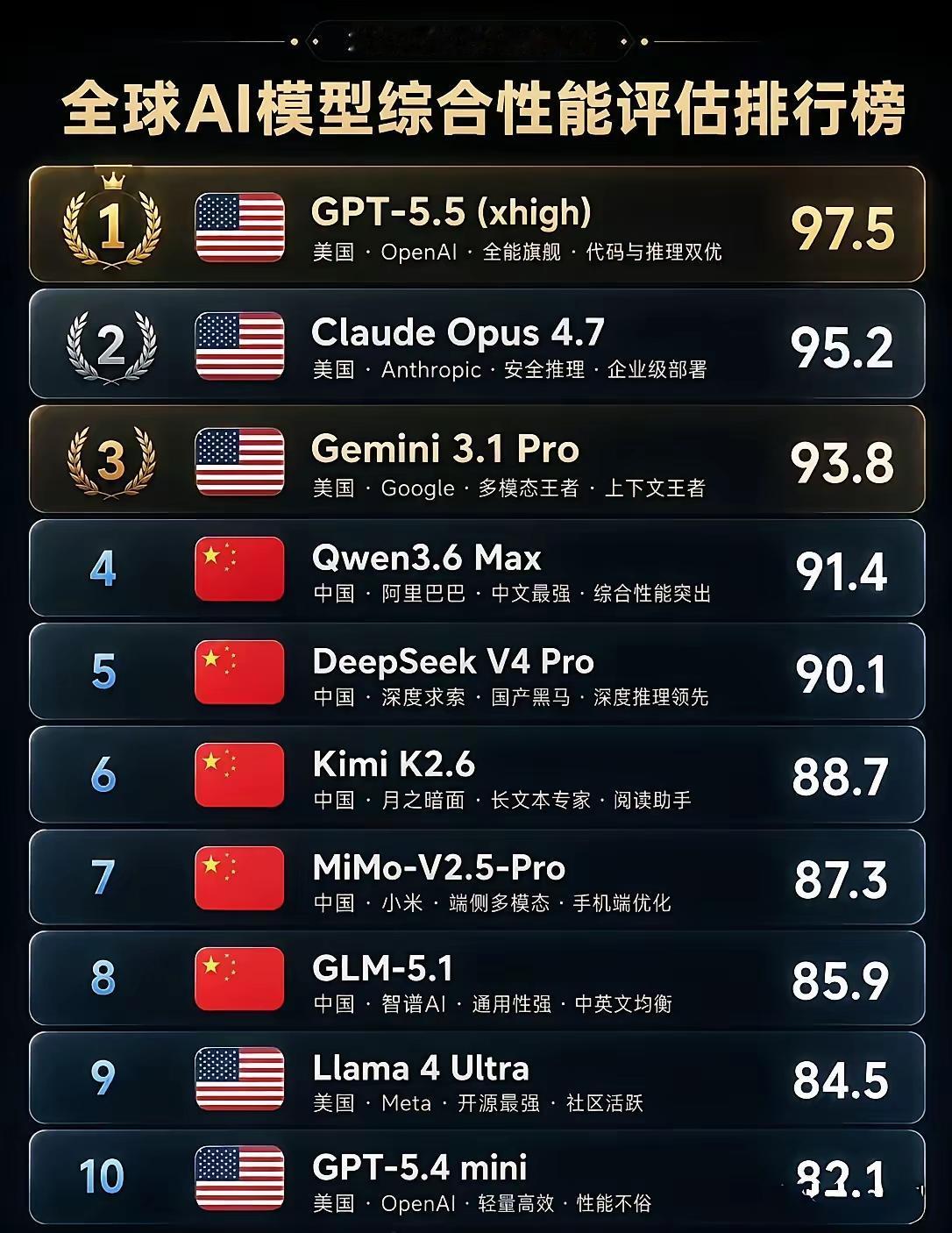
2026年4月全球AI模型综合性能TOP10解读
这份榜单反映了当前全球AI模型的综合实力梯队,国产模型已跻身第一阵营,与国际头部模型的差距持续缩小。
国际头部模型(前3名)
1. GPT-5.5 (xhigh):以97.5分稳居榜首,OpenAI的全能旗舰模型,在代码生成、逻辑推理两大核心能力上表现双优,是当前行业标杆。
2. Claude Opus 4.7:得分95.2,Anthropic的企业级模型,主打安全推理与复杂任务处理,是高风险业务场景的首选。
3. Gemini 3.1 Pro:得分93.8,Google的多模态旗舰,在长上下文处理、跨模态理解上优势明显。
国产主力模型(第4-8名)
4. Qwen 3.6 Max:得分91.4,阿里通义千问的旗舰版本,中文理解与综合性能突出,是国产模型的标杆之一。
5. DeepSeek V4 Pro:得分90.1,深度求索的旗舰模型,深度推理能力领先,在复杂数学、编程任务中表现亮眼。
6. Kimi K2.6:得分88.7,月之暗面的长文本专家,百万级上下文能力,是处理超长文档、代码库的利器。
7. MiMo-V2.5-Pro:得分87.3,小米的端侧多模态模型,针对手机端深度优化,兼顾性能与设备适配。
8. GLM-5.1:得分85.9,智谱AI的通用模型,中英文均衡,通用性强,适合多场景落地。
其他上榜模型
9. Llama 4 Ultra:得分84.5,Meta的开源最强模型,社区活跃度高,适合本地化部署与二次开发。
10. GPT-5.4 mini:得分82.1,OpenAI的轻量高效模型,主打低延迟与高性价比,适合高频调用场景。
一句话总结:国际模型仍占据性能第一梯队,但国产模型已形成稳定的第二阵营,在中文理解、长文本、推理等细分场景实现了突破,整体差距正在快速缩小。
AI十大趋势 AI市场份额 AI优缺点 ai价值榜 AI发展报告 ai大对比 AI测评体系