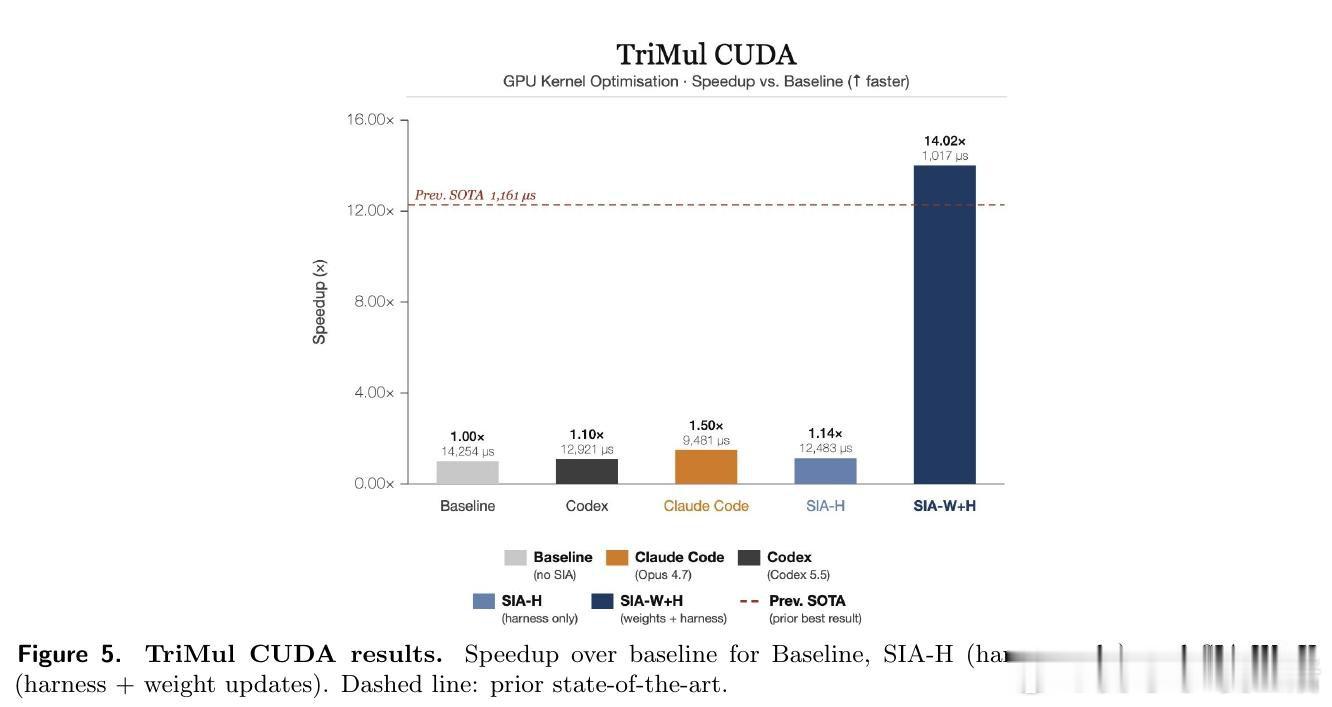
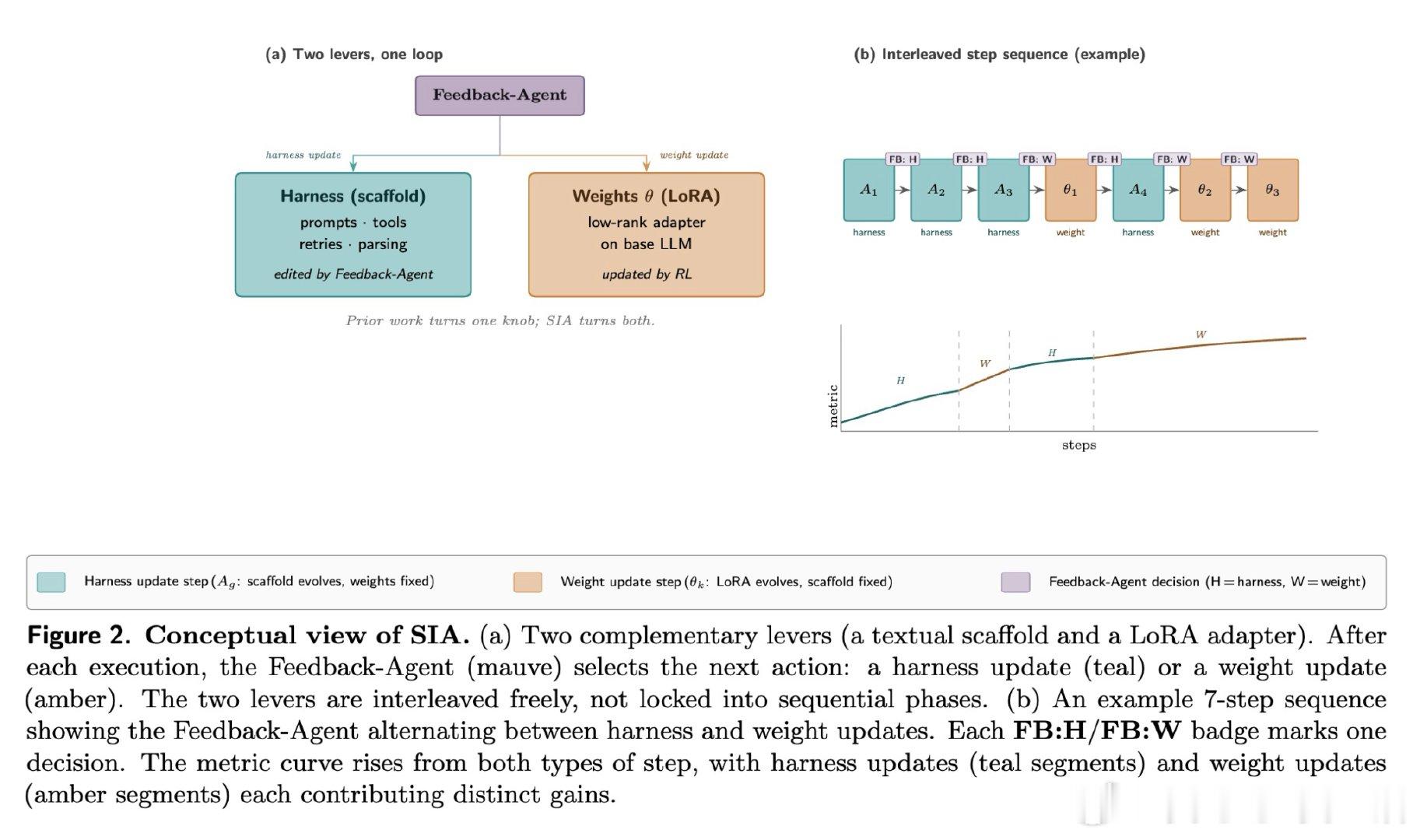
[CL]《SIA: Self Improving AI with Harness & Weight Updates》P Hebbar, Y Manawat, S Verboomen, A