我们正处在一个由人工智能重塑千行百业的宏大叙事之中。国家顶层设计的东风正劲,自2025年政府工作报告首次将“支持大模型广泛应用”写入纲领 到《关于深入实施“人工智能+”行动的意见》(国发〔2025〕11号)的全面铺开再到工信部今年力推的《“人工智能+制造”专项行动实施意见》 ,政策的清晰指向与产业的迫切需求形成了强烈的“模数共振” 。工业,作为国民经济的基石,无疑是这场智能化变革的主战场。
然而,当通用大模型的万丈光芒照进结构复杂、机理精密的工业车间时,我们发现了一道现实的鸿沟。通用大模型如同一个博闻强识的“通才”,虽能引经据典,却难以胜任需要深厚领域知识和绝对确定性的工业任务。工业大模型的落地,并非简单的模型“应用”,而是一场深刻的演进——从庞大而泛化的通用底座,向轻量、精准、内嵌行业智慧的专用模型演进。这条路径的核心,正是“行业知识蒸馏”。
一、 通用大模型的“理想”与工业应用的“现实鸿沟”通用大模型以其强大的自然语言理解、逻辑推理和内容生成能力,为工业智能化描绘了广阔的蓝图。理论上,它可以赋能研发设计、生产制造、运营管理等全价值链环节。但实践中,我们必须正视三大核心挑战,这也是通用模型在工业领域必须跨越的“现实鸿沟”:
知识的“水土不服”:工业知识具有高度的专业性、情境性和隐性特征。它不仅包括成文的工艺手册、设计规范,更包含了大量存在于资深专家脑海中的经验诀窍 。通用大模型在预训练阶段接触的公共语料,与这些深度的、结构化的工业知识体系存在巨大差异,导致其在面对具体工业问题时,回答往往“失之毫厘,谬以千里” 。
数据的“孤岛与贫瘠”:工业场景的数据呈现“多模态、小样本、高噪声”的特点。传感器数据、生产过程数据、设备状态数据等格式各异,且常常深锁于不同的业务系统中,形成数据孤岛 。更重要的是,与互联网海量标注数据不同,高质量的工业标注数据极其稀缺,这使得模型的训练和微调面临“无米之炊”的困境 。
