但最近 DeepSeek 等团队使用的 Muon(μon)优化器 展现出了惊人的威神力,在相同模型规模下,它能让 LLM 的预训练速度提升近 2 倍!
耶鲁大学Zhuoran Yang教授团队与NUS团队发布的新作《Why Muon Outperforms Adam: A Curvature Perspective》从优化曲率(Curvature)的底层数学视角,揭开了最近在 LLM 圈(尤其是 DeepSeek、Kimi 等顶尖大模型)里大火的 Muon 优化器为什么能把 Adam 吊打的秘密。
🔆 核心发现(通过二阶 Taylor 展开分析)
🔸 一阶收益相似:Muon 和 Adam 在梯度对齐(第一阶损失下降)上表现接近。
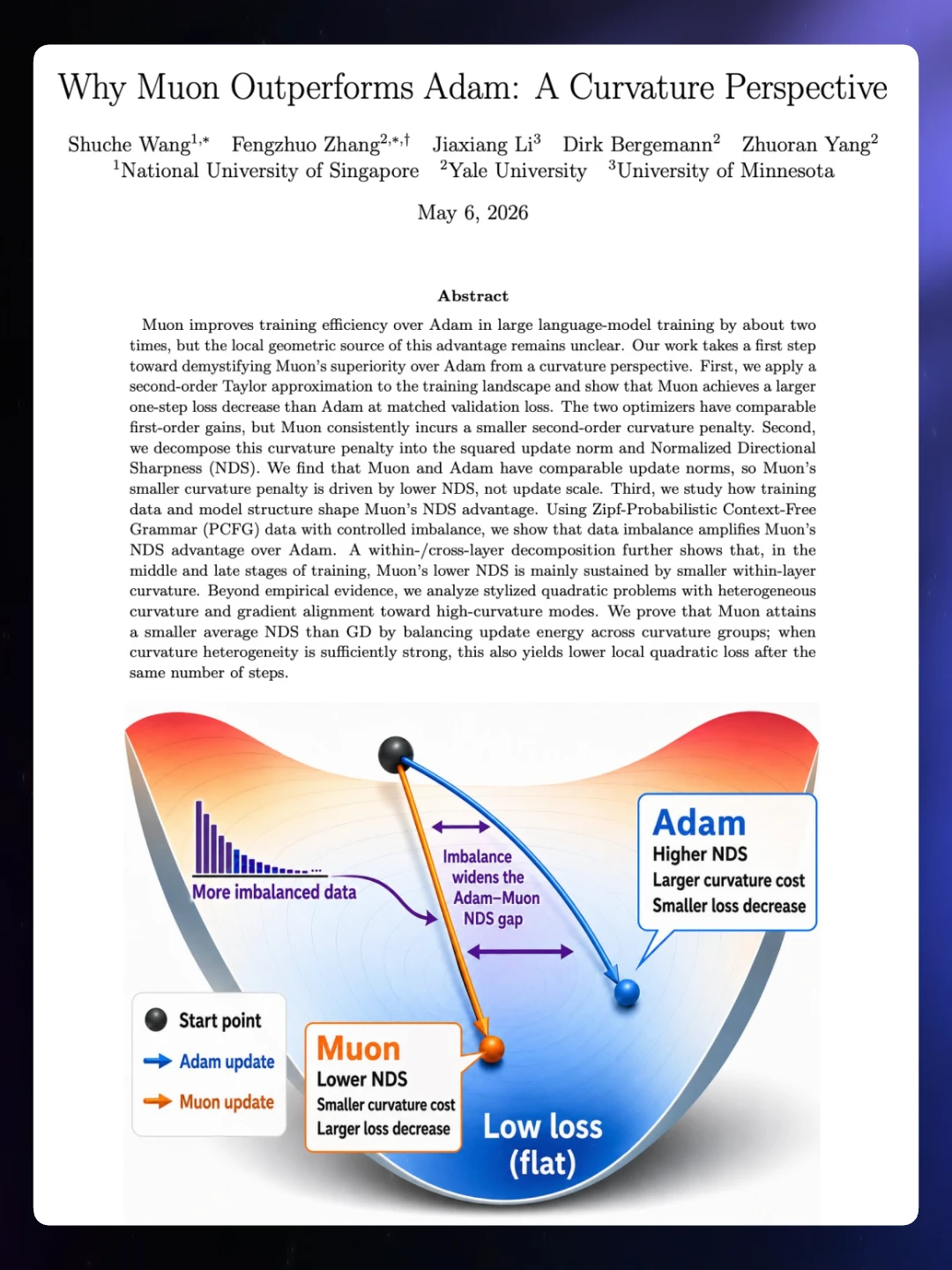
🔸 二阶曲率惩罚更小:Muon 的更新方向导致更低的Normalized Directional Sharpness (NDS),即在相同更新范数下,它“踩”在景观更平坦的方向上,曲率代价显著更低,从而实现更大的单步损失下降。
🔸 数据不平衡放大优势:使用可控的 Zipf-PCFG 合成数据实验显示,训练数据越不平衡(长尾越明显),Muon 在 NDS 上的优势就越大。这解释了为什么它特别适合真实 LLM 预训练的长尾分布。
🔸 模型结构分解:进一步拆解网络 NDS 为层内(within-layer)和跨层(cross-layer)部分,发现训练中后期 Muon 的优势主要来自更低的层内曲率。
论文还通过异质曲率二次模型提供了理论证明:在梯度倾向高曲率方向时,Muon 通过平衡不同曲率组的更新能量,实现了更低的平均 NDS 和更好的损失下降。
这波从曲率视角的降维打击,真的让人不得不服!
强烈推荐给做 LLM 预训练、优化器、长尾数据训练的同学,这篇值得读。
原作:arxiv.[赞R]org/abs/[赞R]2606.04662