Ivanova… [Hexo Labs] (2026)
在自改进 AI 领域,脚手架优化与权重更新是一个割裂难题。过去的方法受困于只改提示工具或只训模型,本质原因是行动方式与领域直觉被分开优化。
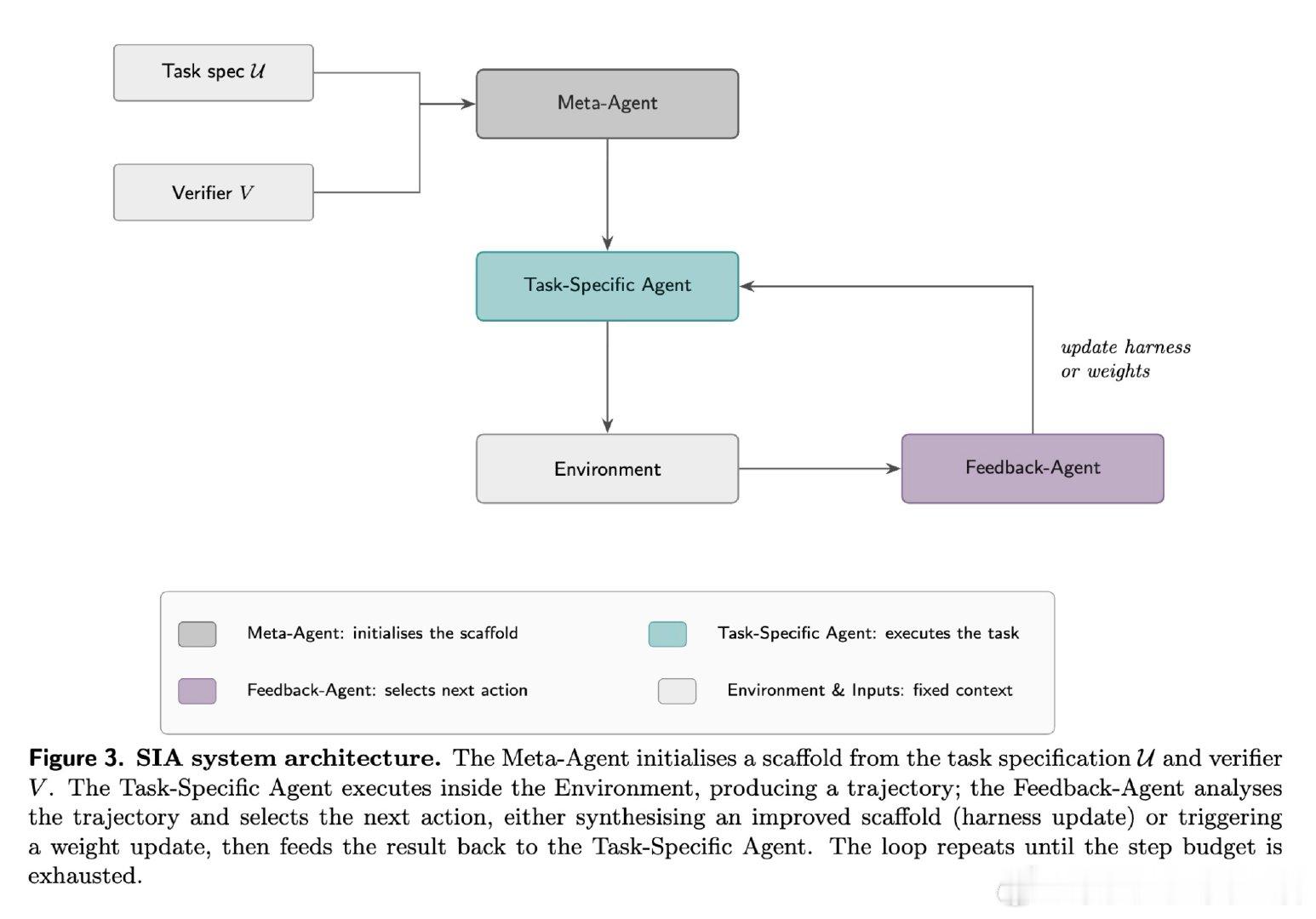
本文的核心洞见是:把智能体重新看作“脚手架+权重”的共同体。由此,反馈智能体依据执行轨迹选择改代码、提示、工具,或用验证器奖励更新 LoRA,使两种改进闭环耦合。
这项工作真正留下的遗产是证明自改进不能只发生在外壳,也要写进参数。它打开的新门是任务给定后自动进化的智能体,但尚未跨过的门槛是同一验证器下的双重 Goodhart。
arxiv.org/abs/2605.27276 机器学习 人工智能 论文 AI创造营