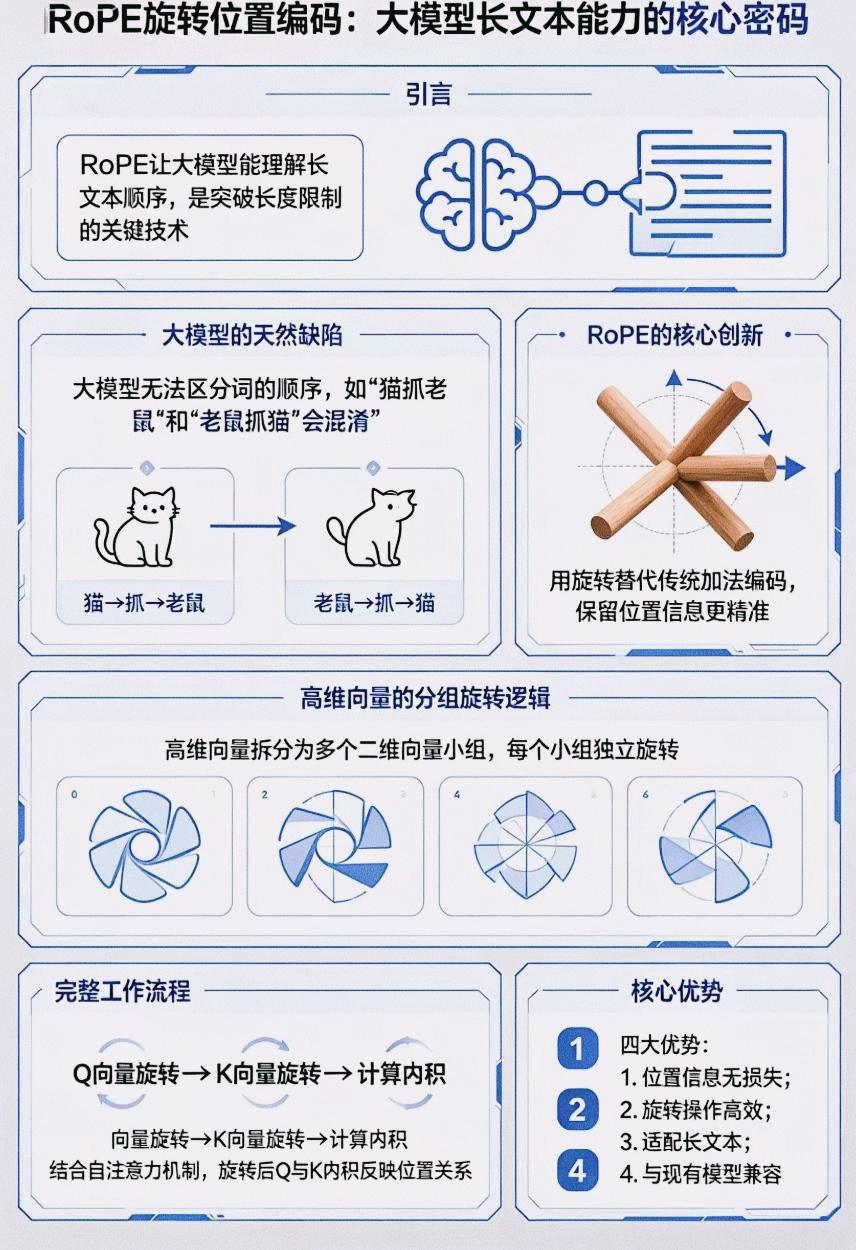
RoPE旋转位置编码通俗解读:大模型长文本能力的“导航系统”
RoPE 是大模型理解“词序”和突破长文本限制的核心技术,用一个通俗比喻就能讲明白它的作用和原理。
一、为什么大模型需要“位置编码”?
大模型处理文本时,只看词的向量本身,无法区分顺序。比如:
- “猫抓老鼠”和“老鼠抓猫”,如果只看词的内容,模型会认为是同一个意思,完全搞混。
- 传统的“加法位置编码”在长文本里会失效,位置信息容易丢失,导致模型“前面的内容记不住,后面的上下文接不上”。
RoPE 就是为了解决这个问题而生的“词序导航系统”。
二、RoPE 的核心创新:用“旋转”代替“加法”
RoPE 放弃了传统的“给位置加一个数字标记”的方式,改用高维向量旋转来编码位置信息:
1. 向量分组:把每个词的高维向量拆成多个二维向量小组;
2. 按位置旋转:每个小组根据词在文本中的位置,独立旋转固定角度;
3. 内积反映顺序:在自注意力计算中,旋转后的 Q(Query)和 K(Key)向量做内积,就能直接反映两个词的位置关系。
简单说:词在文本里的位置越靠后,它的向量旋转角度就越大,模型通过旋转角度的差异,就能精准判断词的先后顺序。
三、RoPE 的四大核心优势
1. 位置信息无损失:旋转操作不会破坏向量本身的语义信息,同时精准保留位置关系;
2. 计算高效:旋转操作是线性运算,速度快,不增加太多模型负担;
3. 天生适配长文本:随着文本长度增加,旋转角度的差异依然清晰,不会像加法编码那样快速失效;
4. 兼容性强:可以直接套用到现有 Transformer 架构上,不用对模型做大规模改造。
四、一句话总结
RoPE 就像给每个词的向量加了一个“方向标”,词在文本里的位置不同,方向标指向的角度就不同。模型通过这些角度差异,既能理解词的顺序,又能在超长文本里稳定工作,这就是大模型能处理长文档的核心密码。
检索增强模型 大_语言模型 视觉大语言模型 无限制词模型 多模态位置编码 维度编码 时空编码技术