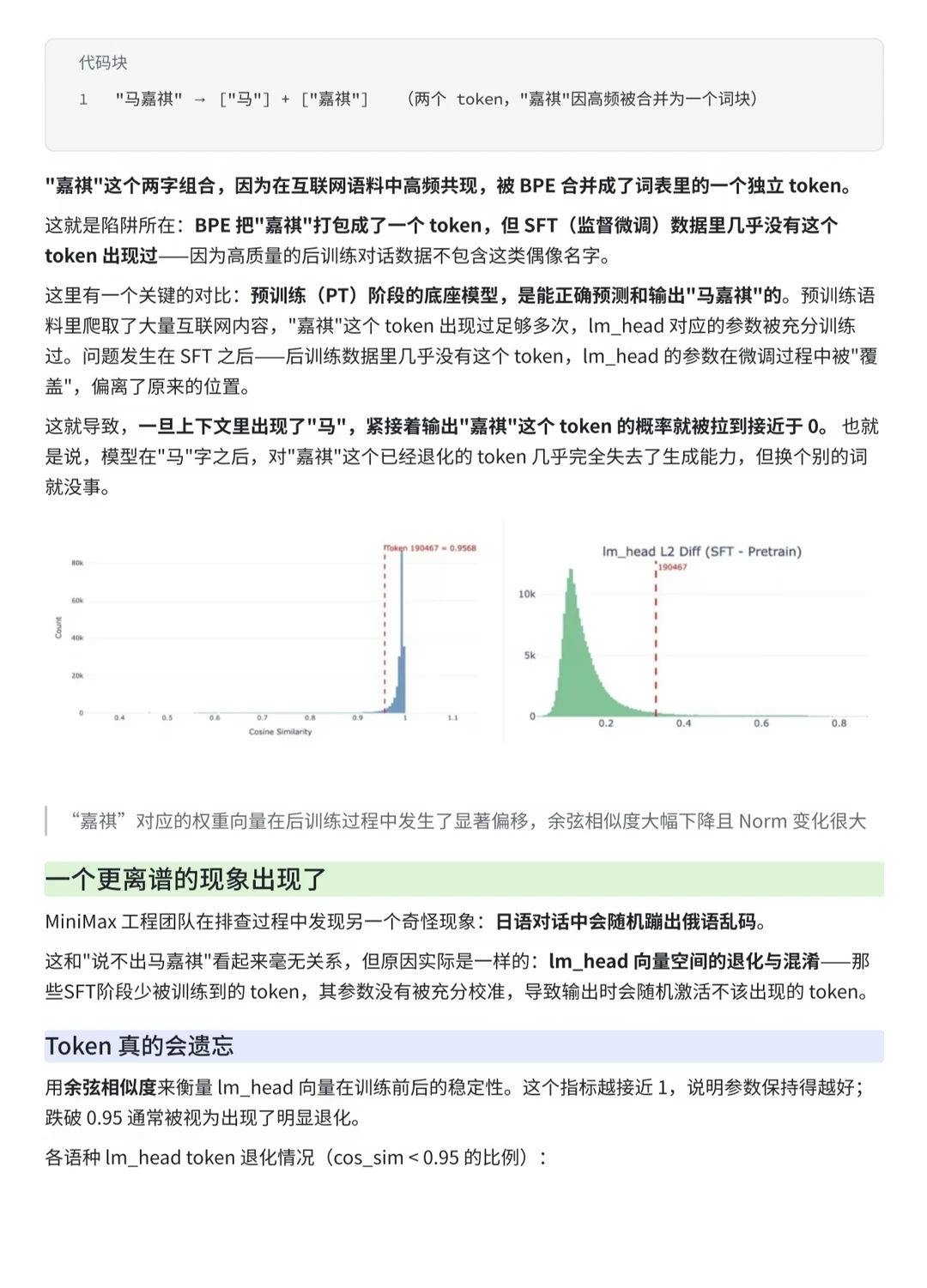
究其原因有两点:
1️⃣BPE会将高频共现字符打包为独立Token,“马嘉祺”被切分为["马"]+["嘉祺"],“嘉祺”成为独立稀疏Token。
2️⃣预训练阶段“嘉祺”训练充分,SFT阶段因高质量对话数据不含该Token,导致lm_head参数被覆盖偏移。
这个问题并非 MiniMax 独有。几乎同期,Anthropic 发布 Claude Opus 4.7 也缩减了词表规模。
这两个动作,被业界解读为同一个根因、两种解法:
1️⃣MiniMax 走加法:保住词表完整性,用定向合成数据修复覆盖盲区,代价是需要额外的数据构造和监控成本。
2️⃣Anthropic(推测)走减法:直接缩减词表,把覆盖不到的 token 砍掉让它消失,代价是用户处理相关内容时需要消耗更多 token,成本转嫁给了用户。
这个比较没有绝对的对错。词表完整度、训练效率、推理成本三者构成一个三角困境。
但两种选择背后的工程哲学差异体现在:一个选择明修栈道,一个选择暗度陈仓(褒义)。