[LG]《Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay》M Marek, D Cho, S Qiu, R Chunara… [New York University] (2026)
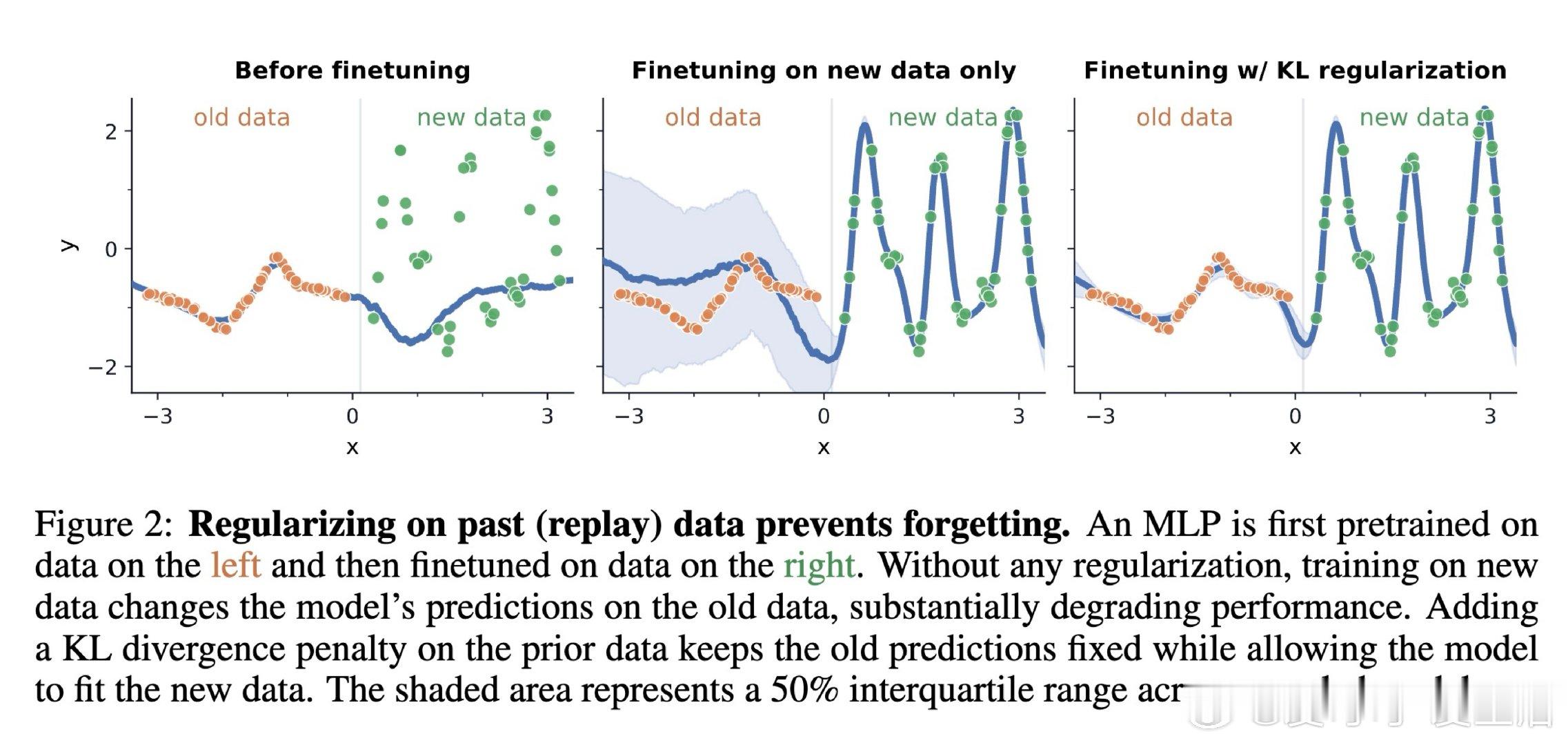