决策的“幻觉风险”:工业生产要求的是高可靠性、高稳定性和确定性的决策。然而,大模型的底层逻辑是概率生成,其固有的“幻觉”问题 在消费娱乐领域或许无伤大雅,但在控制生产线、预警安全事故等严肃场景下,任何不确定的输出都可能导致巨大的经济损失甚至安全风险 。工业需要的不是一个“可能正确”的顾问,而是一个“绝对可靠”的专家。
二、 破局之路:从“知识加法”到“知识蒸馏”的范式转变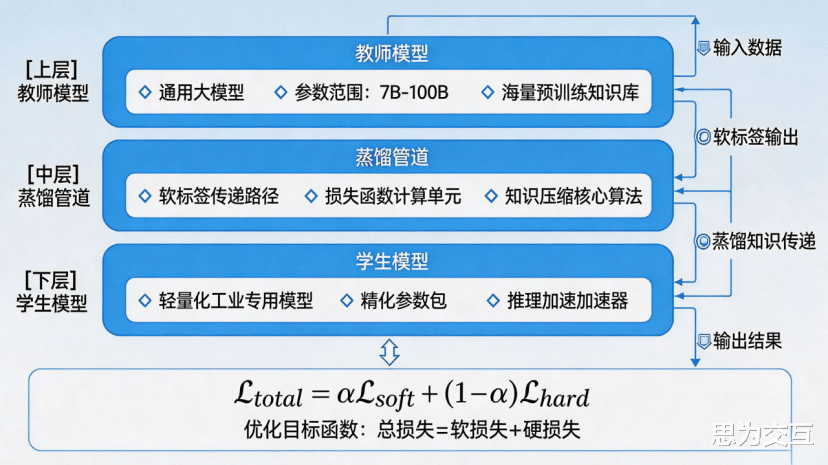
面对上述鸿沟,业界最初的探索路径是做“加法”——通过外挂知识库(如RAG)或利用有限的行业数据进行微调 。这在一定程度上缓解了知识不足的问题,但并未从根本上改变模型的“外行”内核。模型依然庞大、推理成本高昂,且知识的融合是浅层的、后置的。
真正的破局,需要一场从“加法”到“蒸馏”的范式转变。
“知识蒸馏”(Knowledge Distillation),其核心思想是将一个更大、更复杂的“教师模型”(通常是通用大模型)所拥有的丰富知识和强大能力,通过特定的技术手段,传递并浓缩到一个更小、更高效的“学生模型”中 。在工业领域,这不仅仅是模型尺寸的压缩,更是一场深刻的知识重构与内化过程。它标志着我们不再满足于让通用模型“学会”工业知识,而是致力于创造一个“原生”于工业环境的智能体。
这场演进的实现依赖于三大技术支柱的协同:
构建工业知识图谱与向量知识库:这是“蒸馏”的原料。我们需要将散落在设备手册、工艺文件、专利文献以及专家经验中的隐性与显性知识,系统性地构建成机器可理解的知识图谱和向量库 。这相当于为“学生模型”编写了一套结构化、高质量的专业“教材”,从源头上保证了知识的准确性和深度。
