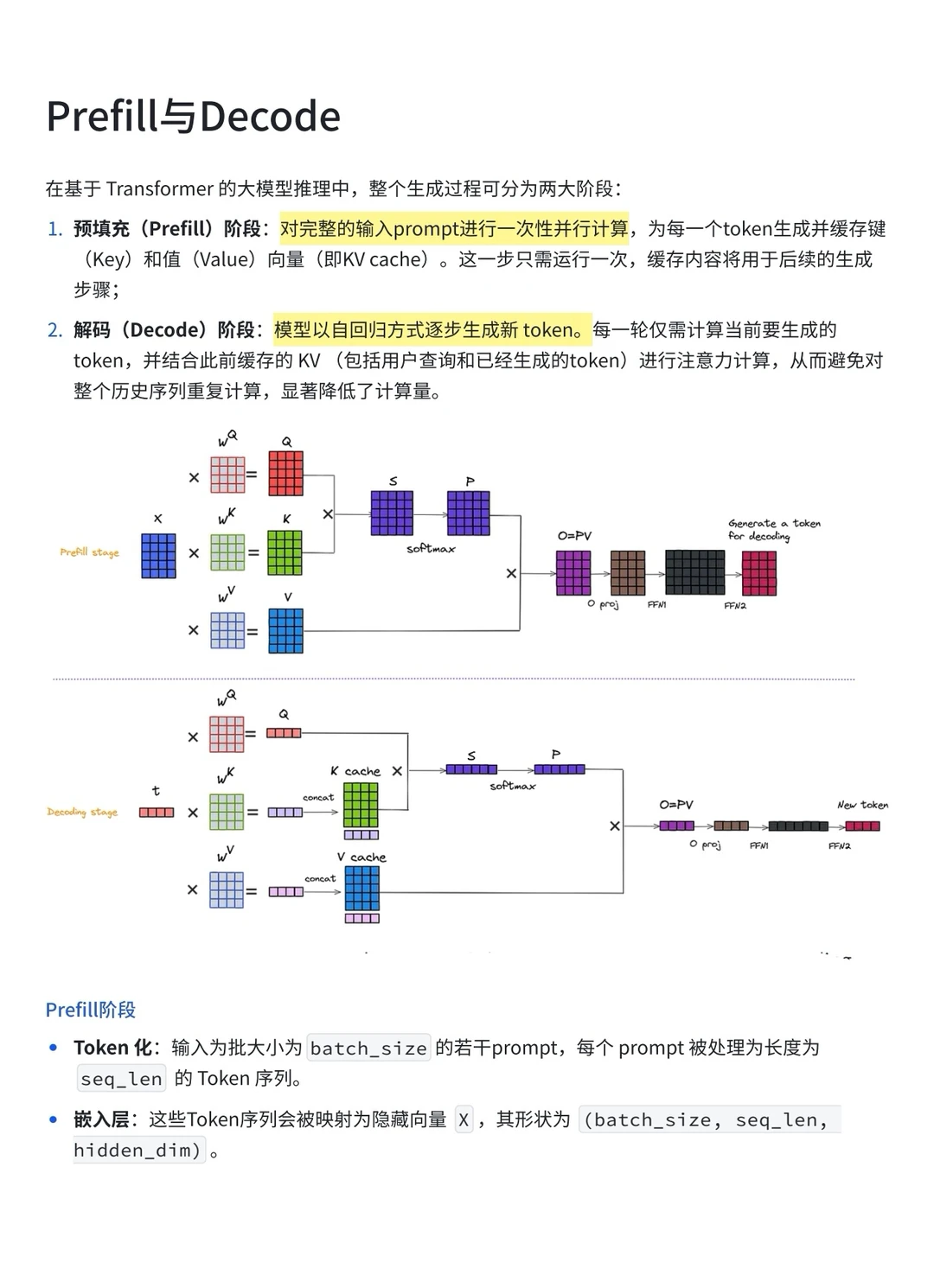
进入 Decode 阶段后,模型以自回归的方式逐步生成 token,使用kv cache能避免重复执行之前token的自注意力运算。
✅为什么要区分这两个阶段?
因为在推理优化中,Prefill 和 Decode 所面临的资源瓶颈完全不同——Prefill 更依赖算力,Decode 则更受带宽限制。因此,业内有不少方法会针对这两个阶段分别做拆分和并行优化,比如 DistServe 会将这两步分配到不同的 GPU 上,或者通过复用 KV cache 来大幅降低显存压力。
理解了这两个阶段,再去看大模型的性能优化方案,就能明白为什么大家都在关注 KV cache 优化和分布式训练。