在持续微调领域,遗忘是一个悬而未决的难题。过去的方法受困于保存旧数据,本质原因是模型在新任务上漂移时,缺少约束旧分布输出不变的信号。
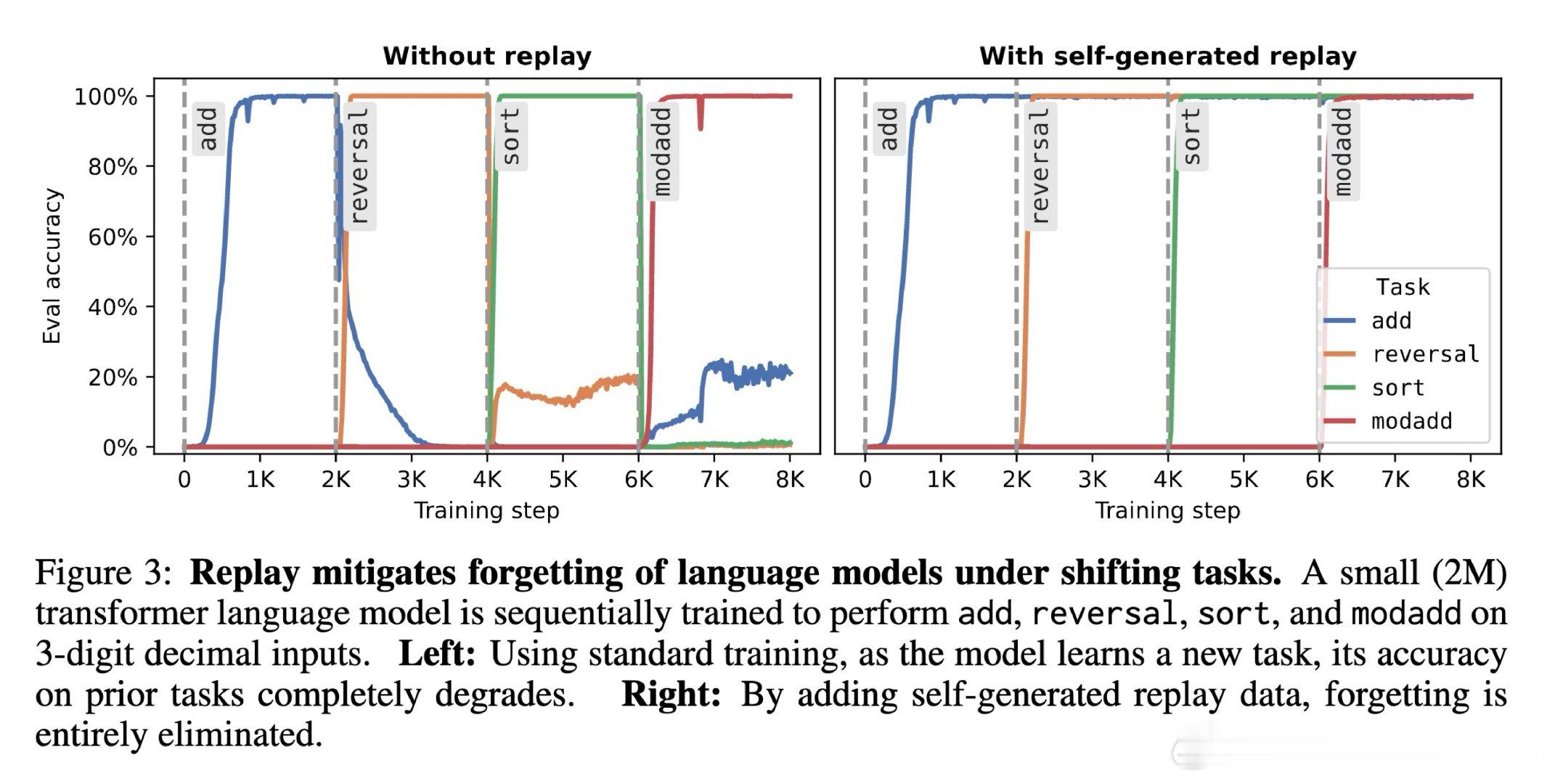
本文的核心洞见是:把语言模型重新看作旧数据的生成器。由此,用模型自采样文本做 replay,并在其上约束 KL,使模型学新任务时仍保持旧预测。