融合“机理+数据”的双轮驱动模式:纯数据驱动的方法在工业领域存在局限性。未来的工业大模型必须是“机理+数据”双轮驱动 。我们将物理定律、化学反应机理、控制理论等行业第一性原理,作为强约束融入模型训练过程。这不仅能极大提升模型的预测精度和鲁棒性,还能使其具备更好的可解释性,摆脱“黑箱”困境。
两阶段微调与持续领域适应框架:知识的内化并非一蹴而就。我们采用先进的两阶段微调框架:第一阶段,使用工业知识图谱和机理模型对模型进行“知识锚定”,让其建立起对行业核心概念和逻辑的认知 ;第二阶段,再结合具体的场景数据进行“能力培养”,训练其解决实际问题的推理和决策能力。这是一个持续学习、不断进化的过程,确保模型能适应工艺的迭代和产线的变化。
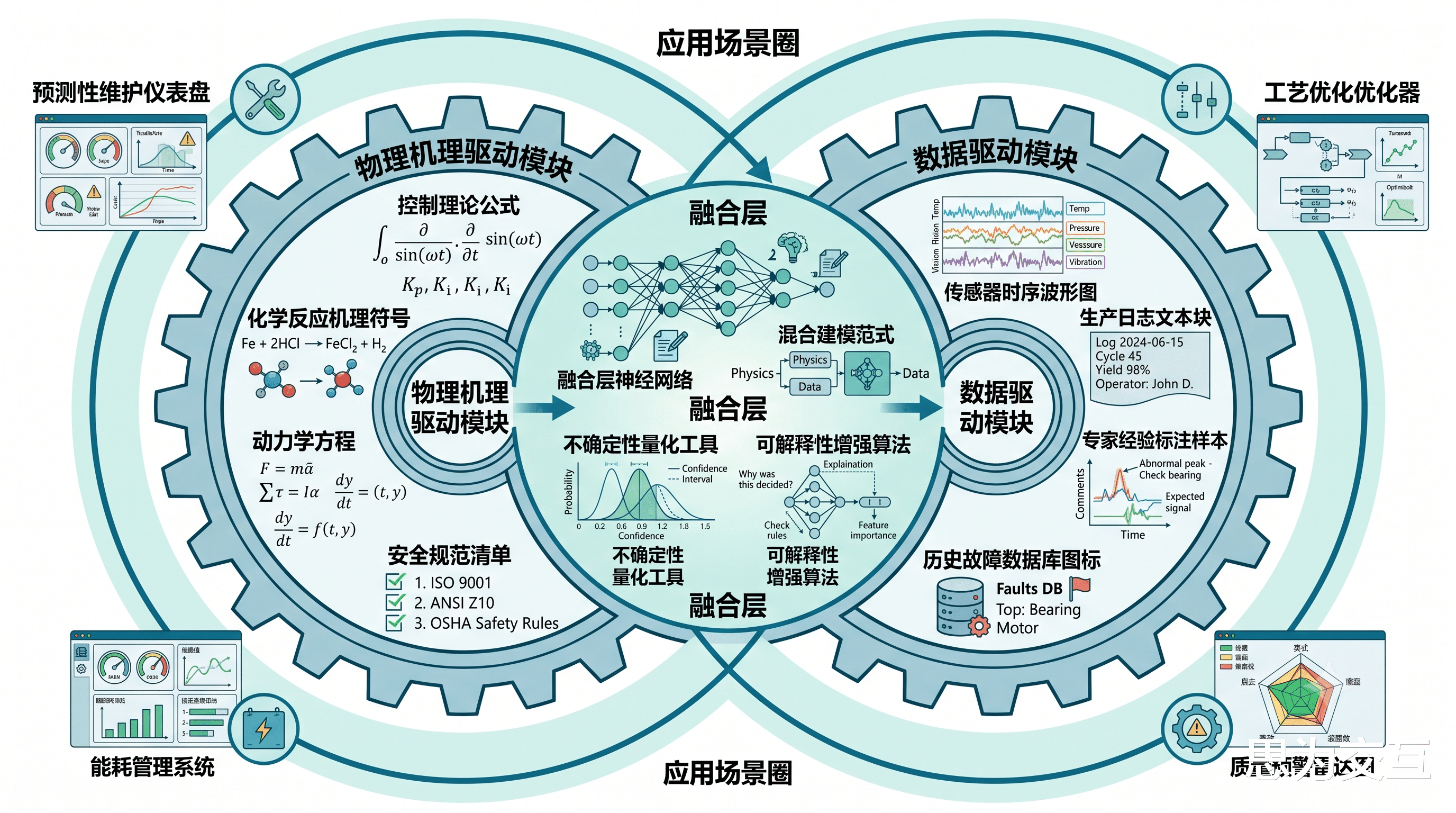
通过这一系列“蒸馏”过程,最终得到的行业专用模型,不仅在体量上更轻量化,易于在边缘端部署,更重要的是,它在“思想”上完成了从通用认知到行业智慧的蜕变,其决策逻辑与行业机理深度耦合,从而在准确性、可靠性和效率上实现质的飞跃。
三、 政策护航与生态共建:加速工业知识的“价值闭环”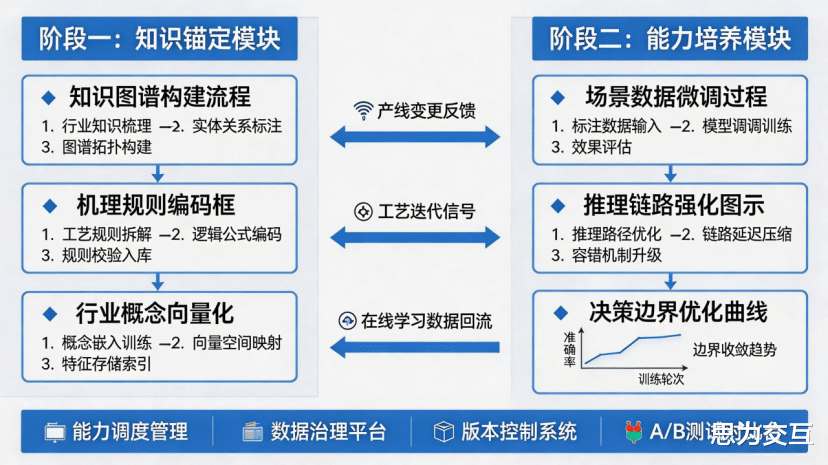
这场从通用到底座,再到知识蒸馏的演进,离不开宏观政策的战略牵引和产业生态的协同共建。国家大力推动的“数据要素×”三年行动计划 正在盘活工业数据的价值,而新设立的国家人工智能产业投资基金 则为核心技术研发提供了强有力的资金支持。各地政府,如北京、上海、广东等地,也纷纷出台政策,鼓励多模态大模型在垂直领域的创新应用 。
在政策的护航下,一个涵盖数据治理、算法创新、算力支持、标准制定和场景应用的完整生态正在形成 。
结语工业大模型的落地之路,是一条从“博”到“专”、从“重”到“轻”、从“通用智能”到“嵌入式智慧”的清晰演进路线。其核心不在于无止境地堆叠参数,而在于如何高效、精准地将人类数百年积累的工业知识“蒸馏”并注入到新一代的智能引擎中。