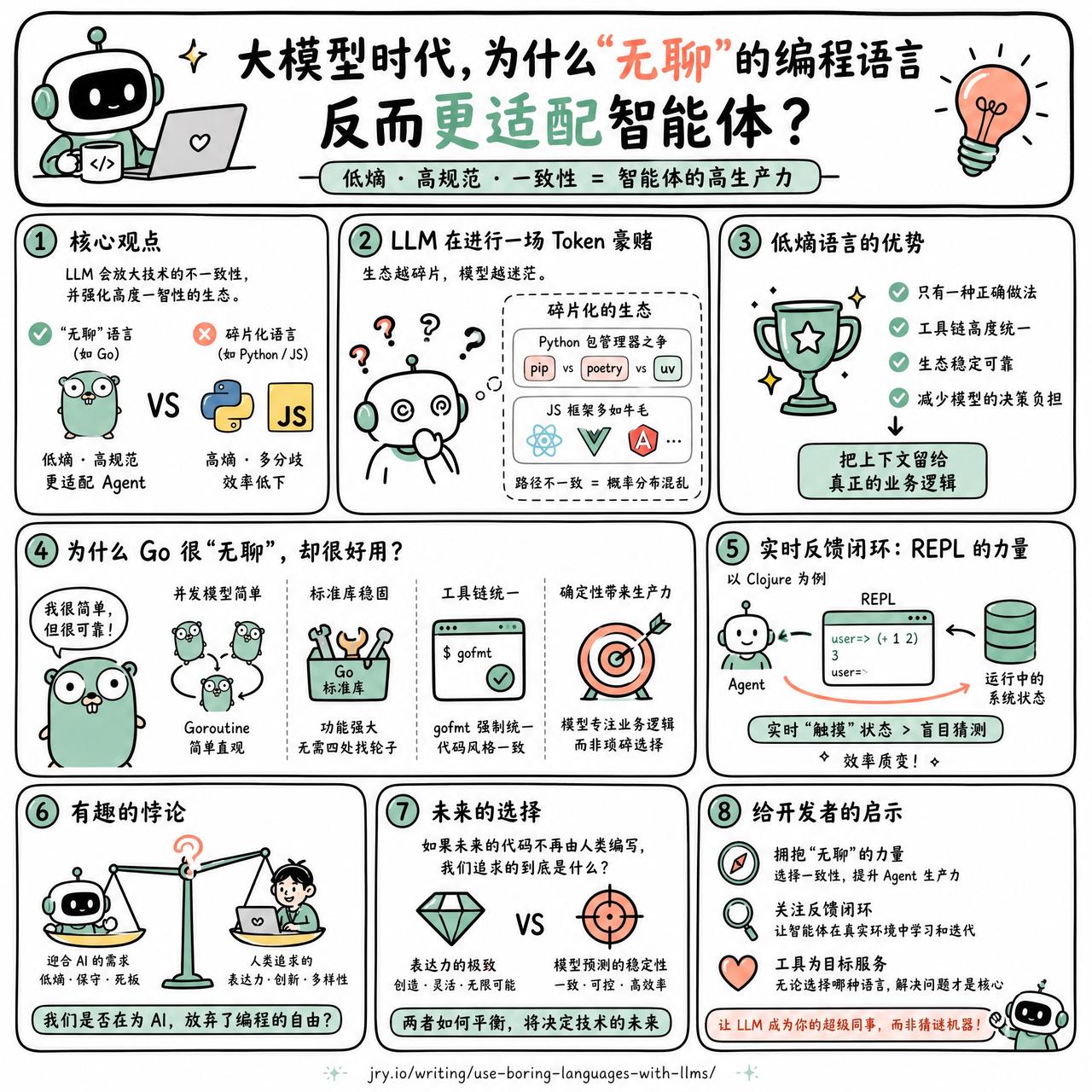
【大模型时代,为什么“无聊”的编程语言反而更适配智能体?】
快速阅读:LLM 会放大技术的不一致性,并强化那些具有高度一致性的生态。对于编程智能体(Agent)而言,低熵、高规范的“无聊”语言(如 Go)比碎片化严重的语言(如 Python 或 JS)更具生产力。
当你在用 LLM 写代码时,其实是在进行一场关于 Token 的豪赌。
如果一个语言的生态极其碎片化,比如 Python 的包管理器有 pip、poetry、uv 之争,或者 JavaScript 框架多如牛毛,模型就会在这些不一致的路径间反复横跳。对于人类来说,这叫“选择困难”;对于模型来说,这叫“概率分布的混乱”。
LLM 本质上是在预测下一个 Token。如果训练语料库里的代码风格、工具链、甚至并发模型都千奇百怪,模型的注意力就会被分散。有观点认为,低熵的语言——那些“只有一种正确做法”的语言,才是 Agent 的终局。
Go 语言之所以在这一波浪潮中显得意外地好用,大概是因为它足够“无聊”。它的并发模型是简单的 Goroutine,没有复杂的异步/同步函数染色问题;它的标准库极其稳固,不需要模型去猜测该用哪个第三方库;它的工具链(如 gofmt)强制了统一的审美。这种高度的确定性,让模型能够把有限的上下文窗口,精准地花在解决业务逻辑上,而不是在纠结“这个变量该怎么声明”或者“该用哪个环境”这种琐事上。
有网友提到,像 Clojure 这种拥有强大 REPL(读取-求值-打印-循环)机制的语言,能给 Agent 提供极强的实时反馈闭环。当 Agent 能直接在运行中的系统里“触摸”状态,而不是盲目猜测代码运行结果时,效率会发生质变。
不过,这也带来了一个有趣的悖论:我们是否正在为了迎合 AI,而被迫退回到那些更保守、更死板、甚至有点“过时”的编程范式中去?
如果未来的代码不再由人类编写,我们追求的到底是表达力的极致,还是模型预测的稳定性?
jry.io/writing/use-boring-languages-with-llms/