告别单卡内卷!国产算力进入“系统级”对决时代
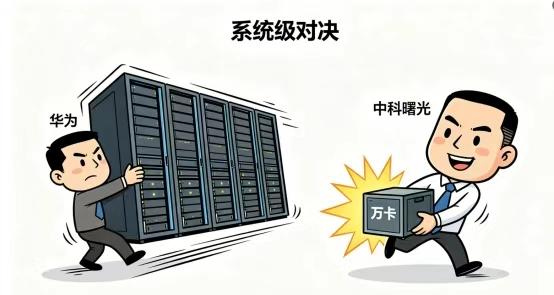
在智博会现场,看着华为384和中科曙光scaleX万卡集群两大巨头对峙,能强烈感受到国产算力的竞争维度变了。以前大家比拼单卡的TFLOPS,现在直接快进到“系统级工程能力”的较量。
这种变化在现场极具视觉冲击力:华为昇腾384需要足足16个机柜来承载384张加速卡;而中科曙光的scaleX万卡超集群单机柜就塞进了640张加速卡。这种肉眼可见的体积差异,背后是算力密度高达20倍的代差。
扒了下,scaleX万卡集群的核心也不是简单堆卡,而是解决“规模效应”下的效率衰减。它通过scaleFabric高速网络将延迟压到微秒级,并在高速互连、存算协同、灵活调度等方面完成体系化跃迁,系统可用性达99.99%。更关键的是其提出的“超智融合”架构,兼容传统超算的双精度能力,把分散的超算与智算中心能力浓缩进高密度机柜里。
面对十万卡甚至更大规模的扩展需求,只有通过这种高密、全精度、低功耗的系统级创新,才能真正撑起数字中国的算力底座。这场“系统局”,中科曙光先下一城。
#产业观察 #万卡集群 #人工智能 #中科曙光 #华为384