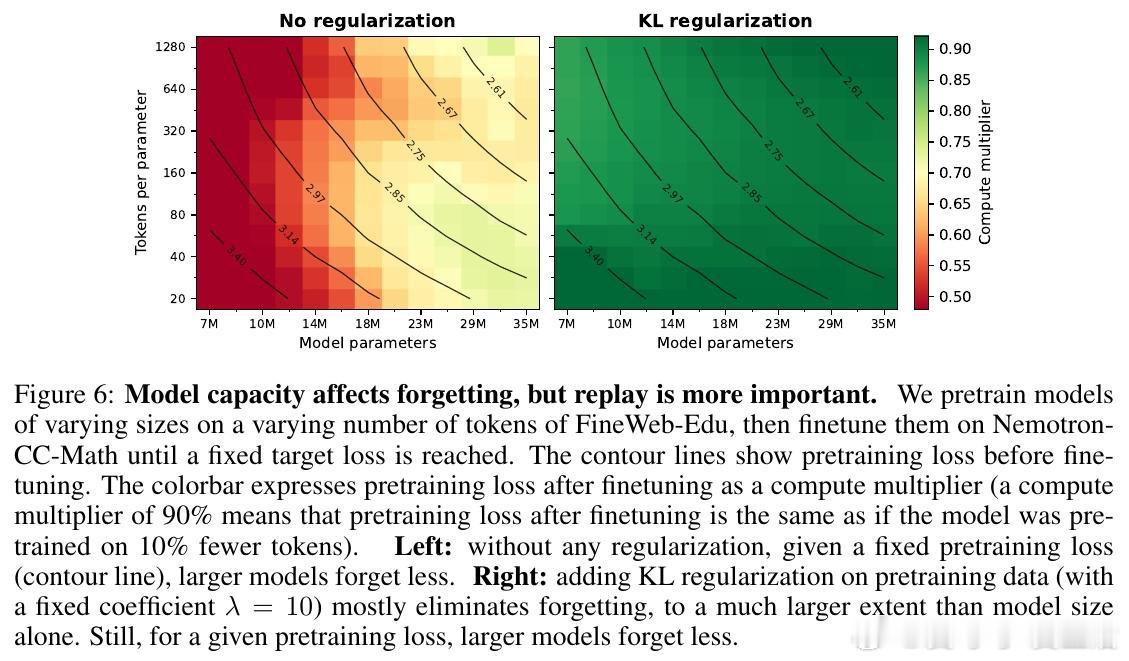
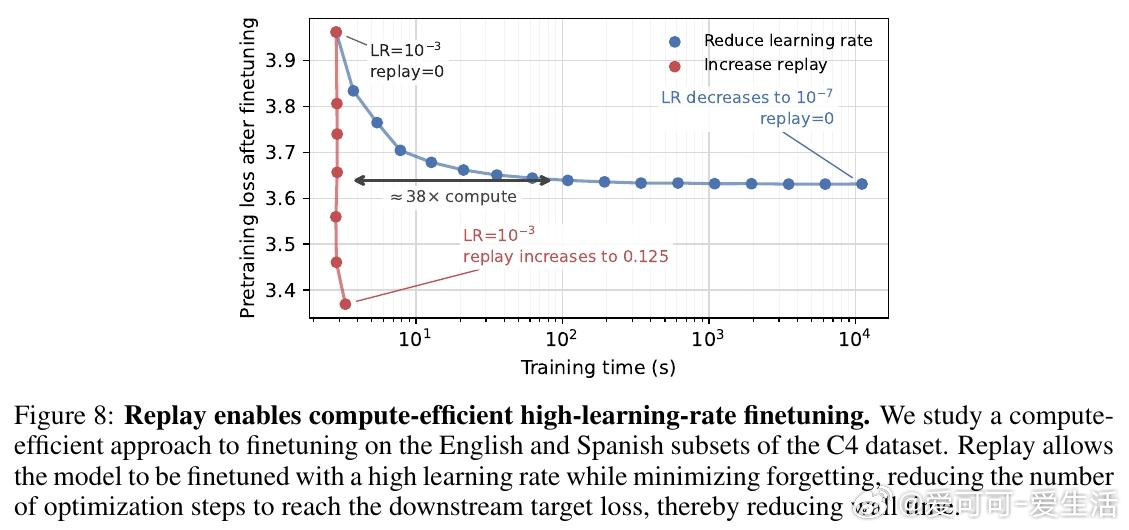
这项工作真正留下的遗产是把遗忘从宿命改写成容量、数据与优化的结果。它打开的新门是无需原始预训练数据的高学习率微调,但尚未跨过的门槛是容量耗尽时仍会遗忘。
arxiv.org/abs/2605.26097 机器学习 人工智能 论文 AI创造营