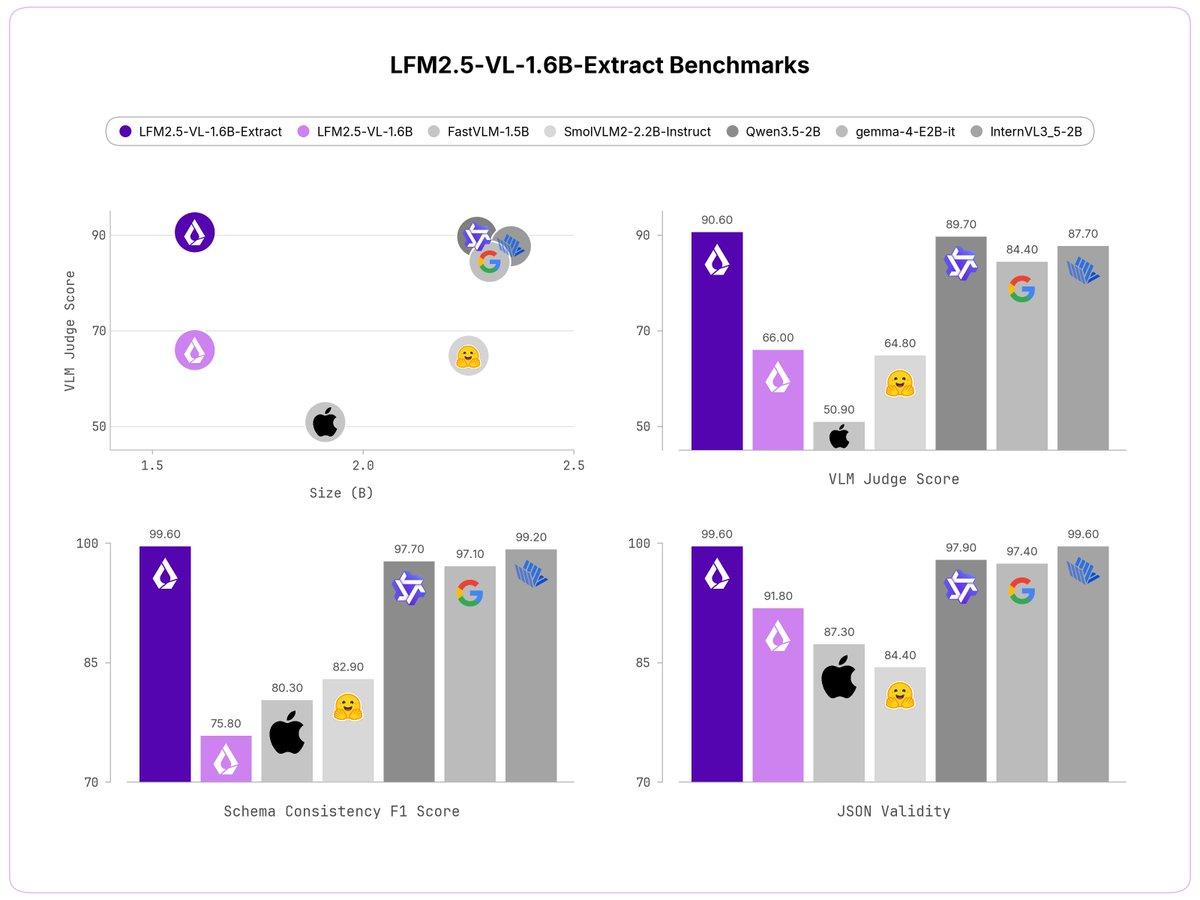
Liquid AI推出了两款视觉语言模型(LFM2.5-VL-1.6B-Extract 和 LFM2.5-VL-450M-Extract),核心亮点是原生输出结构化JSON,而非自由文本。用户传入图像 + 自定义字段列表(如“仪表盘显示的时间”“场景中人数”“发票总额”),模型直接返回填充好的干净JSON对象。
模型开源权重、提供1.6B和450M两种尺寸,支持在任意设备SoC上运行,特别适合需要可靠结构化输入的下游管道,如车内舱室理解、文档扫描、工业检测等。相比传统视觉模型,它省去了中间解析步骤,大幅简化集成。