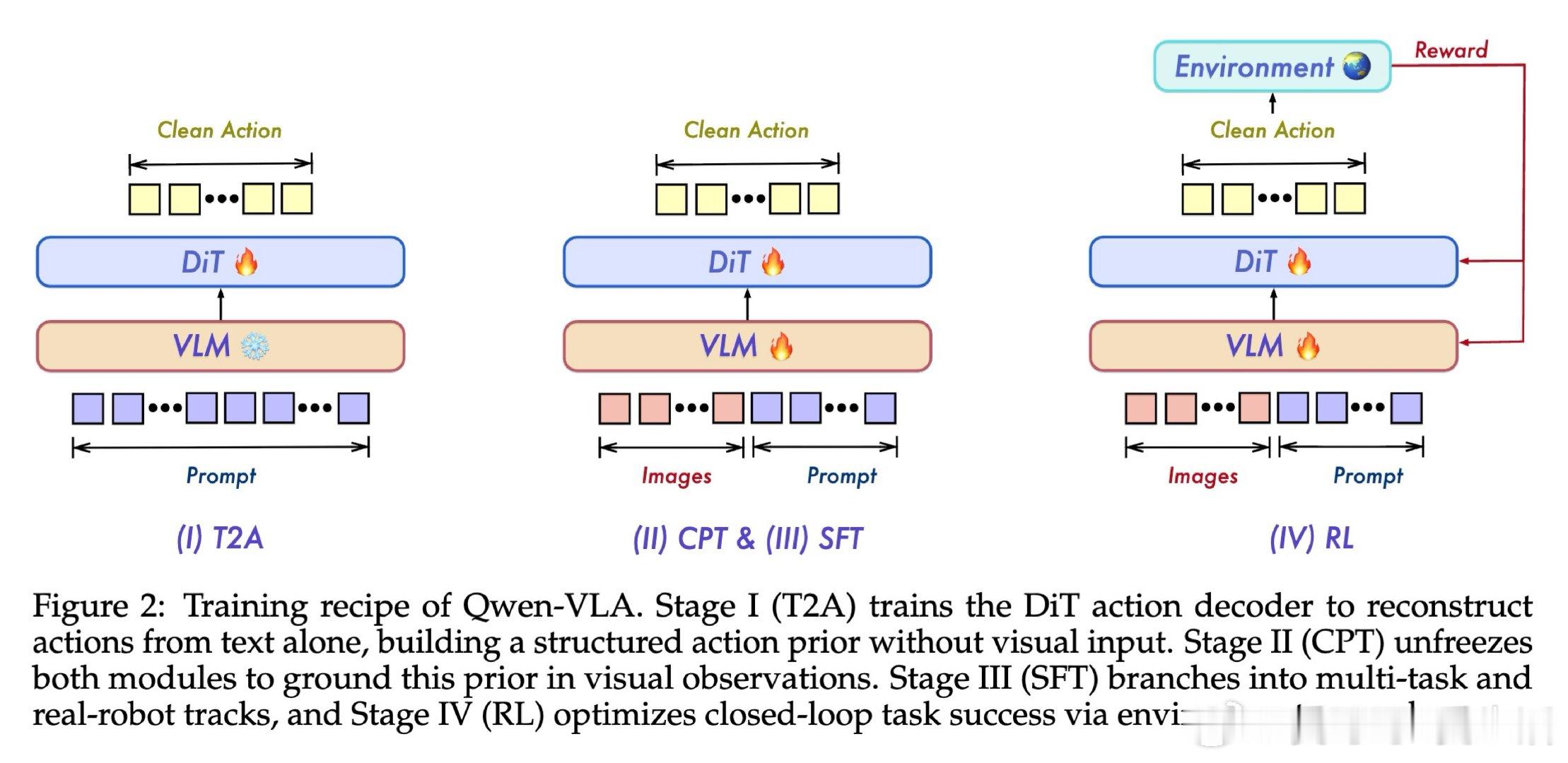
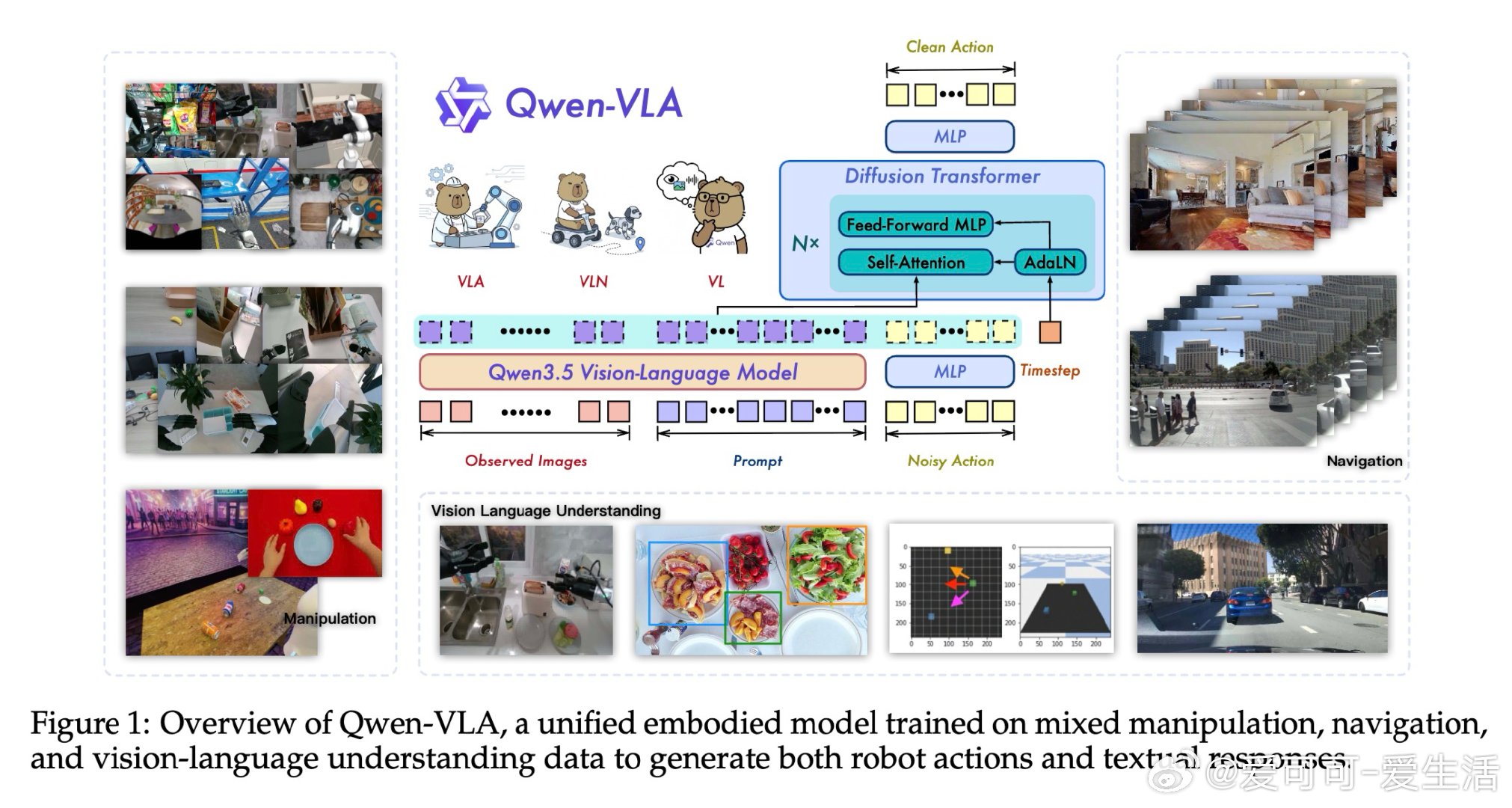
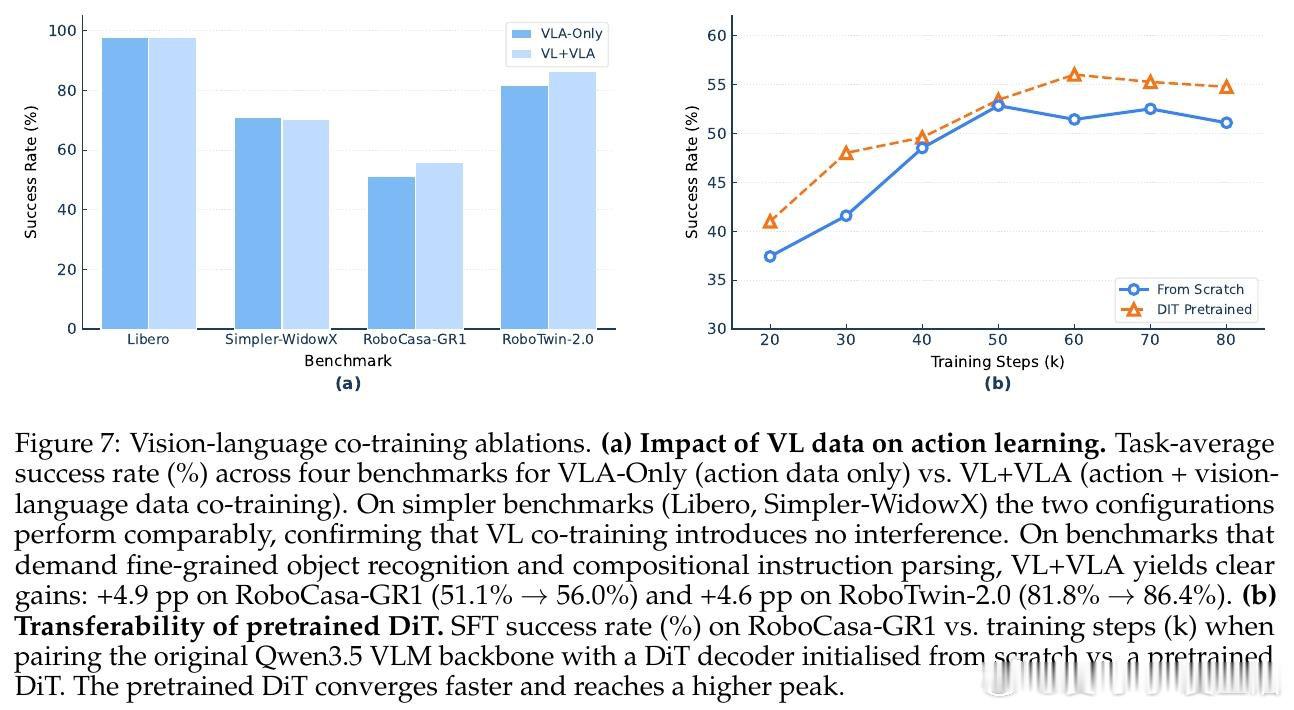
