一家自研RDMA,一家还在吃老本,两家的网络方案差距有点大
刷到一篇分析,说大模型训练中网络通信耗时占比高达30%到50%。一万张卡协同干活,通信一旦卡住,算力再强也得干等。大规模集群真正的瓶颈不在单卡,在把卡连起来的网络上。
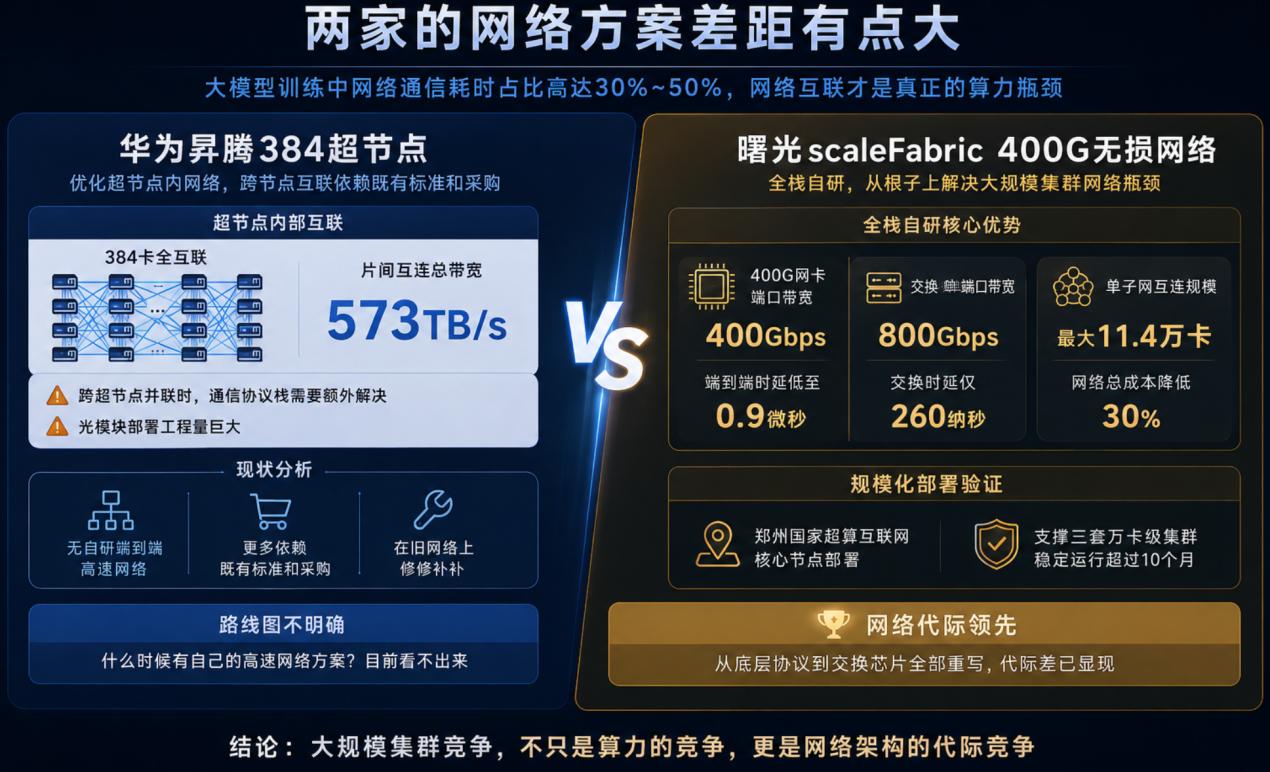
在这个维度上拉了两家对比。
华为昇腾384超节点内部采用灵衢高速互联优化得不错,片间互连总带宽573TB/s,超节点内384卡全互联。但跨超节点并联时,通信协议栈需要额外解决,光模块部署工程量巨大。华为目前没有自研的端到端高速网络,在网络互联这一块更多依赖于既有标准和采购。
曙光走了一条从根子上解决的问题路径。3月发布了首款全栈自研400G无损高速网络scaleFabric,网卡端口带宽400Gbps,端到端通信时延低至0.9微秒;交换机单端口带宽800Gbps,交换时延仅260纳秒。单子网互连规模可支持最大11.4万卡集群部署,网络总成本还能降低30%。这套网络已在郑州国家超算互联网核心节点部署,支撑三套万卡级集群稳定运行超过10个月。
一边是在旧网络上修修补补,一边是把网络从底层协议到交换芯片全部重写。华为什么时候有自己的高速网络方案?目前路线图上看不出来。但曙光这套方案跑起来之后,网络上的代际差已经摆在眼前了。