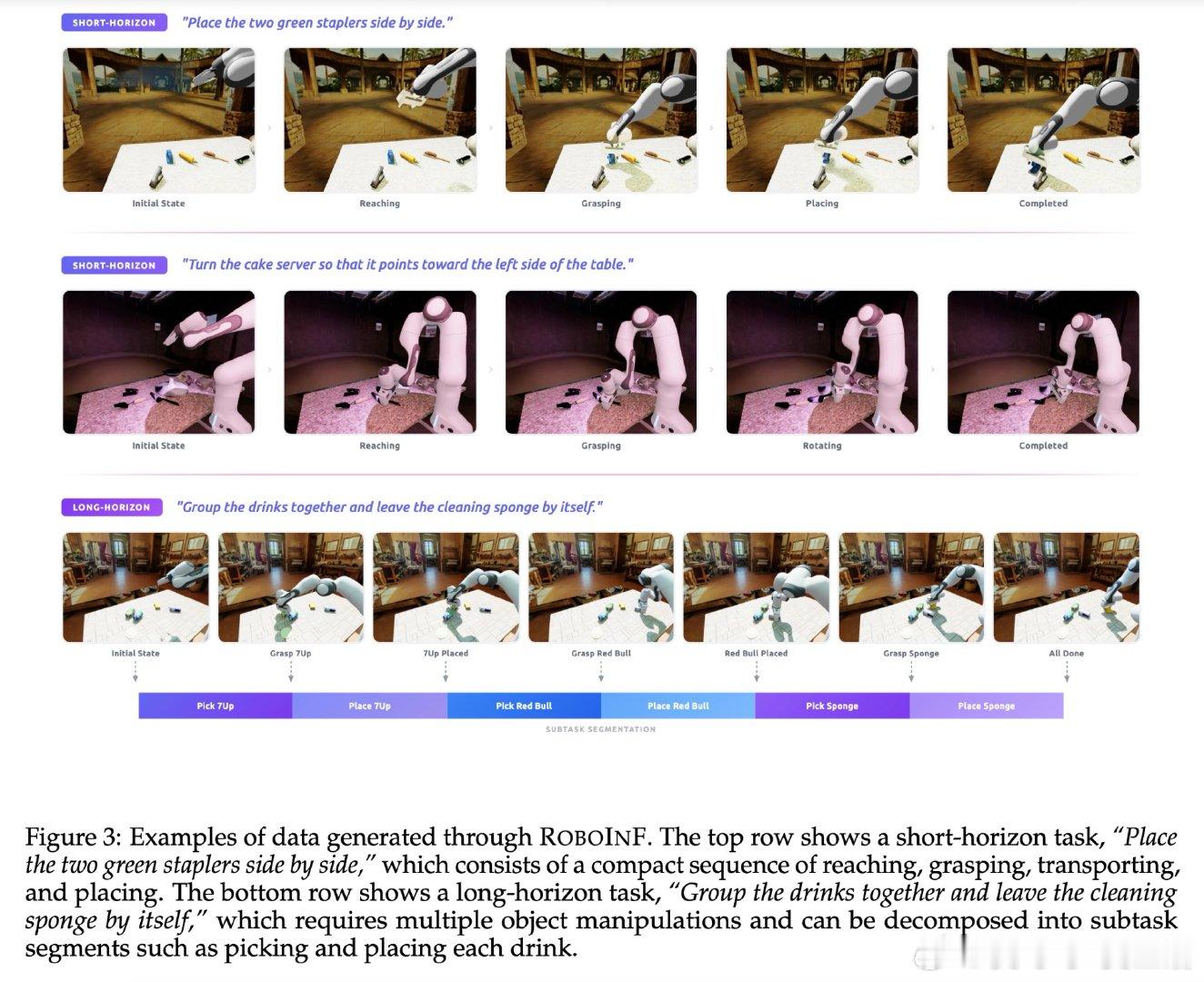
[RO]《Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments》Q Wang, M Li, J Guan, J Ye… [Qwen Team] (2026)
在具身智能领域,通用控制是一个悬而未决的难题。过去的方法受困于单任务、单机器人、单环境,本质原因是动作空间、观测格式与控制约定彼此割裂。
本文的核心洞见是:把操控、导航与人体轨迹重新看作同一种未来动作预测。由此,用具身提示说明机器人身份,再用共享 DiT 动作解码器生成连续动作。
这项工作真正留下的遗产是把 VLM 从“看懂世界”推向“驱动身体”。它打开的新门是跨任务、跨机器人迁移,但尚未跨过的门槛是长程记忆、世界模型与真实闭环可靠性。
arxiv.org/abs/2605.30280 机器学习 人工智能 论文 AI创造营